Command Palette
Search for a command to run...
Moderniser les anciennes photos en utilisant plusieurs références via un transfert de style photoréaliste
Moderniser les anciennes photos en utilisant plusieurs références via un transfert de style photoréaliste
Agus Gunawan Soo Ye Kim Hyeonjun Sim Jae-Ho Lee Munchurl Kim
Restauration en un clic de vieilles photos (FLUX.1 + LivePortrait)
Résumé
Cet article présente d'abord la modernisation de vieilles photos à l'aide de multiples références, en réalisant stylisation et amélioration de manière unifiée. Afin de moderniser les vieilles photos, nous proposons un nouveau cadre de modernisation de vieilles photos basé sur plusieurs références (MROPM), composé d'un réseau MROPM-Net et d'un schéma novateur de génération de données synthétiques. MROPM-Net stylise les vieilles photos à l'aide de multiples références via un transfert de style photoréaliste (PST), puis améliore les résultats afin de produire des images au look moderne. Parallèlement, le schéma de génération de données synthétiques permet d'entraîner le réseau à utiliser efficacement les multiples références pour réaliser la modernisation. Pour évaluer les performances, nous proposons un nouvel ensemble de données de référence pour les vieilles photos (CHD), composé de scènes naturelles variées, tant intérieures qu'extérieures. Des expériences approfondies montrent que la méthode proposée surpasse les autres méthodes de référence dans la modernisation de vraies vieilles photos, même si aucune vieille photo n'a été utilisée lors de l'entraînement. De plus, notre méthode peut sélectionner de manière appropriée les styles parmi les multiples références pour chaque région sémantique de la vieille photo, améliorant ainsi davantage les performances de modernisation.
One-sentence Summary
This paper introduces MROPM-Net, a multi-reference photorealistic style transfer framework that unifies stylization and enhancement by leveraging a novel synthetic data generation scheme to selectively apply reference styles to semantic regions without training on real old photos, thereby outperforming existing baselines on the newly introduced CHD benchmark.
Key Contributions
- The MROPM-Net framework unifies photorealistic style transfer and image enhancement to modernize old photographs using multiple reference images. This architecture enables local stylization across diverse semantic regions without relying on semantic segmentation masks or slow optimization procedures.
- A novel synthetic data generation scheme trains the network to effectively aggregate styles from multiple references, establishing the first end-to-end implementation of multi-style photorealistic style transfer. The model automatically selects appropriate reference styles for each semantic region to ensure comprehensive coverage.
- The CHD benchmark dataset is introduced to standardize evaluation across diverse natural indoor and outdoor scenes. Extensive experiments demonstrate that the proposed method outperforms existing baselines on real old photographs despite being trained exclusively on synthetic data.
Introduction
Preserving cultural heritage often requires restoring and modernizing aged photographs that suffer from structural damage and color fading. While prior research has explored automated restoration and single-reference colorization, these approaches struggle to capture the complex semantics of natural scenes and frequently leave images with outdated sepia tones or rely on unreliable GAN-generated references. The authors leverage photorealistic style transfer to propose a unified framework that modernizes old photographs by integrating multiple contemporary reference images. This approach eliminates the need for semantic segmentation during local stylization and employs a synthetic data training strategy that enables the model to generalize to real historical images without ever seeing them during training. To support this work, they also introduce a new benchmark dataset containing 644 indoor and outdoor heritage photographs.
Dataset
-
Dataset Composition and Sources: The authors introduce the Cultural Heritage Dataset (CHD), comprising 644 old color photographs from the 20th century. These images were originally captured on reversal films or paper and sourced from three Korean national museums: the National Museum of Korea, Gimhae National Museum, and Jeju National Museum. The collection features diverse indoor and outdoor cultural heritage scenes, including special exhibitions and excavation ruins, exhibiting varying degrees of color fading, blur, and noise alongside minimal scratches or cracks.
-
Subset Details and Filtering: After initial collection, the authors filter out images containing sensitive elements such as recognizable faces or license plates. The remaining photographs are randomly divided into an 8:2 ratio, yielding 514 training images and 130 test images while preserving the proportional distribution from each museum. The training subset contains real degraded photographs, whereas the test subset serves as the evaluation benchmark for the proposed task.
-
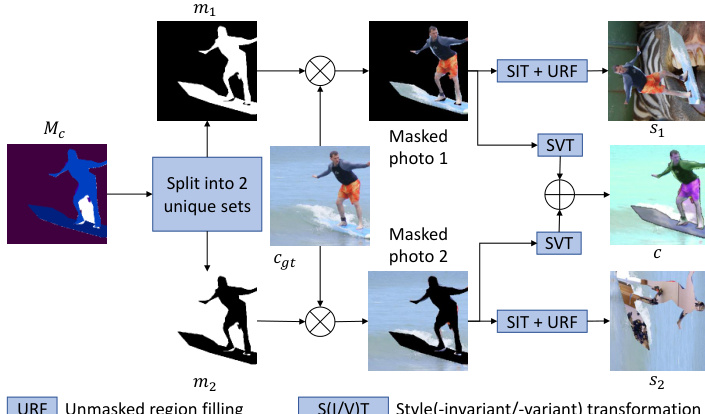
Data Usage and Reference Construction: The training split is exclusively used to develop baseline restoration models that require real old photographs to bridge the domain gap between synthetic and real data. The test split drives the reference-based modernization task, where each degraded image is paired with one or two manually curated modern reference photos. The authors crawl CC-licensed images with matching contexts from the web, but discovered that automated selection methods based on VGG-19 feature similarity or BRISQUE scores consistently picked hazy, old-style images instead of modern ones. Manual curation was therefore required, and the dataset only provides web links and attributions for the references rather than the images themselves.
-
Cropping, Metadata, and Augmentation: All scanned images, originally captured at 4K to 8K resolutions, are resized so the shortest dimension reaches 1024 pixels, followed by a center crop to a uniform 1024 by 1024 size. This same preprocessing pipeline is applied to both the old photographs and their modern references. For baseline training, the authors generate synthetic degraded variants using style variant transformations, including color jittering and randomized unstructured degradations like Gaussian blur, speckle noise, resizing artifacts, and JPEG compression. These are combined with style invariant augmentations such as random rotations, translations, and flips to improve model robustness.
Method
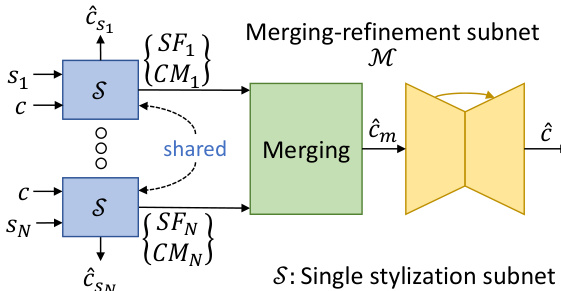
The proposed method, MROPM-Net, employs a dual-subnet architecture to achieve multi-reference-based old photo modernization. The framework consists of a shared single stylization subnet S and a merging-refinement subnet M. Given an old photo input c and N modern photo references s={si}i=1N, the process begins with S, which is built upon a photorealistic style transfer (PST) backbone. This subnet independently stylizes c using each reference si to generate N stylized features SFi and corresponding correlation matrices CMi. The correlation matrices capture the semantic similarity between the content and style, which are then used in the merging-refinement subnet M to produce the final modernized output. The overall framework is illustrated in the following diagram.
The single stylization subnet S is designed to perform local and global style transfer without requiring semantic segmentation. Its architecture, shown below, is composed of two main parts: an improved PST network and a style code predictor. The PST network is based on a pre-trained encoder θenc that extracts feature maps Fck from the old photo c and Fsik from the reference si. The network is modified from the WCT2 architecture to address its limitations, such as the "short circuit" issue where stylization only affects the last decoder block. To overcome this, the authors transfer only a single high-frequency component in the level-0 of the Laplacian pyramid representation, rather than three components as in WCT2. The stylization is applied exclusively to the decoder part, specifically the last two decoder blocks, to achieve an optimal balance between photorealism and style transfer effectiveness. Furthermore, the network uses differentiable adaptive instance normalization (AdaIN) instead of the non-differentiable WCT transformation, enabling the learning and prediction of local styles.
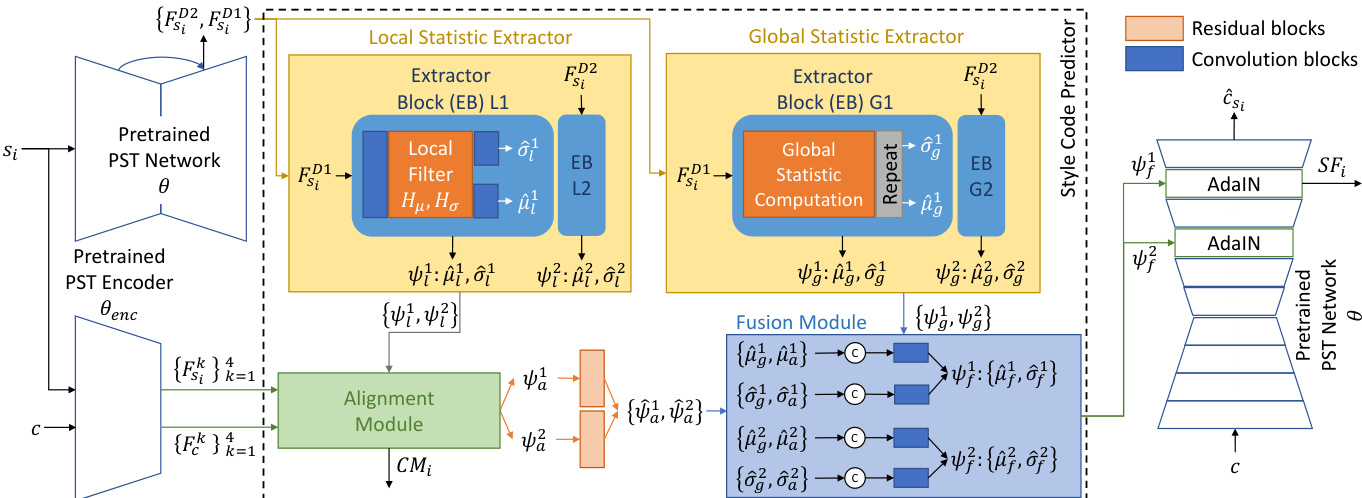
The style code predictor within S is responsible for generating the style codes ψ={μ,σ}, which consist of mean and standard deviation values for the AdaIN operation. This predictor is composed of two extractors: a local statistic extractor and a global statistic extractor. The local extractor processes the last two decoder blocks (j=1,2) of the pre-trained PST network to obtain local style codes ψlj={μ^lj,σ^lj} using a local mean filter Hμ and local std filter Hσ with a kernel size of 3, followed by convolution blocks. The global extractor computes channel-wise mean and standard deviation values for the same levels, which are then spatially repeated. The local and global codes are then aligned to the content c using non-local attention. This alignment is performed by first mapping the feature maps of c and si into the same feature space, computing a correlation matrix CMi via matrix multiplication, and then using this matrix to align the local style codes ψlj to c. The aligned style codes ψaj are refined through residual blocks to mitigate interpolation artifacts. Finally, the refined local style codes ψ^aj are fused with the global style codes ψgj using a fusion module, which performs channel-wise concatenation followed by convolution, to produce the final fused style code ψfj. These fused codes are then used in the PST network to stylize c and generate the stylized feature SFi.
The merging-refinement subnet M takes the N stylized features {SFi}i=1N and their corresponding correlation matrices {CMi}i=1N as input. The merging process is designed to select the most appropriate style for each semantic region from the multiple stylization results. This is achieved using a spatial attention module (SAM) that computes attention weights Wisa for each SFi based on the correlation matrix CMi. The weights are normalized using Softmax to obtain Wnorsa, which are then used to weight the stylized features. The weighted features are summed to produce an intermediate merging image c^m. This process is detailed in the following diagram.
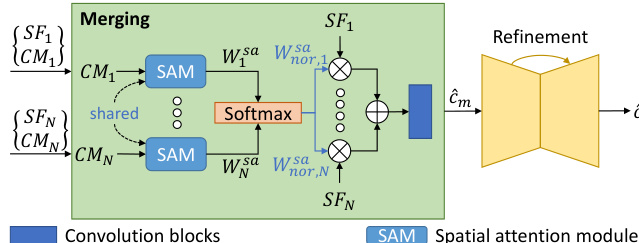
The intermediate result c^m is further refined by a U-Net-based refinement subnet to produce the final modernized image c^. The refinement subnet follows the U-Net architecture, with an encoder and decoder structure. The encoder consists of a sequence of convolutional blocks: C64−C128−C256−C512−C512−C512−C512, where C denotes a convolutional layer. The decoder follows a corresponding structure: CD512−CD512−CD512−CD256−CD128−CD64. Leaky ReLU activation functions with a slope of 0.2 are used in the encoder, while ReLU activation functions are used in the decoder. The final output is generated by a single convolution layer followed by a Tanh activation function to map the features to the RGB color space. Instance normalization layers are applied throughout the U-Net architecture.
Experiment
The proposed method is evaluated on synthetically degraded and real-world old photos against sequential and state-of-the-art reference-based baselines, validating its capacity to jointly stylize and enhance images using single or multiple references. Qualitative assessments and ablation studies demonstrate that the network effectively leverages adaptive attention mechanisms to select and transfer appropriate styles from multiple references to corresponding semantic regions, while the integrated loss functions and merging-refinement subnet ensure smooth, artifact-free modernization that purely restoration-based approaches cannot achieve. User studies and additional robustness tests confirm that the framework consistently produces naturally modernized outputs across diverse scenarios, including unrelated references, greyscale inputs, and severe degradations, ultimately proving that combining targeted style transfer with enhancement yields superior real-world performance without requiring training on actual old photographs.
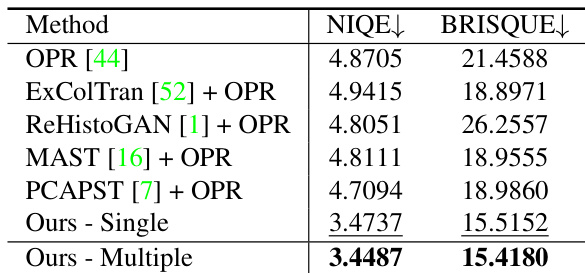
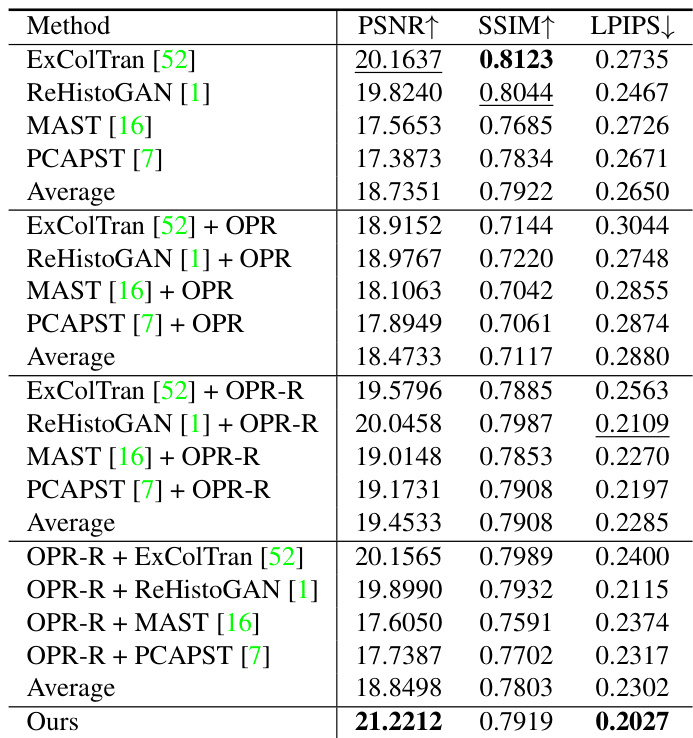
The authors compare their method against several baselines in a quantitative evaluation, using metrics such as PSNR, SSIM, and LPIPS. Their method achieves the highest PSNR and the lowest LPIPS, indicating superior performance in both pixel-level accuracy and perceptual quality. In terms of SSIM, their method ranks second, suggesting strong structural preservation. The results demonstrate that their approach outperforms existing methods in modernizing old photos by effectively combining stylization and enhancement. The proposed method achieves the highest PSNR and the lowest LPIPS among all compared methods. The method ranks second in SSIM, indicating strong structural preservation compared to baselines. The method outperforms baselines in both synthetic and real-world photo evaluations, demonstrating robust performance.
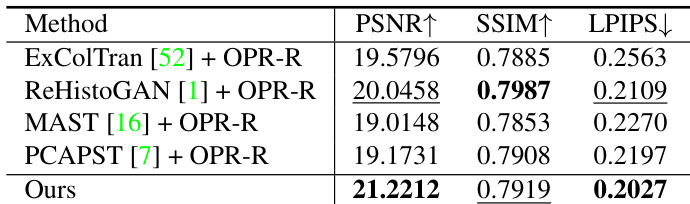
The authors evaluate their method against several baselines on real old photos using no-reference image quality assessment metrics. Results show that their method outperforms all baselines in both NIQE and BRISQUE, with the single-reference version achieving better scores than the multiple-reference version. The best performance is achieved by their method using multiple references. The proposed method achieves the best NIQE and BRISQUE scores compared to all baselines. The single-reference version of the proposed method performs better than the multiple-reference version in terms of NIQE and BRISQUE. The proposed method significantly outperforms all baselines in both NIQE and BRISQUE metrics.
The authors compare their method with existing datasets in terms of the number of images, era, content type, color space, and resolution. Their method uses a larger number of images from the 20th century, focusing on indoor and outdoor natural scenes in color, with a higher resolution compared to the other datasets. None of the datasets provide expert ground-truth annotations. The proposed method uses a larger dataset with more images from the 20th century compared to the other datasets. The proposed method focuses on indoor and outdoor natural scenes in color, unlike the other datasets which focus on faces or portraits in greyscale. The proposed method has a higher resolution and does not provide expert ground-truth annotations, unlike the other datasets.

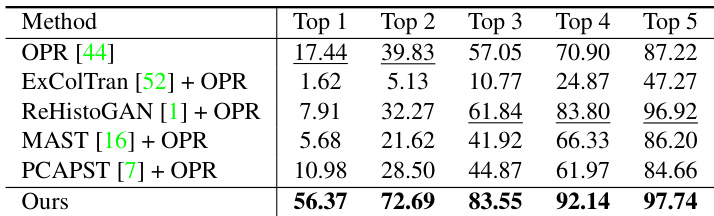
The authors conduct a user study to compare their method with baselines, evaluating modernization results on real old photos. The results show that their method outperforms other baselines, achieving the highest selection rate in the top rankings. The method demonstrates superior performance in both single-reference and multi-reference scenarios, with consistent advantages in user preference across different reference configurations. The proposed method achieves the highest user preference in the top rankings compared to all baselines. The method outperforms baselines significantly in both single-reference and multi-reference scenarios. The results indicate consistent user preference for the proposed method across different reference configurations.
The authors evaluate their method against several baselines on synthetic and real old photos, using metrics such as PSNR, SSIM, and LPIPS. Their method achieves the best performance in PSNR and LPIPS on synthetic data and outperforms other baselines in user studies, demonstrating superior modernization results through effective stylization and enhancement. The method also shows strong generalization to real-world scenarios, including greyscale photos and cases with unrelated references, while maintaining consistent performance across multiple reference inputs. The proposed method achieves the highest PSNR and LPIPS scores on synthetic data, indicating superior pixel-level and perceptual quality compared to baselines. The method outperforms baselines in user studies, with a higher selection rate, demonstrating better overall modernization results. The method maintains strong performance with multiple references and generalizes well to real-world scenarios, including greyscale photos and unrelated references.
The proposed method is evaluated against multiple baselines through comprehensive testing on synthetic and real-world old photographs across single and multi-reference configurations. These experiments validate the approach's capacity to enhance historical images with superior visual fidelity, structural coherence, and perceptual realism compared to existing techniques. User preference studies further corroborate these findings, demonstrating consistent selection advantages across various reference scenarios. Ultimately, the method proves highly robust and adaptable, successfully generalizing to diverse real-world conditions while effectively balancing stylization and enhancement for photo modernization.