Command Palette
Search for a command to run...
Une étude comparative des représentations de parole auto-supervisées dans la synthèse vocale text-to-speech lue et spontanée
Une étude comparative des représentations de parole auto-supervisées dans la synthèse vocale text-to-speech lue et spontanée
Siyang Wang Gustav Eje Henter Joakim Gustafson Éva Székely
Représentation de la parole et exploration des données
Résumé
Titre :
Résumé : Des travaux récents ont exploré l'utilisation de représentations de la parole issues de l'apprentissage auto-supervisé (SSL), telles que wav2vec2.0, comme support de représentation dans les systèmes de synthèse vocale (TTS) standards à deux étapes, en remplacement des mélo-spectrogrammes traditionnellement utilisés. Il demeure toutefois incertain quelle méthode SSL est la mieux adaptée au TTS, et si les performances diffèrent entre la synthèse de parole lue et celle de parole spontanée, cette dernière étant considérée comme plus difficile. Cette étude vise à répondre à ces questions en testant plusieurs méthodes SSL, y compris différentes couches d'un même modèle SSL, dans un cadre TTS à deux étapes sur des corpus de parole lue et spontanée, tout en maintenant une architecture de modèle TTS et des paramètres d'entraînement constants. Les résultats des tests d'écoute montrent que la 9e couche du modèle wav2vec2.0 à 12 couches (finement ajusté pour la reconnaissance automatique de la parole, ASR) surpasse les autres SSL testés ainsi que les mélo-spectrogrammes, tant pour la parole lue que pour la parole spontanée. Notre travail éclaire à la fois la manière dont les SSL peuvent améliorer facilement les systèmes TTS actuels, et comment les différentes méthodes SSL se comparent dans la tâche générative complexe qu'est le TTS.
One-sentence Summary
Listening tests on read and spontaneous corpora with constant model architecture and training settings demonstrate that replacing mel-spectrograms with self-supervised speech representations improves two-stage text-to-speech synthesis, with the ninth layer of ASR-finetuned wav2vec2.0 outperforming all other tested SSLs and mel-spectrograms.
Key Contributions
- This study evaluates multiple speech self-supervised learning models and their intermediate layers as direct replacements for mel-spectrograms in two-stage text-to-speech systems trained on both read and spontaneous corpora.
- Comparative analysis demonstrates that intermediate layers of ASR-finetuned architectures yield superior generative representations compared to final layers or conventional acoustic features, establishing layer depth as a critical determinant for synthesis suitability.
- Subjective listening tests and objective resynthesis metrics confirm that the ninth layer of the 12-layer wav2vec2.0 model consistently outperforms all baselines, with self-supervised features delivering particularly pronounced quality improvements for spontaneous speech synthesis.
Introduction
Modern two-stage text-to-speech systems traditionally rely on mel-spectrograms as intermediate acoustic targets, but researchers are increasingly adopting self-supervised learning representations like wav2vec2.0 to leverage massive unlabeled audio datasets and improve synthesis quality. Prior investigations have left critical gaps regarding which SSL architectures or internal layers optimize speech generation, and existing approaches have exclusively targeted scripted read speech while overlooking spontaneous speech, which contains complex vocal phenomena that traditional text-aligned models struggle to capture. The authors systematically evaluate multiple SSL models and layer configurations in two-stage TTS pipelines for both read and spontaneous corpora. They demonstrate that the ninth layer of an ASR-finetuned wav2vec2.0 consistently outperforms both mel-spectrograms and other SSL variants, reveal that SSL features deliver even greater quality gains for spontaneous speech, and show that intermediate resynthesis error does not reliably predict final audio quality.
Dataset
The authors structure their TTS training data using two distinct sources to cover both read and spontaneous speech:
- Dataset Composition and Sources: The corpus combines the widely benchmarked LJSpeech corpus for read speech with the Trinity Speech-Gesture Dataset (TSGD) for spontaneous speech.
- Subset Details: The LJSpeech subset provides standard read recordings. The TSGD subset contains 25 impromptu monologues averaging 10.6 minutes each, recorded by a single male actor in a colloquial delivery style.
- Processing and Cropping Strategy: To prepare the audio for TTS, the authors segment the recordings into speech stretches defined by natural breath events. They then stitch these segments together using an overlapping combination method to create a continuous utterance structure.
- Training Usage: The processed data is used to train both read and spontaneous TTS models. The breath-aware segmentation and overlapping stitching are applied to preserve natural prosody and ensure smooth acoustic transitions during generation.
Method
The authors leverage a two-stage framework for speech synthesis, structured around a neural acoustic model and a vocoder, with the overall system depicted in the diagram below. The first stage employs a parallel transformer-based text-to-speech (TTS) model, FastPitch 1.1, which is adapted from a prior work and enhanced with monotonic alignment to produce mel-spectrograms from input text. This stage is trained using identical hyperparameters as in the reference work, with a batch size of 96, and continues until validation loss plateaus, typically requiring around 200 epochs on the LJSpeech corpus. For smaller datasets such as the spontaneous TSGD corpus, the authors initialize training from a pre-trained LJSpeech model and fine-tune for an additional 200 epochs, which significantly improves synthesis quality.
The second stage is a vocoder, specifically HiFi-GAN, which converts the mel-spectrograms generated by the acoustic model into waveforms. This stage is trained in a setup similar to the reference work, with training batches consisting of 0.5-second random audio excerpts. The batch size varies between 160 and 192 depending on the representation's dimension and sampling rate, ensuring consistent per-iteration data throughput across models. For LJSpeech, SSL-based vocoders are trained for 180k iterations at 22 kHz, while those for the spontaneous corpus are trained from scratch for 100k iterations at 16 kHz. The system also incorporates a loss function that combines mel-spectrogram L1 loss and waveform GAN loss to guide the generation of high-fidelity waveforms.
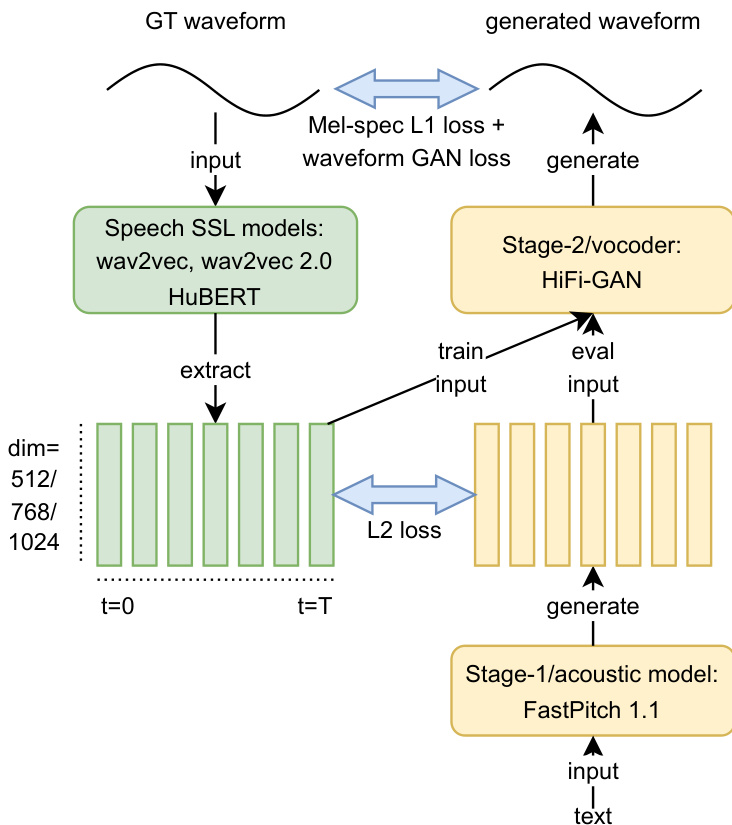
The input speech waveform is processed through a speech self-supervised learning (SSL) model—such as wav2vec, wav2vec 2.0, or HuBERT—to extract latent representations. These representations are then fed into the stage-2 vocoder to generate a waveform. The framework also includes a feedback loop where the generated waveform is compared to the ground-truth waveform, and the model is trained to minimize the L2 loss between the extracted features of the generated and target waveforms. This enables end-to-end optimization of the entire system, with the SSL model acting as a feature extractor for the vocoder.
Experiment
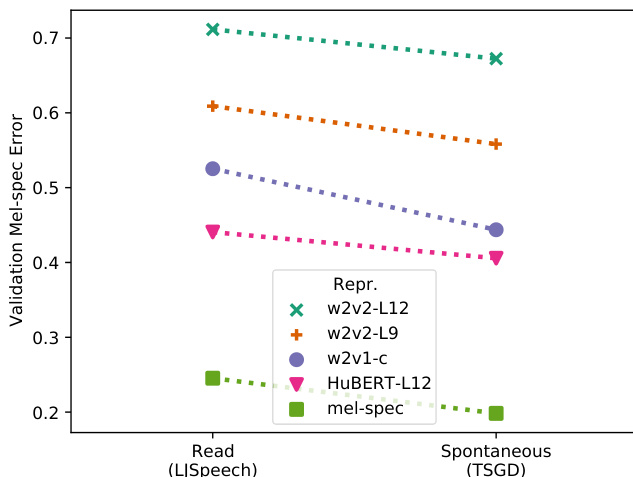
The study evaluated four speech self-supervised learning models and specific internal layers against standard mel-spectrograms within a two-stage text-to-speech pipeline. Resynthesis tests validated waveform reconstruction capabilities, while comparative listening assessments measured subjective synthesis quality across both read and spontaneous speech. Results consistently demonstrated that layer nine of wav2vec2.0 significantly outperformed all other representations, with spontaneous synthesis showing an even stronger preference for this feature set. Ultimately, the findings indicate that reconstruction accuracy does not correlate with synthesis quality, highlighting self-supervised representations as a highly effective alternative to traditional spectrograms, particularly for challenging spontaneous speech generation.
The authors compare various speech self-supervised learning (SSL) representations for use in a two-stage text-to-speech pipeline, evaluating both resynthesis quality and subjective TTS performance. Results show that a specific layer of wav2vec2.0 outperforms other SSLs and mel-spectrograms in both read and spontaneous speech synthesis, with the performance gap being more pronounced in spontaneous speech. w2v2-L9 outperforms all other tested SSL representations and mel-spectrograms in both read and spontaneous speech TTS. The resynthesis performance of SSL representations does not predict their overall TTS performance. The advantage of w2v2-L9 over mel-spectrogram is significantly larger in spontaneous TTS compared to read TTS.
The authors compare various speech SSL representations for use in a two-stage TTS pipeline, focusing on both read and spontaneous speech. Results from listening tests show that one specific SSL representation, w2v2-L9, consistently outperforms other SSLs and the standard mel-spectrogram across both speech types, indicating its effectiveness as an intermediate representation for TTS. w2v2-L9 outperforms other SSLs and mel-spectrogram in both read and spontaneous TTS The preference for w2v2-L9 over mel-spectrogram is higher in spontaneous TTS than in read TTS Resynthesis performance does not predict overall TTS performance
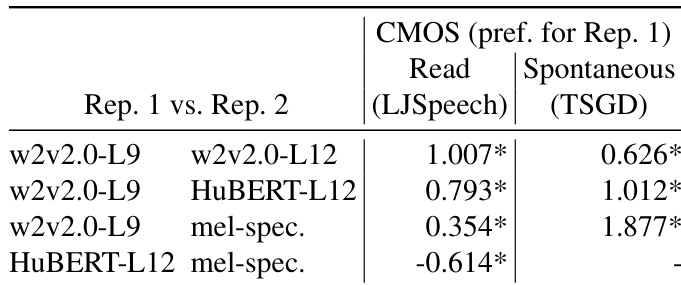
The authors compare several speech self-supervised learning (SSL) models as representations in a two-stage text-to-speech pipeline, using both read and spontaneous speech corpora. Results show that one specific SSL model, wav2vec2.0 layer 9, outperforms other SSLs and the traditional mel-spectrogram in both settings, despite not having the best resynthesis performance. The study highlights that resynthesis quality does not necessarily predict TTS performance and suggests that SSLs, particularly wav2vec2.0-L9, are promising for spontaneous speech synthesis. wav2vec2.0 layer 9 outperforms all other tested SSLs and mel-spectrogram in both read and spontaneous speech TTS resynthesis performance does not correlate with TTS performance, indicating different aspects of SSL representations are important for synthesis wav2vec2.0-L9 shows a stronger preference in spontaneous TTS compared to read TTS, suggesting suitability for natural speech synthesis
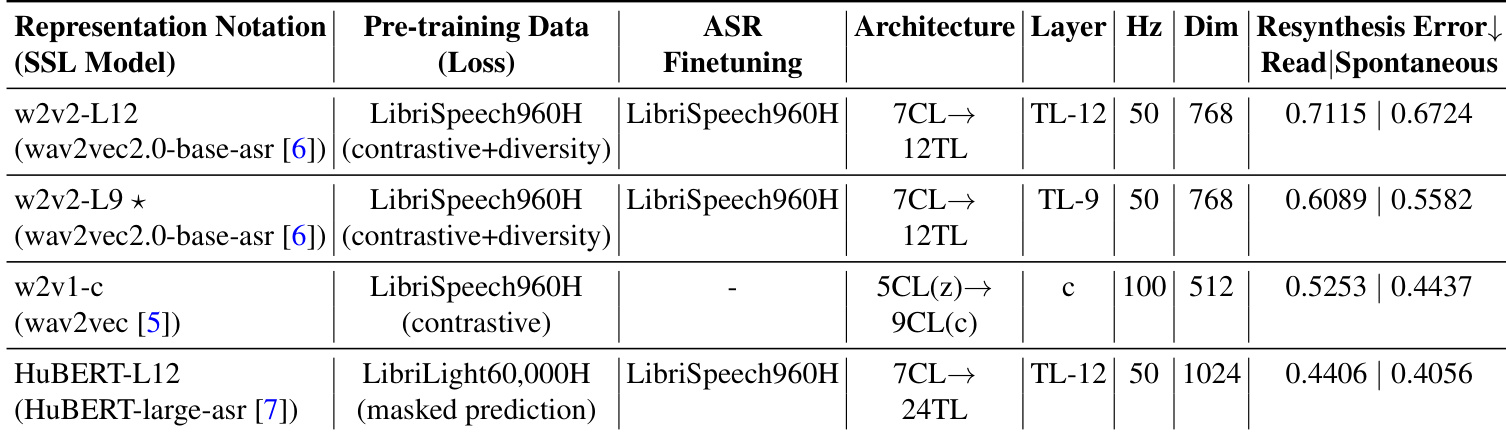
The evaluation compares various speech self-supervised learning representations within a two-stage text-to-speech pipeline, validating their utility through both audio resynthesis and subjective listening tests across read and spontaneous speech. Results demonstrate that wav2vec2.0 layer 9 consistently yields superior synthesis quality compared to other SSL models and mel-spectrograms, with its performance advantage being especially marked in spontaneous speech. Crucially, the study finds that resynthesis fidelity does not predict overall TTS quality, indicating that distinct representation features drive natural speech generation. These qualitative outcomes establish wav2vec2.0 layer 9 as a highly effective intermediate representation for robust text-to-speech systems.