Command Palette
Search for a command to run...
Music SketchNet : Génération de musique contrôlable via des représentations factorisées de la hauteur et du rythme
Music SketchNet : Génération de musique contrôlable via des représentations factorisées de la hauteur et du rythme
Ke Chen Cheng-i Wang Taylor Berg-Kirkpatrick Shlomo Dubnov
Déploiement en un clic de DiffRhythm : Générez une démo musicale complète en 1 minute
Résumé
En tirant une analogie avec les systèmes de complétion d’images automatiques, nous proposons Music SketchNet, un cadre de réseau neuronal permettant aux utilisateurs de spécifier des idées musicales partielles guidant la génération automatique de musique. Nous nous concentrons sur la génération des mesures manquantes dans des pièces musicales monophoniques incomplètes, conditionnées par le contexte environnant, et éventuellement guidées par des extraits de hauteur et de rythme spécifiés par l’utilisateur. Premièrement, nous introduisons SketchVAE, un autoencodeur variationnel novateur qui factorise explicitement le rythme et le contour de la hauteur pour constituer la base de notre modèle proposé. Ensuite, nous présentons deux architectures discriminatives, SketchInpainter et SketchConnector, qui, conjointement, assurent la complétion musicale guidée, en remplissant les représentations des mesures manquantes conditionnées par le contexte environnant et les extraits spécifiés par l’utilisateur. Nous évaluons SketchNet sur un jeu de données standard de musique folklorique irlandaise et le comparons aux modèles issus de travaux récents. Lorsqu’il est utilisé pour la complétion musicale, notre approche surpasse l’état de l’art tant en termes de métriques objectives que de tests d’écoute subjectifs. Enfin, nous démontrons que notre modèle peut intégrer avec succès les extraits spécifiés par l’utilisateur pendant le processus de génération.
One-sentence Summary
Music SketchNet is a controllable music generation framework that employs the SketchVAE to factorize pitch contours and rhythm, while the SketchInpainter and SketchConnector architectures guide the completion of missing measures in monophonic pieces conditioned on surrounding context and optional user-specified snippets, achieving state-of-the-art performance on a standard Irish folk music dataset across both objective metrics and subjective listening tests.
Key Contributions
- The paper introduces Music SketchNet, a neural network framework that generates missing measures in incomplete monophonic pieces by conditioning on surrounding context and optional user-specified pitch and rhythm sketches.
- The architecture employs SketchVAE to explicitly factorize latent representations into decoupled pitch contour and rhythm components, which are processed by SketchInpainter and SketchConnector modules to integrate user inputs during generation.
- Evaluations on a standard Irish folk music dataset demonstrate that the framework outperforms recent state-of-the-art models in both objective metrics and subjective listening tests while successfully accommodating optional user specifications.
Introduction
Neural networks have significantly advanced automatic music generation, yet enabling intuitive user control remains critical for practical creative applications. Prior conditional generation methods typically require users to provide complete musical tracks or rely on basic note constraints, while existing inpainting techniques lack explicit user guidance. The authors leverage a sketching paradigm adapted from computer vision to introduce Music SketchNet, a framework that decouples musical measures into distinct pitch contour and rhythm latent variables using a factorized variational autoencoder. This architecture allows creators to specify partial musical ideas, which the model seamlessly integrates with context-aware predictions to produce highly controllable compositions.
Method
The proposed framework, Music SketchNet, is designed to enable guided music generation by completing missing measures in monophonic musical pieces based on surrounding context and optional user-specified pitch and rhythm snippets. The architecture is built upon three core components: SketchVAE, SketchInpainter, and SketchConnector, which together form a hierarchical system for encoding, predicting, and refining latent representations of music.
At the foundation of the system is the SketchVAE, which serves as a factorized variational autoencoder for music representation. It explicitly separates pitch and rhythm information into distinct latent dimensions, zpitch and zrhythm, allowing for independent control and manipulation. The SketchVAE processes a music measure by first encoding it into two separate token sequences: xpitch, which contains note values with padding to fill a 24-frame measure, and xrhythm, which captures duration and onset information by replacing pitch events with rhythm-specific tokens. These sequences are then independently encoded using two separate GRU-based encoders—Qθ for pitch and Qτ for rhythm—whose outputs are concatenated to form the full latent variable z=[zpitch,zrhythm]. The hierarchical decoder Pϕ reconstructs the original music from this latent representation by first decoding the measure into beats using a "beat" GRU layer, and then decomposing each beat into individual ticks using a "tick" GRU layer. This two-stage decoding process ensures that the output is generated in a musically intuitive manner. Refer to the framework diagram  for a visual overview of the SketchVAE structure, including its encoder and hierarchical decoder.
for a visual overview of the SketchVAE structure, including its encoder and hierarchical decoder.
The SketchInpainter component is responsible for generating initial predictions for the missing measures by leveraging the surrounding musical context. It takes as input the latent sequences from the past and future contexts, Zp and Zf, and processes them separately for pitch and rhythm using two independent GRU groups. The final hidden states from these encoders, ht1 and ht3, are used as initial states for two separate generation GRUs—the pitch generation GRUs and rhythm generation GRUs. These generation GRUs predict the missing latent representations, Sm=(Spitch,Srhythm), in an auto-regressive manner, conditioned on the contextual information. The predicted latent sequences are then fed into the SketchVAE decoder to produce a music output, which is used to compute the cross-entropy loss during training. This initial prediction step establishes a strong baseline for the missing music material.
To incorporate user guidance and refine the initial prediction, the SketchConnector module is introduced. This component modifies the latent predictions from the SketchInpainter by integrating user-specified sketching information, denoted as C. The process begins by concatenating the predicted Sm with the past and future latent sequences, followed by a random unmasking procedure where a portion of the predicted latent variables (set at a 0.3 rate) are replaced with ground-truth values, simulating user-provided context. This mechanism, which is analogous to BERT-style training but with unmasking rather than masking, encourages the model to learn stronger correlations between adjacent musical elements. The unmasked data and the predicted Sm are then fed into a transformer encoder with absolute positional encoding, which produces the final refined latent representation Zm for the missing measures. This refined latent variable is subsequently decoded by the SketchVAE to generate the final music output. As shown in the figure below, the SketchConnector acts as a final refinement step, ensuring that the generated music aligns with both the contextual cues and the user's specified sketching input 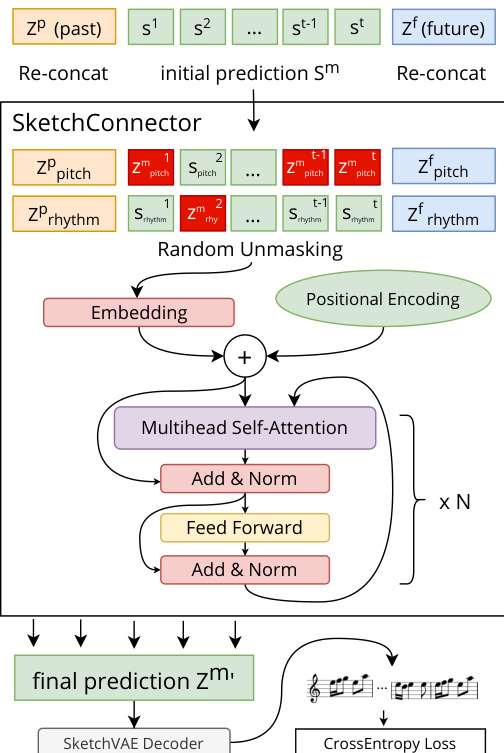 .
.
Experiment
The evaluation compares SketchNet against established baselines using objective generation metrics, subjective human listening tests, and an interactive control scenario to validate its inpainting capabilities. Objective and subjective results demonstrate that the model consistently outperforms competitors in pitch accuracy and overall musicality, effectively capturing repetitive patterns while maintaining contextual coherence in non-repetitive passages. Human listeners particularly appreciate the improved structural integrity and harmonic quality of the generated melodies, despite similar note complexity. Additionally, interactive experiments confirm that the system reliably follows user-specified pitch and rhythm sketches, proving its effectiveness as a highly controllable music generation tool.
The authors evaluate the SketchNet model by comparing it with baseline systems, focusing on pitch and rhythm accuracy in generated melodies. The experiment includes a virtual control test to assess how user-specified rhythm and pitch information influence the model's output. Results show that the model achieves high accuracy in following user control for both rhythm and pitch, with better performance in pitch following. SketchNet demonstrates superior performance compared to baseline models in generating melodies with accurate pitch and rhythm. The model effectively follows user-specified rhythm and pitch controls, with high accuracy in both cases. User control significantly influences the generated output, as shown by high accuracy in matching specified rhythm and pitch patterns.
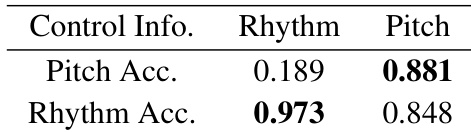
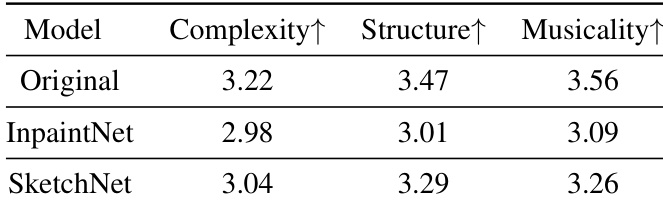
The authors compare SketchNet with Music InpaintNet and other baselines, evaluating performance through objective metrics and subjective listening tests. Results show that SketchNet outperforms other models in generating melodies, particularly in structure and overall musicality, while maintaining comparable complexity. The model also demonstrates effective control over pitch and rhythm in interactive scenarios. SketchNet achieves higher structure and musicality scores compared to InpaintNet in subjective evaluations. The model shows improved performance over baselines in both repetition and non-repetition test subsets. User control over pitch and rhythm leads to targeted generation, with high accuracy in following specified inputs.
The authors evaluate SketchNet against several baselines, including Music InpaintNet and variations of SketchVAE, across different test subsets. Results show that SketchNet consistently outperforms other models in terms of both accuracy and loss, particularly in non-repetition scenarios where copying is not viable. The model demonstrates strong control over generated melodies through user-specified pitch and rhythm cues. SketchNet achieves the best performance across all test subsets, outperforming all baseline models in both accuracy and loss metrics. Performance improvements are more pronounced in pitch accuracy than rhythm accuracy, especially in non-repetition scenarios. User-controlled pitch and rhythm inputs significantly influence the generated output, with high accuracy in following specified controls.
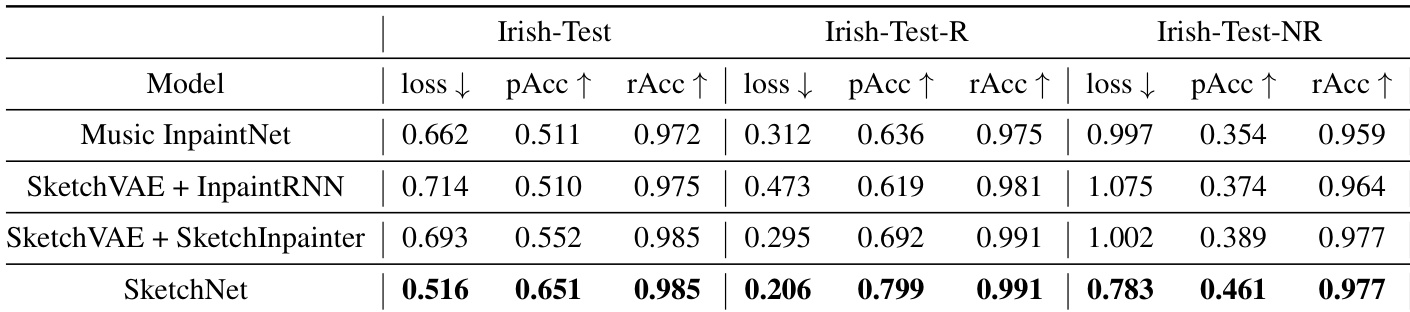
The evaluation compares SketchNet against multiple baseline systems using objective metrics and subjective listening tests across repetition and non-repetition scenarios to validate its capacity for generating musically coherent melodies under user-defined pitch and rhythm constraints. Results consistently indicate that SketchNet surpasses competing approaches in structural integrity and overall musicality while maintaining precise adherence to user-specified controls. The model proves particularly effective in interactive generation tasks, where user cues significantly shape the output and yield stronger pitch alignment than rhythm tracking, especially within complex non-repetition contexts.