Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Créer votre première application de TAL pour détecter les spams
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
The authors developed an interactive, instructor-guided workshop for Italian high school students aged 13 to 18 that employs gamified exercises like bracelets and restaurant menus to simulate core computational linguistics tasks, including voice recognition, Markov chains, and syntactic parsing, thereby addressing the absence of NLP education in secondary schools and fostering sustained interest in the field.
Key Contributions
- The paper introduces an interactive, game-based workshop that translates foundational natural language processing and computational linguistics principles into hands-on activities for Italian high school students aged 13 to 18. Participants simulate machine operations including voice recognition, Markov chains, and syntactic parsing to engage with core algorithmic concepts.
- The curriculum explicitly contrasts human linguistic intuition with algorithmic processing through exercises on the McGurk effect and accent adaptation across Italian regional accents. These modules demonstrate how computational systems optimize speech recognition tasks without replicating the multimodal and contextual strategies inherent to human language comprehension.
- The workshop was implemented across multiple Italian venues between 2019 and 2021 in both face-to-face and online formats. This structured delivery addresses secondary education curricular gaps and provides students with practical exposure to computational language technologies for informed university degree selection.
Introduction
Natural language processing powers the everyday digital tools teenagers rely on, yet formal education rarely exposes students to the computational linguistics behind these systems. This educational gap limits critical engagement with AI applications and reduces interest in pursuing related university degrees. Prior teaching methods often treat language prescriptively, overlook the layered complexity of machine understanding, and rely on advanced neural architectures that can obscure foundational concepts for beginners. The authors address these challenges by developing an interactive, game-based workshop that introduces high school students to core NLP principles through hands-on activities like speech recognition exercises and syntactic puzzles. By prioritizing traditional statistical approaches before introducing neural networks, they clearly demonstrate how computers disentangle linguistic layers, ultimately aiming to foster digital literacy and inspire future academic interest in computational linguistics.
Dataset
- Composition and Sources: The authors utilize a custom Italian corpus based on a "Snow White" narrative, originally adapted from English Computational Linguistics Olympiad problems. The materials also incorporate examples of regional Italian accents to demonstrate diatopic variation.
- Subset Details and Structure: Rather than standard machine learning splits, the corpus is organized into five interactive modules. These range from phonotactic masking exercises to a simplified constituent grammar that restricts syntactic categories to five phrase types (sentence, noun phrase, verb phrase, prepositional phrase, and subordinate clause).
- Usage and Processing: The data supports an educational workshop instead of model training. Participants interact with the corpus through a custom web interface that enables drag-and-drop sentence construction and automated token assignment. The authors mask the text using either symbol substitution or manually defined phonotactic constraints to generate non-words, effectively separating semantic content from symbolic representation.
- Metadata and Adaptation: Each token is equipped with POS tags and syntactic annotations that are color-coded for physical and digital gameplay. The corpus remains unmasked during specific workshop phases to highlight recognizable characters and repetitive bigrams. The authors also provide open-access scripts that allow educators to generate analogous materials for other languages, provided a standardized annotated corpus is available.
Method
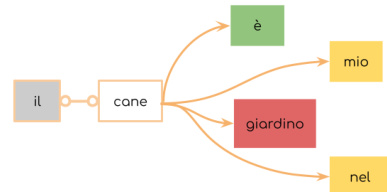
The authors leverage a hands-on, interactive framework to introduce foundational concepts in natural language processing through a sequence of structured activities. The overall approach is designed to progressively bridge human linguistic intuition with computational modeling, using physical artifacts and metaphors to ground abstract ideas. The framework begins with a statistical language understanding task, where participants are presented with sets of words—either in a familiar language or a masked, unknown script—and asked to reconstruct plausible sentences. This activity highlights the role of statistical regularities in language, as participants naturally favor sequences that align with known patterns, even when meaning is inaccessible. To operationalize this, the authors introduce a corpus-based algorithm called the "bracelet method," which models sentence construction as a chain of co-occurrence dependencies. As shown in the figure below, this method treats each word as a "pearl" that must be threaded into a sequence based on its compatibility with the preceding word, using bigram co-occurrence frequencies derived from a corpus. The process is illustrated with a visual metaphor of threading cards together, where the presence of a word at the beginning of a sentence is validated by its frequency in the corpus, and subsequent choices are guided by the likelihood of adjacent word pairs. This step emphasizes the importance of data-driven models in capturing linguistic probability, contrasting human intuitive knowledge with machine learning's reliance on statistical evidence.
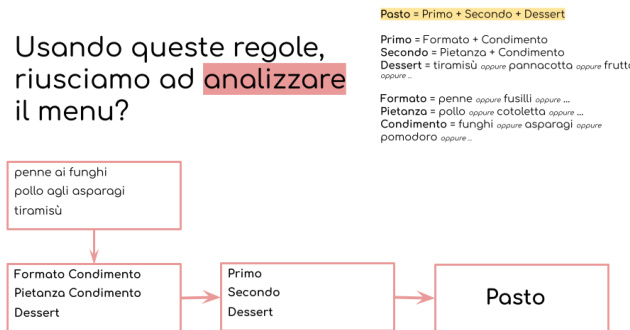
To extend the discussion beyond statistical models, the authors introduce formal grammatical structures using a restaurant menu metaphor. This module shifts focus from probabilistic patterns to rule-based generation, demonstrating how a system of syntactic rules can define valid sentence structures. The framework presents a set of example menus, each composed of a first course, second course, and dessert, and asks participants to infer the underlying grammar that governs valid combinations. As illustrated in the figure below, the process involves defining recursive rules that decompose a "meal" into its constituent components, allowing for both validation of new menu combinations and generation of novel ones. This analogy is directly mapped to linguistic grammar, where syntactic rules govern the composition of phrases and sentences. To reinforce this, participants are provided with annotated materials—such as felt strips and cards representing parts of speech—and are tasked with extracting rules from a corpus. These rules, which encode valid syntactic configurations, are then used to generate new sentences from a set of unfamiliar words, bridging the gap between pattern recognition and rule-based language modeling.
The integration of these two modules—statistical modeling via the bracelet method and rule-based generation through grammatical abstraction—forms a cohesive pedagogical architecture. The authors combine physical interaction with conceptual abstraction, allowing participants to engage with language processing at both the empirical and theoretical levels. The final activity, shown in the figure below, involves applying the extracted grammatical rules to generate new sentences from a set of unannotated words. This step emphasizes the interplay between data and structure, where statistical evidence informs rule discovery, and rules enable systematic generation. The use of color-coded components and modular materials supports a tangible understanding of linguistic categories and their combinations. Together, these modules illustrate how computational models of language can be understood as either data-driven systems or rule-based systems, each capturing different aspects of linguistic knowledge.

Experiment
This interactive workshop was designed to introduce computational linguistics principles to middle and high school students and the general public through hands-on, puzzle-based activities delivered in both face-to-face and online formats. The evaluation validated the approach as an effective pedagogical tool for raising awareness about language technology and framing linguistic study as a scientific discipline. Qualitative feedback revealed consistently high engagement and curiosity across all settings, though shorter sessions risked reducing the experience to mere puzzle-solving rather than fostering deeper linguistic analysis. Overall, the program successfully sparked sustained interest in natural language processing and artificial intelligence, establishing a strong foundation for future educational outreach and competitive initiatives.