Command Palette
Search for a command to run...
FedCV : Un cadre d'apprentissage fédéré pour des tâches variées de vision par ordinateur
FedCV : Un cadre d'apprentissage fédéré pour des tâches variées de vision par ordinateur
Détection des contours — Approches générales en vision par ordinateur et apprentissage profond
Résumé
L'apprentissage fédéré (FL) est un paradigme d'apprentissage distribué permettant d'entraîner un modèle global ou personnalisé à partir de données décentralisées sur des dispositifs périphériques. Toutefois, dans le domaine de la vision par ordinateur, les performances des modèles en apprentissage fédéré restent nettement inférieures à celles de l'entraînement centralisé, en raison du manque d'exploration de tâches variées au sein d'un cadre FL unifié. L'apprentissage fédéré a rarement été démontré comme efficace pour des tâches avancées de vision par ordinateur, telles que la détection d'objets et la segmentation d'images. Afin de combler cet écart et de faciliter le développement de l'apprentissage fédéré pour les tâches de vision par ordinateur, nous proposons dans ce travail une bibliothèque et un cadre d'évaluation pour l'apprentissage fédéré, nommé FedCV, afin d'évaluer l'apprentissage fédéré sur les trois tâches de vision par ordinateur les plus représentatives : la classification d'images, la segmentation d'images et la détection d'objets. Nous fournissons des jeux de données de référence non-I.I.D., des modèles et divers algorithmes de référence pour l'apprentissage fédéré. Notre étude de benchmarking suggère qu'il existe plusieurs défis qui méritent une exploration future : les astuces d'entraînement centralisé peuvent ne pas être directement appliquées à l'apprentissage fédéré ; les jeux de données non-I.I.D. dégradent en réalité la précision du modèle dans une certaine mesure selon les tâches ; et l'amélioration de l'efficacité système de l'entraînement fédéré s'avère difficile compte tenu du nombre considérable de paramètres et du coût mémoire par client.
One-sentence Summary
The authors propose FedCV, a unified federated learning framework and benchmarking library that provides non-I.I.D. datasets, models, and reference algorithms to evaluate image classification, segmentation, and object detection, demonstrating that centralized training techniques do not directly apply to federated learning, that non-I.I.D. data reduces accuracy across tasks, and that large parameter counts and per-client memory limits hinder system efficiency.
Key Contributions
- This work introduces FedCV, a federated learning library and benchmarking framework that evaluates distributed training across image classification, image segmentation, and object detection. The system provides a standardized environment for testing federated algorithms on representative computer vision tasks.
- The framework provides non-I.I.D. benchmarking datasets, standardized model architectures, and multiple reference federated optimization algorithms to support systematic evaluation.
- A comprehensive benchmark study identifies key challenges in applying federated learning to computer vision. The analysis demonstrates that centralized training techniques often fail in federated settings, non-I.I.D. data distributions reduce model accuracy, and large parameter counts create significant per-client memory bottlenecks.
Introduction
Federated learning enables privacy-preserving model training across decentralized edge devices, offering a practical solution for computer vision applications constrained by strict data privacy regulations, high transfer costs, or proprietary data requirements. Despite its potential, prior federated learning research has largely overlooked advanced vision tasks, focusing instead on small-scale image classification with centralized optimization techniques that do not translate well to distributed edge environments. This narrow focus leaves critical challenges like non-I.I.D. data distribution, hardware heterogeneity, and the scalability of large vision models largely unaddressed. To bridge this gap, the authors introduce FedCV, a unified federated learning library and benchmarking framework tailored specifically for computer vision. The framework supports image classification, segmentation, and object detection within a single distributed training architecture, providing standardized non-I.I.D. datasets, modular federated optimization algorithms, and scalable APIs to accelerate fair evaluation and real-world deployment.
Dataset
- Dataset Composition & Sources: The authors curate a federated computer vision benchmark suite comprising four primary datasets: Google Landmarks Dataset 23k (GLD-23K) sourced from smartphone users, the standard CIFAR-100 dataset, an augmented PASCAL VOC 2011 subset, and the COCO dataset.
- Subset Details: GLD-23K and CIFAR-100 are designated for image classification. The PASCAL VOC subset contains 11,355 images annotated across 20 foreground object classes and one background class. COCO provides realistic everyday scenes with detection and segmentation labels generated via Amazon Mechanical Turk.
- Data Usage & Partitioning: The team applies Latent Dirichlet Allocation (LDA) to partition all datasets into non-I.I.D. client distributions, simulating realistic federated learning environments. They use the data to train and evaluate federated optimization algorithms like FedAvg and FedOpt, while also running centralized fine-tuning baselines for comparison.
- Processing & Pipeline: Rather than implementing custom cropping or metadata extraction, the authors standardize preprocessing by providing automated download scripts and integrated data loaders. These pipelines handle annotation parsing and client-side distribution, ensuring consistent data formatting and streamlining setup across all federated clients.
Method
The authors leverage the FedML.ai framework as a foundation to design FedCV, an open-source federated learning system tailored for diverse computer vision tasks. The system architecture, illustrated in the framework diagram, integrates a layered structure to support both high-level research and low-level distributed communication. At the top, FedML-API provides high-level abstractions for users to define computer vision applications, including image classification, segmentation, and object detection, alongside non-IID datasets and data loaders. These applications are supported by a suite of federated learning algorithms, such as FedAvg, FedOpt, FedNova, FedProx, and others, which are implemented using distributed or standalone configurations. The core of the system is built upon FedML-core, which handles low-level functionalities like communication, model training, and security primitives. This layer includes components such as the ComManager for managing communication threads, and the Abstract Communication Layer that supports various protocols including MPI, MQTT, and tensor-aware RPC, enabling efficient inter-node communication across different data centers. The framework also incorporates security and privacy primitives, such as secure aggregation, to enhance the robustness of federated learning processes. 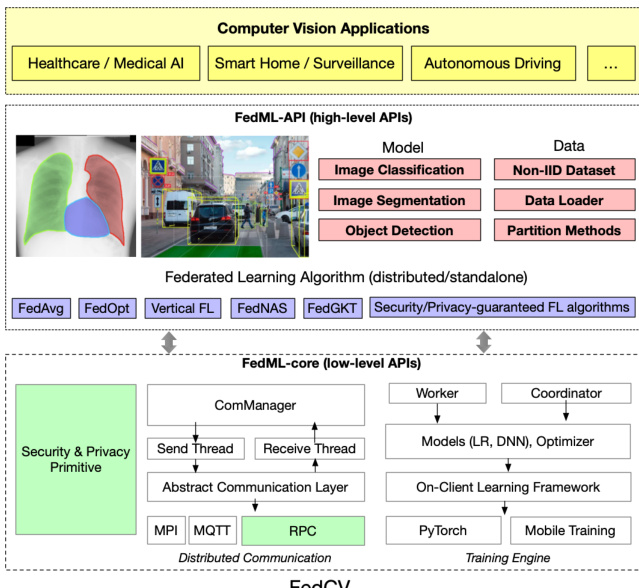
The design of FedCV emphasizes flexibility and ease of use through modular components and extensible APIs. The system supports multiple computer vision applications, including healthcare, smart home surveillance, and autonomous driving, which are integrated into the framework through dedicated models and data handling mechanisms. The training engine within FedCV leverages PyTorch and supports on-client learning frameworks, allowing for customizable training procedures and model architectures. The communication layer is optimized for distributed computing, with components like the Send Thread and Receive Thread enabling efficient data exchange between workers and the coordinator. This modular design facilitates the implementation of diverse federated learning algorithms, including decentralized, vertical, and split learning paradigms, by abstracting the underlying communication and optimization processes. 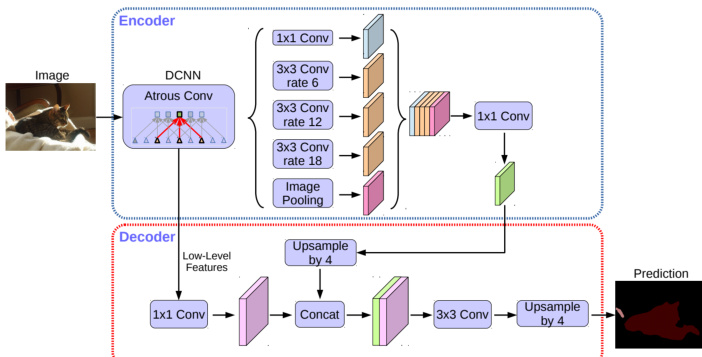
In the context of computer vision tasks, the authors introduce a specific model architecture for image segmentation, which is detailed in the figure below. This architecture employs a deep convolutional neural network (DCNN) as an encoder, processing input images through a series of convolutional layers with varying rates, such as 6, 12, and 18, to capture multi-scale features. The encoder output is then passed to a decoder, which reconstructs the segmentation map through upsampling and concatenation operations. The decoder uses 1x1 convolutions and 3x3 convolutions to refine the features, ultimately producing the final prediction. This design enables efficient feature extraction and reconstruction, suitable for various segmentation tasks. 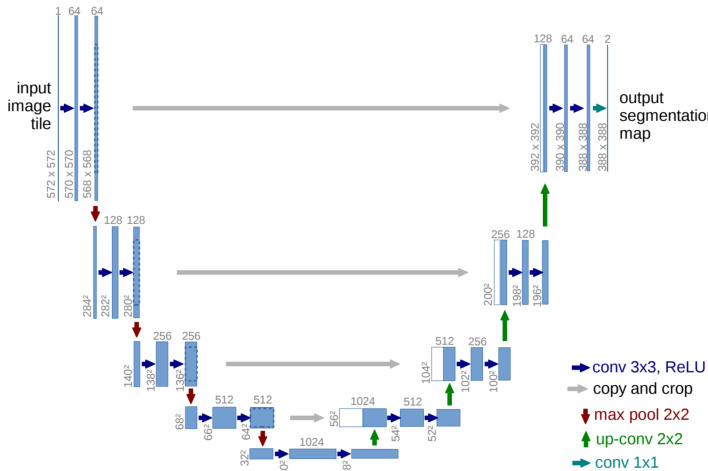
The overall framework is designed to address the research gap in federated learning for computer vision by providing benchmarks, reference implementations, and flexible APIs. This enables researchers to explore various training paradigms and network typologies efficiently. The system supports multi-GPU distributed training, which reduces computational time and makes large-scale experiments feasible. By integrating these components, FedCV offers a comprehensive platform for developing and evaluating federated learning algorithms in diverse computer vision applications. 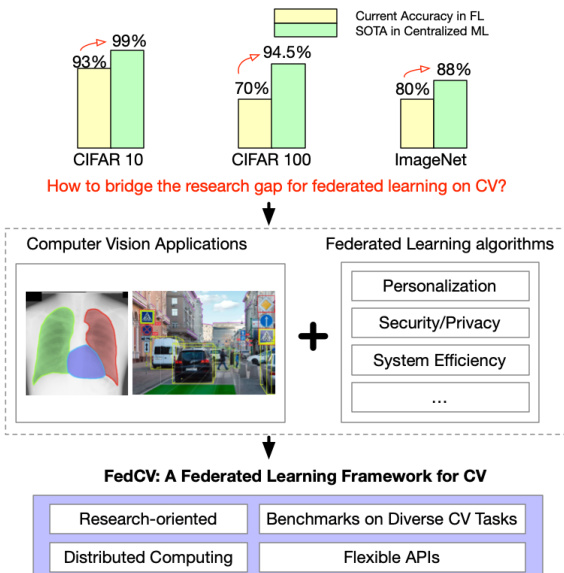
Experiment
Experiments across image classification, segmentation, and object detection tasks on various deep learning models and federated datasets evaluate the impact of data heterogeneity, training strategies, and system constraints. Classification results validate that fine-tuning significantly accelerates convergence and improves accuracy, while segmentation experiments demonstrate that training from scratch often matches fine-tuned performance and better suits memory-constrained edge devices. Object detection evaluations reveal that federated frameworks struggle to match centralized results on non-IID data due to optimizer incompatibilities and communication bottlenecks. Collectively, these findings underscore the critical trade-offs between model complexity, data distribution, and system efficiency in practical federated learning deployments.
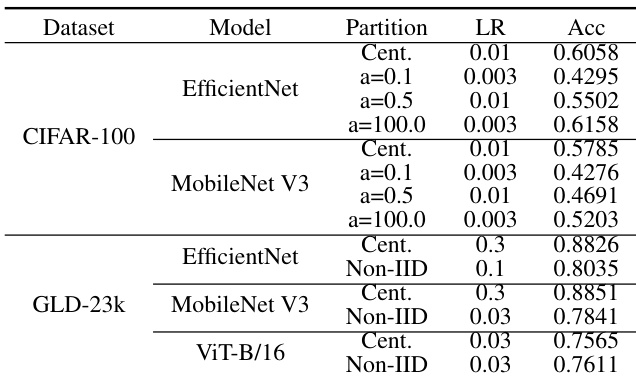
The authors present experimental results on image classification tasks using different models and datasets, comparing centralized training with federated learning approaches. The results show that centralized training generally outperforms federated learning, with performance varying based on model type, data partitioning, and training strategies. The experiments highlight the impact of non-IID data distributions and the effectiveness of fine-tuning versus training from scratch. Centralized training achieves higher accuracy than federated learning for both EfficientNet and MobileNet V3 on CIFAR-100 and GLD-23k datasets. Fine-tuning provides better performance compared to training from scratch, with the gap being more pronounced under non-IID data conditions. The choice of learning rate and data partitioning significantly influences model accuracy in federated learning settings.
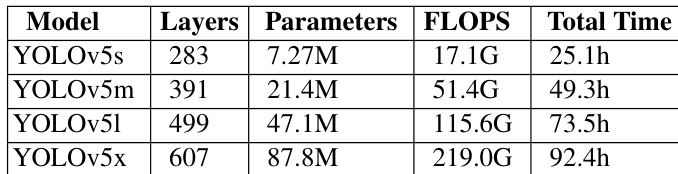
The authors present experimental results on object detection tasks using YOLOv5 models in a federated learning setting. The results show that model performance varies with structural complexity, where deeper and wider models achieve higher accuracy but require more training time. The performance gap between centralized and federated training is significant, indicating challenges in transferring centralized training techniques to federated environments. Deeper and wider YOLOv5 models achieve higher accuracy but require longer training times. Federated training performance is notably lower than centralized training for object detection tasks. The choice of model structure significantly impacts both accuracy and training efficiency in federated settings.
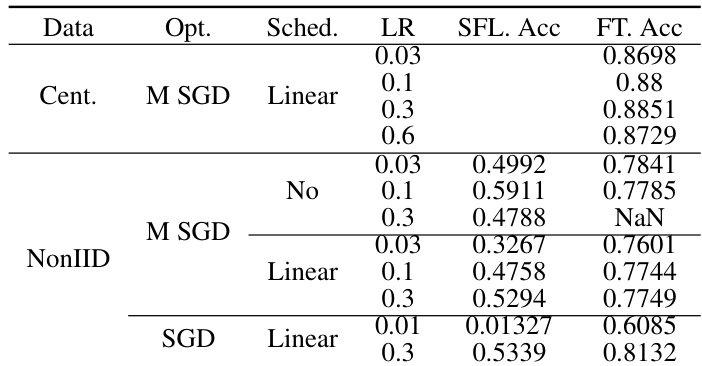
The authors present experimental results on image classification, image segmentation, and object detection tasks in federated learning settings. The results show that centralized training generally outperforms federated training, particularly for non-IID data distributions, and that fine-tuning can significantly improve performance compared to training from scratch. The choice of optimizer, learning rate, and model architecture also affects performance, with momentum SGD and learning rate schedulers showing mixed effects depending on the context. Centralized training achieves higher accuracy than federated training, especially under non-IID data conditions. Fine-tuning leads to faster convergence and better final accuracy compared to training from scratch. The choice of learning rate and optimizer impacts model performance, with momentum SGD and learning rate schedulers showing varying effectiveness across different settings.
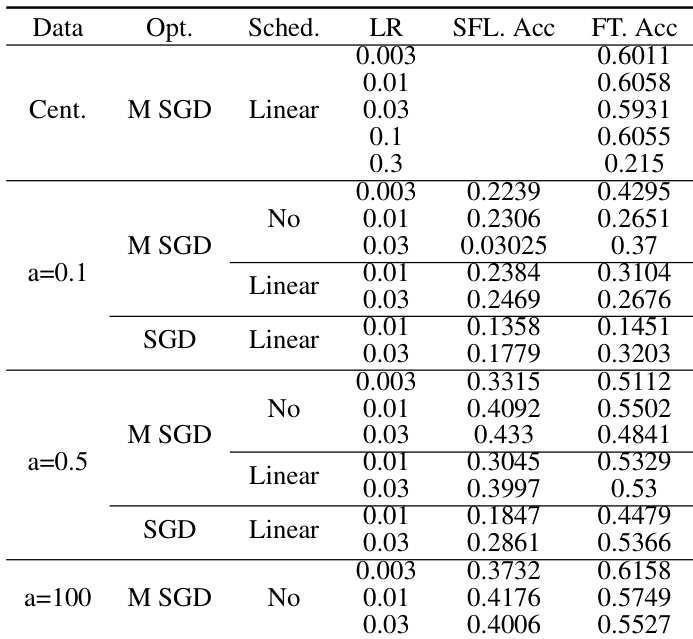
The authors present experimental results on image classification tasks, comparing centralized training with federated learning methods across different models and non-IID data settings. The results show that centralized training generally outperforms federated learning, with performance differences varying based on the degree of data heterogeneity and the use of fine-tuning. The impact of optimization techniques such as momentum SGD and learning rate schedulers is also analyzed, revealing that their effectiveness depends on the data distribution and model architecture. Centralized training achieves higher accuracy than federated learning, with the gap being more pronounced under higher data heterogeneity. Fine-tuning improves performance compared to training from scratch, especially in scenarios with less data heterogeneity. The effectiveness of momentum SGD and learning rate schedulers varies depending on the data distribution and model type.
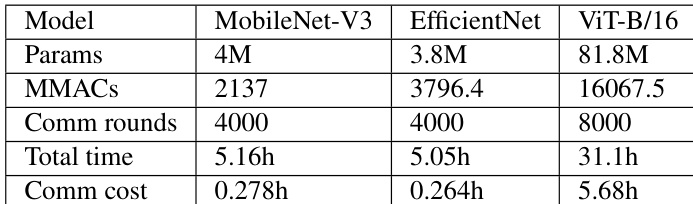
The authors present experimental results on image classification, segmentation, and detection tasks, focusing on the efficiency of training different deep learning models in a federated setting. The the the table summarizes system performance metrics, showing that larger models like ViT require significantly more communication rounds and time compared to smaller models, indicating higher communication overhead in federated learning. Larger models such as ViT require substantially more communication rounds and total training time compared to smaller models like MobileNet-V3 and EfficientNet. The communication cost is significantly higher for larger models, with ViT having a much greater communication cost than the other models. The total training time increases with model size, with ViT taking considerably longer to train than MobileNet-V3 and EfficientNet.
The experiments evaluate centralized versus federated learning across image classification, segmentation, and object detection tasks using diverse model architectures and datasets under non-IID data distributions. Results consistently demonstrate that centralized training achieves superior accuracy, with the performance gap widening as data heterogeneity increases. Fine-tuning proves more effective than training from scratch, particularly in federated environments, while larger model architectures incur substantially higher communication overhead and training latency. Ultimately, the findings highlight that federated learning performance is highly sensitive to data distribution, model complexity, and optimization strategies, underscoring the inherent challenges of replicating centralized training efficiency in distributed settings.