Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Reconnaissance faciale profonde utilisant Keras, Dlib et OpenCV
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
By predicting facial attributes such as gender, eyeglasses, and hat usage directly from face identification DCNN hidden layers and applying variable selection to localize relevant neurons, the authors demonstrate that these models inherently encode semantic cues with over 96% accuracy, performing within three percentage points of supervised attribute networks and providing a quantifiable alternative to subjective visualization methods.
Key Contributions
- This work introduces a quantitative framework that trains attribute classifiers on hidden layer outputs to measure the implicit encoding of semantic features at each network depth.
- A variable selection technique is applied to map specific facial attributes to precise neurons within each layer, establishing the exact distribution and localization of relevant features throughout the architecture.
- Experimental results demonstrate that gender, eyeglasses, and hat usage can be predicted with over 96% accuracy using single neural outputs, achieving performance within three percentage points of networks explicitly optimized for attribute recognition.
Introduction
Deeply learned representations have become the standard for face recognition, yet their latent features remain opaque, limiting model trust and interpretability in high-stakes applications. Prior interpretability efforts primarily rely on visualization techniques that are subjective, difficult to scale across modern architectures, and often misaligned with how face recognition networks actually operate as feature extractors during inference. To address this, the authors leverage a quantitative analysis framework that trains attribute classifiers directly on hidden layer outputs to measure implicit semantic encoding. By applying variable selection techniques, they precisely locate neurons responsible for specific face attributes and demonstrate that single neurons in identification-optimized networks can predict attributes like gender and eyewear with over ninety-six percent accuracy, rivaling networks explicitly trained for those tasks.
Method
The authors leverage a systematic framework to analyze the latent representations learned by deep face recognition networks, focusing on the encoding of semantic face attributes. The overall architecture involves processing features extracted from each hidden layer of a deep convolutional neural network (DCNN), such as ResNet50, to determine how well specific face attributes are represented. The framework begins by extracting high-dimensional feature maps from a given layer, which are then processed to perform two primary analyses: attribute prediction and neuron-level relevance assessment.
Refer to the framework diagram 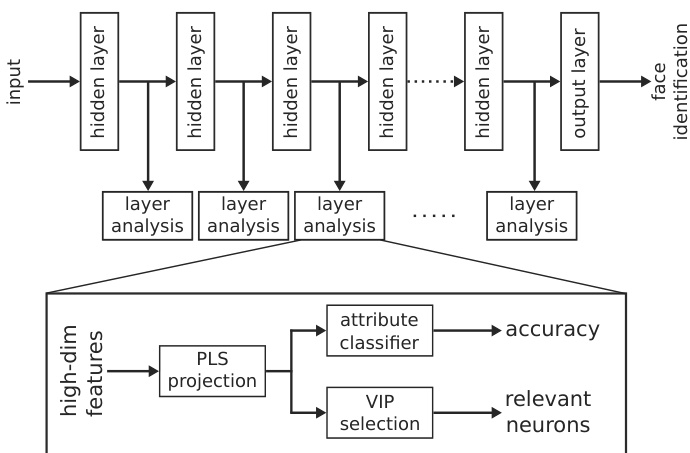 . For each layer, the high-dimensional features are first subjected to a Partial Least Squares (PLS) projection to reduce dimensionality while preserving discriminative information relevant to the attributes. This low-dimensional projection is then used to train a simple attribute classifier, whose accuracy serves as a quantitative measure of how well the layer encodes the target attribute. This approach enables a performance curve to be generated for each attribute across the network depth, revealing the progression of attribute learning from early to deeper layers.
. For each layer, the high-dimensional features are first subjected to a Partial Least Squares (PLS) projection to reduce dimensionality while preserving discriminative information relevant to the attributes. This low-dimensional projection is then used to train a simple attribute classifier, whose accuracy serves as a quantitative measure of how well the layer encodes the target attribute. This approach enables a performance curve to be generated for each attribute across the network depth, revealing the progression of attribute learning from early to deeper layers.
As shown in the figure below: 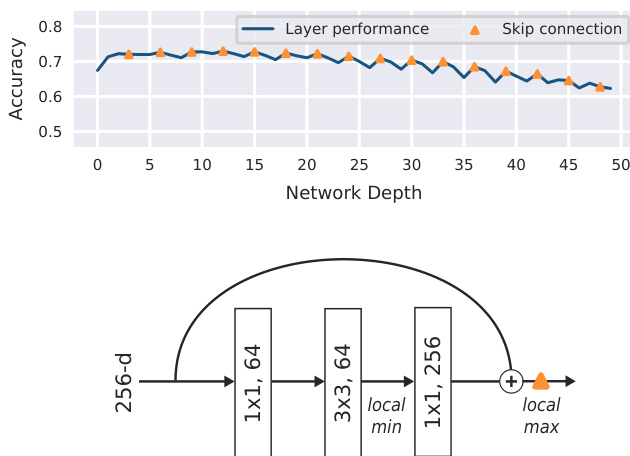 , the PLS projection is implemented via the Non-linear Iterative Partial Least Squares (NIPALS) algorithm. This algorithm decomposes the input feature matrix X and the attribute matrix Y into low-dimensional factors T and U, respectively, through iterative updates that maximize the covariance between the extracted scores. The algorithm is executed independently for each attribute to prevent interference between different attribute projections. The resulting low-dimensional space is used to train a classifier, and the VIP (Variable Importance in Projection) score is computed to identify the most relevant neurons contributing to the discriminative projection. The VIP score for the jth neuron is given by the formula:
, the PLS projection is implemented via the Non-linear Iterative Partial Least Squares (NIPALS) algorithm. This algorithm decomposes the input feature matrix X and the attribute matrix Y into low-dimensional factors T and U, respectively, through iterative updates that maximize the covariance between the extracted scores. The algorithm is executed independently for each attribute to prevent interference between different attribute projections. The resulting low-dimensional space is used to train a classifier, and the VIP (Variable Importance in Projection) score is computed to identify the most relevant neurons contributing to the discriminative projection. The VIP score for the jth neuron is given by the formula:
where m is the original dimensionality, k is the projection dimensionality, and SSi is the sum of squares explained by the ith component. This score allows for a fine-grained analysis of the network, identifying specific neurons and filters that encode information for attribute prediction. The framework also evaluates the efficiency of the VIP selection by measuring classifier performance when only the selected neurons are used as input.
Experiment
The evaluation trains a ResNet50 face recognition network on VGGFace2 and validates its internal representations by analyzing 40 CelebA attributes across network depths, filters, and individual neurons. Depth analysis reveals that shallow features capture semantic cues effectively while deeper layers progressively filter out intra-class variations to prioritize identity-specific information, whereas neuron-level analysis confirms that attribute data concentrates in a sparse subset of high-scoring units without sacrificing predictive performance. The experiments further demonstrate that residual skip connections induce predictable accuracy fluctuations and that activation-based visualizations frequently misrepresent the actual encoded concepts. Ultimately, the study concludes that standard recognition architectures implicitly encode rich semantic and soft-biometric information, remaining highly competitive with fully supervised attribute prediction models.
The authors analyze the performance of a deep convolutional neural network on predicting facial attributes from the CelebA dataset, using ResNet50 as the architecture. Results show that shallow features capture discriminative information for many attributes, with performance generally plateauing early or decreasing in deeper layers, and that attribute information is concentrated in a small number of neurons. The network's ability to predict certain attributes is competitive with fully supervised methods, even though the features were not trained for attribute recognition. Shallow network features are discriminative for many facial attributes, with accuracy often plateauing early in the network depth. Attribute prediction accuracy decreases in deeper layers for some attributes, suggesting robustness to variations like skin tone or brightness. The information for each attribute is concentrated in a small number of neurons, with high-scoring neurons being rare and a single neuron performing nearly as well as an entire layer.
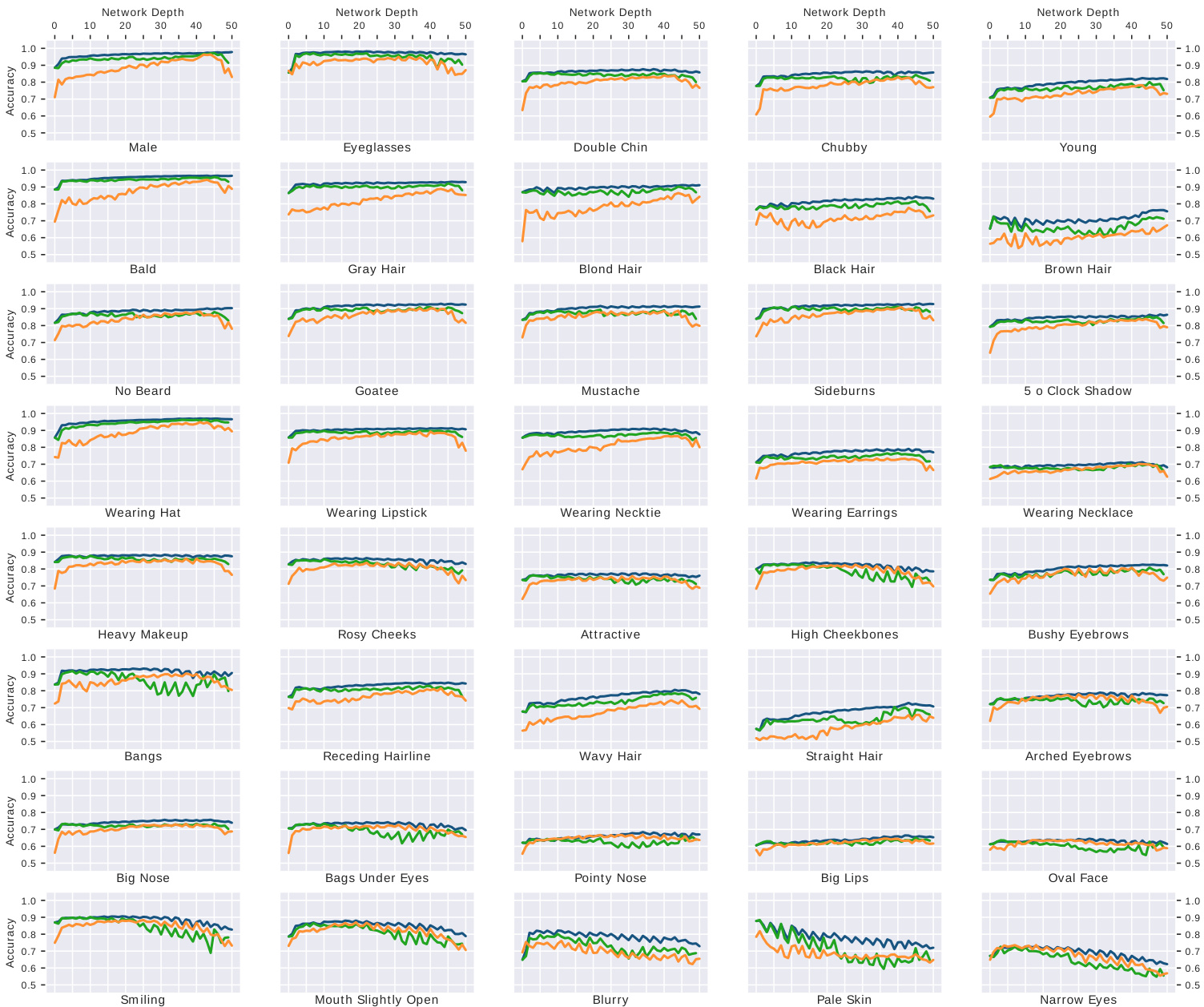
The authors evaluate the performance of deep recognition features for attribute prediction on the CelebA dataset, comparing various methods including using entire layers, best filters, and best neurons. Results show that while individual neurons and filters can capture attribute information, their performance is generally lower than using the full layer, with significant variations across attributes. The best-performing methods achieve competitive accuracy with supervised multitask networks for some attributes. Using the best neuron or filter from a layer yields lower accuracy than using the entire layer, indicating attribute information is concentrated but less robust. The performance of attribute prediction varies significantly across different attributes, with some showing high accuracy and others much lower. Deep recognition features achieve competitive results with supervised multitask networks for certain attributes, suggesting they encode relevant semantic information.
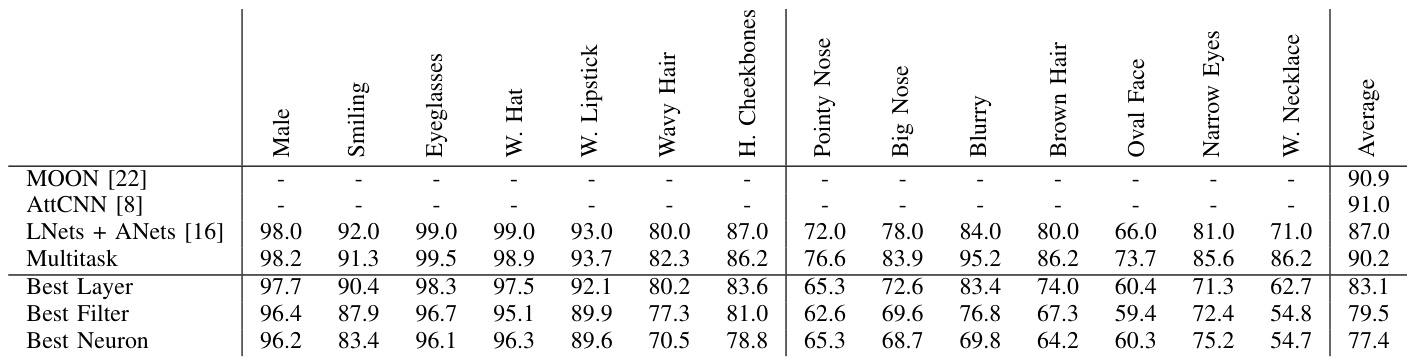
The authors evaluate a pretrained ResNet50 on the CelebA dataset to assess how facial attribute information is distributed across network depths and individual neurons. These experiments validate that attribute recognition capabilities are primarily captured in shallow layers and highly concentrated within a small subset of neurons rather than being uniformly spread throughout the architecture. Despite lacking explicit training for this task, the pretrained features achieve performance comparable to supervised multitask models for several attributes, demonstrating that deep recognition networks inherently encode robust semantic cues. Ultimately, the findings highlight the sparse yet highly discriminative nature of facial attribute representations in convolutional architectures.