Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Déploiement en un clic de Chatterbox TTS
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
The authors comprehensively evaluate self-supervised speech representations for spontaneous text-to-speech synthesis and quality prediction by comparing six SSL models across three layers each, extending a read-speech MOS prediction framework to unscripted utterances, and testing both approaches across two distinct spontaneous corpora to establish generalizable trends for spontaneous speech synthesis and MOS prediction.
Key Contributions
- This work systematically evaluates six self-supervised learning speech models across three internal layers each to identify optimal intermediate acoustic representations for two-stage spontaneous text-to-speech synthesis.
- The study adapts a pre-existing SSL-based framework to automatically predict mean opinion scores for synthesized spontaneous speech, extending prior quality assessment methods originally designed for read speech.
- Experiments conducted across two independent spontaneous corpora establish generalizable trends, quantifying how specific model architectures and layer selections directly impact synthesis fidelity and automated quality prediction.
Introduction
Self-supervised learning models yield robust speech representations trained on massive unlabelled datasets, offering significant advantages for text-to-speech synthesis and quality assessment. Such features enable TTS systems to manage mixed-quality audio and model complex prosodic patterns, which is essential for generating natural spontaneous speech containing disfluencies and breathing sounds that challenge conventional approaches. Prior studies largely concentrate on read speech and fail to identify optimal SSL architectures or internal layers for spontaneous synthesis, leaving a critical gap in understanding model selection for this domain. Furthermore, while SSL models show promise in predicting mean opinion scores for read speech, their utility for evaluating the quality of synthesized spontaneous output has not been investigated. The authors bridge these gaps by systematically comparing six SSL models across three internal layers to optimize spontaneous TTS performance and extend an SSL-based framework to predict mean opinion scores for spontaneous synthesis. Experiments across two spontaneous corpora provide generalizable insights into leveraging SSL representations for more human-like conversational voice systems.
Dataset
-
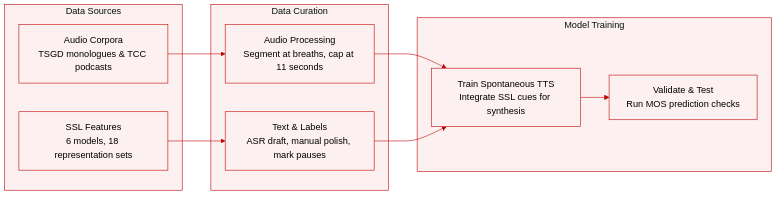
Dataset Composition & Sources The authors construct their dataset using two spontaneous speech corpora and six speech self-supervised learning (SSL) models. The audio data originates from the Trinity Speech-Gesture Dataset (TSGD) Part 1 and the public-domain ThinkComputers Corpus (TCC). The model features are drawn from four pre-trained SSL architectures and two official ASR fine-tuned variants.
-
Subset Details
- TSGD: 25 monologues averaging 10.6 minutes each, featuring a male Hiberno English speaker delivering impromptu, colloquial talks to a silent, visually present audience.
- TCC: Approximately 9 hours of podcast audio featuring two male American English speakers discussing technology extemporaneously around prepared outlines.
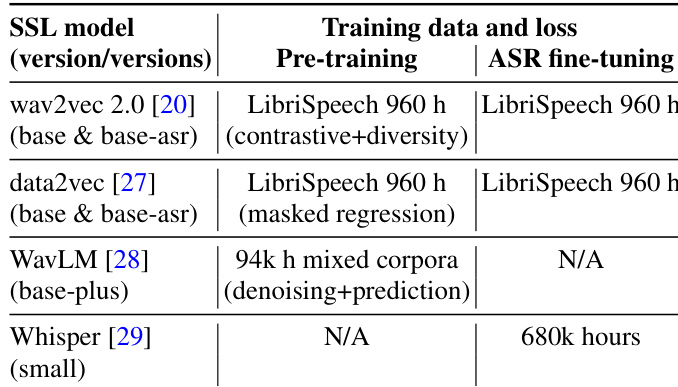
- SSL Representations: All six models share identical specifications (765-dimensional output, 12 transformer layers, 50 Hz frame rate). Features are extracted from layers 6, 9, and 12 to capture prosodic cues, yielding 18 distinct representation sets.
-
Processing & Cropping Strategy
- Both corpora are segmented at natural breath events and recombined in an overlapping fashion to generate utterances strictly capped at 11 seconds.
- Transcriptions are generated via automatic speech recognition and manually refined. Filled pauses, laughter, and discourse markers are written out orthographically. Breath events are annotated with semicolons, standard pauses with commas, and non-lexical sounds like tongue clicks are omitted.
-
Usage in the Model
- The processed audio and SSL features are used to train spontaneous TTS systems and evaluate mean opinion score (MOS) prediction tasks.
- The authors integrate the SSL representations directly into the synthesis pipeline, relying on middle-layer outputs for optimal prosodic control.
- Mel-spectrogram baselines are excluded from all comparisons due to established inferior performance in spontaneous TTS settings.
Method
The authors leverage a two-stage framework for text-to-speech (TTS) synthesis, where the first stage generates acoustic features from input text and the second stage converts these features into high-quality waveforms. As shown in the figure below, the system begins with a stage-1 acoustic model, specifically FastPitch 1.1, which processes textual input to produce mel-spectrograms. This model is trained in a parallel manner with automatic alignment, enabling efficient learning of the text-to-acoustic mapping without requiring explicit alignment annotations. The stage-1 model is first pre-trained on the read-speech corpus LJ Speech for 200 epochs and then fine-tuned on spontaneous speech corpora using transfer learning, which enhances its ability to generalize to less structured speech data.
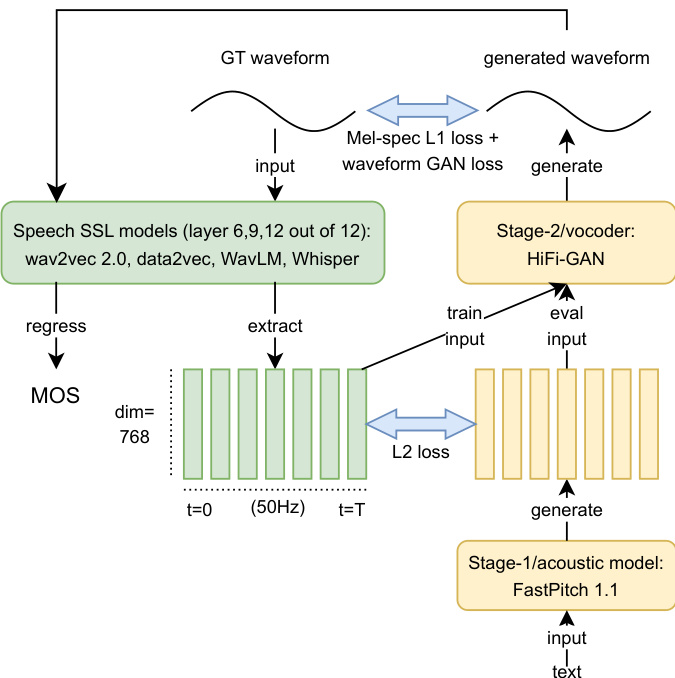
Following the generation of mel-spectrograms, the stage-2 vocoder, HiFi-GAN, synthesizes the final waveform from these acoustic features. The vocoder is trained with a batch size of 160, using 0.5-second random audio excerpts, and operates at the original 22 kHz sampling rate. During training, the model minimizes both mel-spec L1 loss and waveform GAN loss to ensure perceptual quality and fidelity to the ground-truth waveform. The stage-2 models are trained for 80k steps across 36 configurations, corresponding to 18 different speech SSL representations derived from two spontaneous corpora.
Additionally, the authors incorporate a MOS-prediction system to evaluate synthesized speech quality. This system is based on a wav2vec 2.0 base model with a mean-pooling head and a linear projection to predict a scalar MOS value. The architecture is adapted from prior work, with the authors exploring various weight initializations and training-data splits to assess performance on spontaneous speech synthesis, while maintaining a fixed model structure. The MOS prediction is performed on the output of the stage-1 model, where speech SSL features are extracted and regressed to predict the MOS score.
Experiment
This study evaluates six self-supervised speech models across multiple network layers within a two-stage text-to-speech pipeline, validating their acoustic fidelity through vocoder reconstruction tests, their perceptual quality through subjective listening sessions, and their generalization capabilities through automated quality prediction. The experiments reveal that intermediate representations, particularly from the ninth layer of ASR-fine-tuned models, consistently yield the highest perceived audio quality, whereas deeper layers degrade synthesis performance. Crucially, subjective quality shows no correlation with vocoder reconstruction error, highlighting a fundamental trade-off between the acoustic richness of a representation and its predictability from text. Finally, automated MOS prediction proves ineffective in zero-shot settings, demonstrating that fine-tuning on spontaneous speech data is essential for reliable quality assessment.
The authors compare various self-supervised speech representations in two-stage text-to-speech systems, evaluating their performance through vocoder error and subjective listening tests. Results show that intermediate layers, particularly layer 9, yield better TTS quality than deeper or shallower layers, and ASR fine-tuning improves performance despite increasing vocoder error, indicating a trade-off between acoustic information and prediction accuracy. The best-performing model combines data2vec with ASR fine-tuning and layer 9 representations, achieving high subjective quality despite not having the lowest vocoding error. Layer 9 of SSL models consistently outperforms layer 6 and layer 12 in subjective TTS quality across different models and corpora. ASR fine-tuning improves TTS quality but increases vocoder error, indicating a trade-off between acoustic fidelity and text-to-representation prediction accuracy. Whisper achieves the lowest vocoder error but underperforms in TTS quality, suggesting that high acoustic information content does not necessarily lead to better perceived speech quality.
The authors evaluate SSL representations for spontaneous TTS and MOS prediction, analyzing performance across different models, layers, and fine-tuning strategies. Results show that layer 9 representations generally yield better subjective TTS quality than deeper or shallower layers, and that fine-tuning improves MOS prediction accuracy, though zero-shot performance remains poor. The study highlights a trade-off between acoustic information in representations and their predictability from text. The trends in TTS quality and vocoding error are not aligned, indicating that lower error does not necessarily lead to better perceived quality. Layer 9 representations consistently achieve better subjective TTS quality than deeper or shallower layers across multiple SSL models. Fine-tuning SSL models improves MOS prediction performance, with fine-tuned wav2vec2.0-base-asr showing competitive results. There is no correlation between vocoding error and perceived TTS quality, indicating a trade-off between acoustic fidelity and text-to-speech predictability.
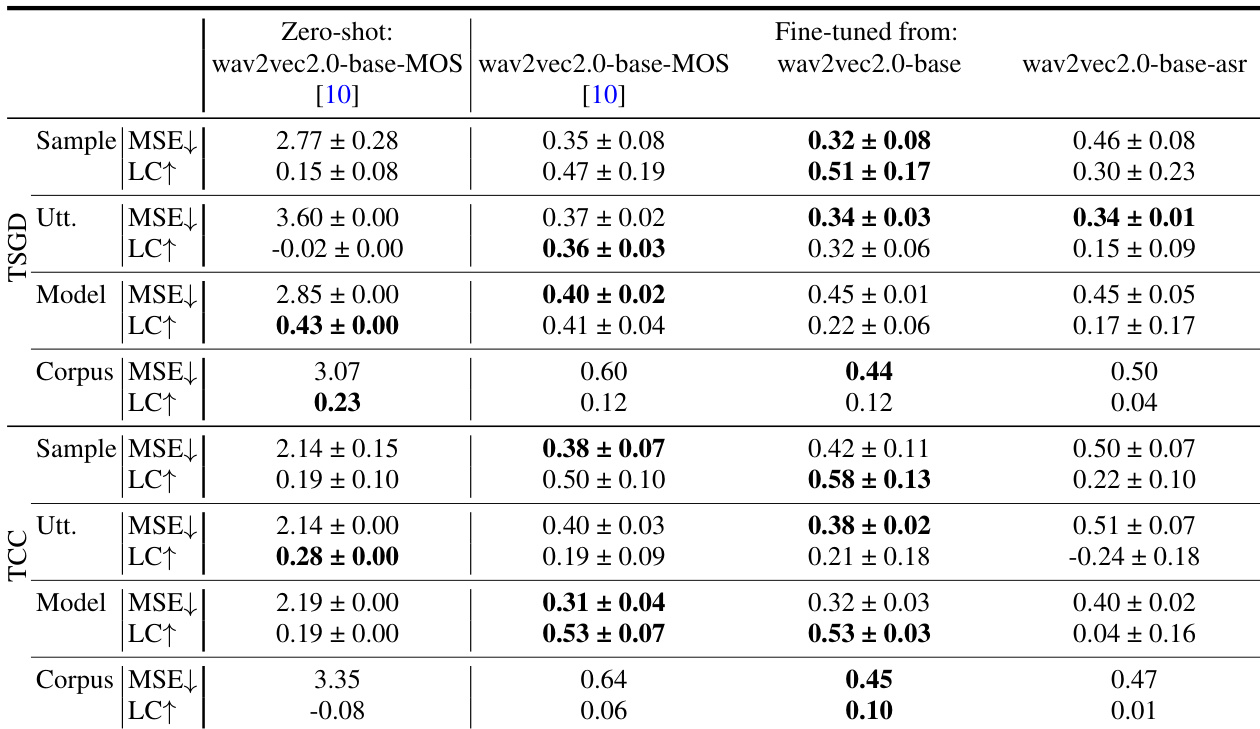
The authors evaluate self-supervised speech representations in two-stage text-to-speech systems across different layers and models, analyzing both subjective quality and vocoder error. Results show that intermediate layers, particularly layer 9, yield better subjective quality than deeper or shallower layers, and that ASR fine-tuning improves performance despite higher vocoder errors, indicating a trade-off between acoustic fidelity and predictability from text. The best-performing system combines data2vec with ASR fine-tuning at layer 9, achieving high subjective quality on both corpora. Layer 9 consistently outperforms layer 6 and layer 12 in subjective TTS quality across multiple SSL models. ASR fine-tuning improves subjective TTS quality but increases vocoder error, indicating a trade-off between acoustic information and text predictability. The best-performing system combines data2vec with ASR fine-tuning at layer 9, achieving high subjective quality on both corpora.
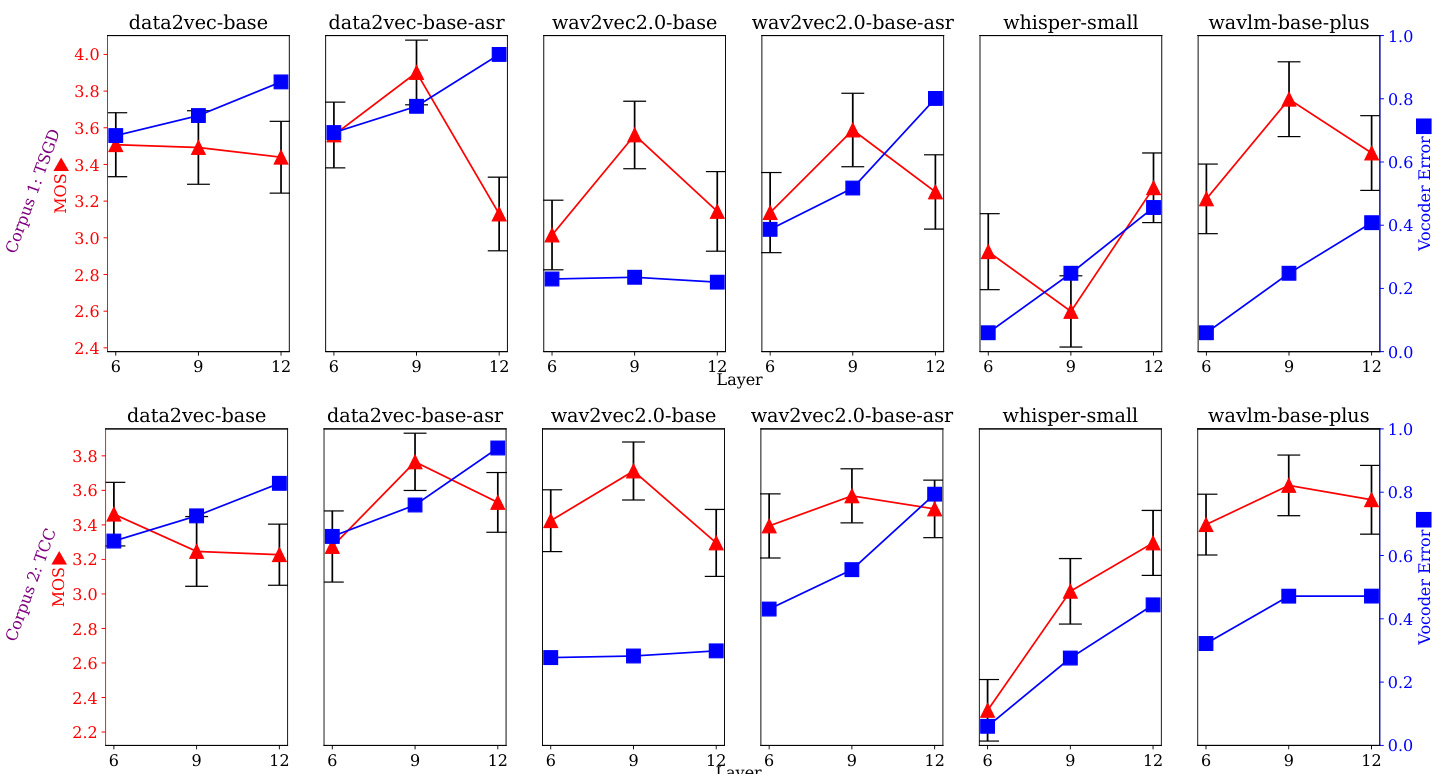
The experiments evaluate various self-supervised speech representations within two-stage text-to-speech systems by validating the impact of network layer depth and acoustic speech recognition fine-tuning through subjective listening tests and vocoder error metrics. Results consistently demonstrate that intermediate layers deliver superior perceived speech quality, while fine-tuning enhances human ratings despite increasing reconstruction error, underscoring a fundamental trade-off between acoustic fidelity and text predictability. These findings reveal that objective error metrics do not reliably align with listener perception, establishing that carefully selected intermediate representations combined with targeted fine-tuning yield the most natural synthetic speech.