Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Extraction de sentiments : Compréhension des métriques et analyse exploratoire des données
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
The authors apply exploratory analytics and sentiment analysis to a dataset filtered to over 18,000 tweets, identifying endogenous drivers (content, sentiment, motive, and richness) and exogenous factors (fundamental events, social learning, and activism) that shape viral propagation, and present an early-stage model to explain tweet performance.
Key Contributions
- This study analyzes a filtered dataset of over 18,000 tweets to identify key drivers of viral content across endogenous dimensions, including content, sentiment, and motive, as well as exogenous factors such as fundamental events and social learning.
- The analysis reveals counter-intuitive behavioral patterns, demonstrating that non-verified and shorter-aged accounts exhibit a positive association with tweet popularity compared to established profiles.
- An early-stage predictive model quantifies how limited text length and strategic hashtag usage significantly increase retweet likelihood, offering empirical guidelines for optimizing organizational information dissemination on social media platforms.
Introduction
The authors examine how emotional tone, information richness, and content structure drive tweet popularity, a critical factor for organizations seeking to optimize digital communication and marketing strategies. Prior research has established clear links between sentiment and engagement, yet the field struggles with inconsistent definitions of viralness and leaves numerous platform-specific variables unexamined. To address these gaps, the authors conduct an exploratory analysis to isolate the user and message attributes that most strongly correlate with viral propagation. They develop an early-stage model that confirms both account characteristics and tweet composition influence virality, uncover counterintuitive patterns such as higher engagement from newer or unverified accounts, and recommend concise messaging paired with strategic hashtag usage to maximize retweets.
Dataset

- Dataset composition and sources: The authors collect raw Twitter data through the official API using two dedicated accounts, leveraging R's
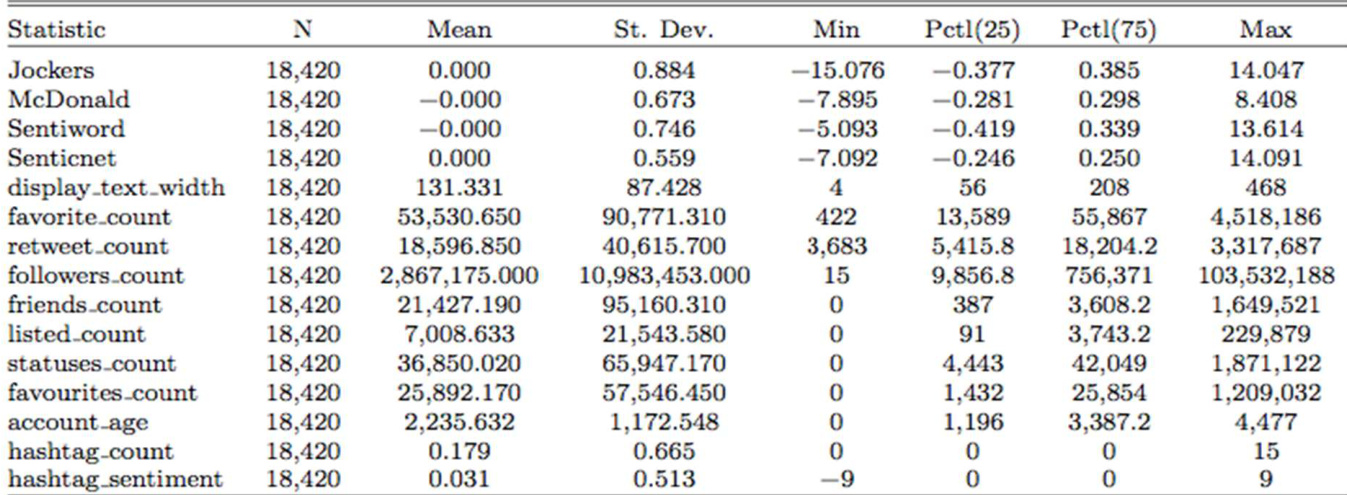
rtweetpackage to structure requests and parse JSON responses. Initial extraction yields over one million tweets containing 80+ variables, which are temporarily stored in a MySQL database before final analysis. - Subset details and filtering rules: The collection pipeline runs two concurrent scripts for keyword-based retweets and trending topics, each limited to 15,000 tweets per download cycle. The authors restrict the data to US-based English tweets with English account languages, exclude posts with zero engagement, and retain only the top 75% by retweet volume. This filtering produces a final curated subset of 18,420 unique tweets collected throughout November 2018.
- Data usage and modeling approach: The full filtered dataset is used for exploratory factor analysis and regression modeling to identify drivers of tweet viralness, with no explicit training or testing split. The authors apply factor analysis to condense numerical and sentiment variables, ultimately selecting the Jockers and Sentiword sentiment factors alongside their squared terms to capture curvilinear relationships with engagement metrics.
- Metadata construction and processing: Device metadata is constructed by scanning the source field for platform-specific keywords, categorizing each tweet as Mobile, Desktop, or Other. The raw 13.5GB dataset is compressed to 2GB using R's
.rdsformat, and additional features such as text display width, engagement counts, account age, and temporal indicators are standardized for the final regression pipeline.
Experiment
This exploratory regression analysis of cross-sectional Twitter data validates how specific account characteristics and content strategies influence retweet probability. The qualitative findings indicate that newer, non-verified accounts with higher posting volumes and extensive following networks achieve greater engagement, whereas longer text, verified status, and excessive interaction through liking others consistently reduce retweet likelihood. Ultimately, the study concludes that optimizing content brevity, incorporating visual media, and strategically prioritizing network connections outperform traditional verification or sentiment-driven approaches, though the single-month timeframe warrants future longitudinal validation.
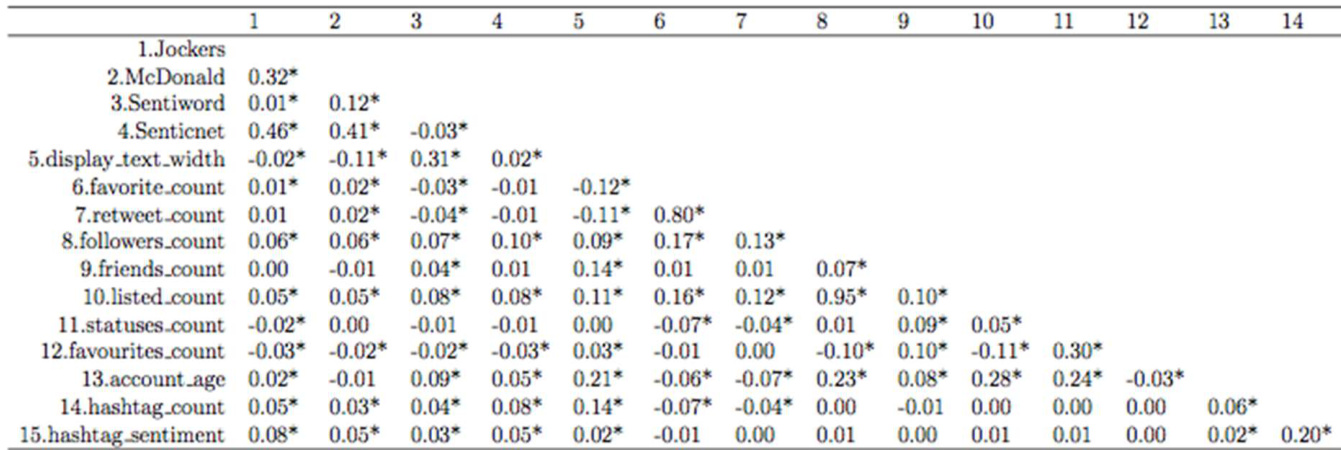
The authors analyze factors influencing retweet counts using regression models and examine descriptive statistics from a dataset. Results show that account age, display text width, and certain sentiment metrics have notable associations with retweet behavior, while verified status and user activity metrics reveal unexpected relationships. The analysis highlights differences in retweet likelihood between verified and unverified accounts, and emphasizes the role of network engagement and content characteristics. Verified accounts are less likely to be retweeted compared to unverified accounts, contrary to initial expectations. Tweets with photos are more likely to be retweeted, while longer text tweets are less likely to be retweeted. The number of followers and friends positively affects retweet count, but the number of liked tweets negatively impacts retweet likelihood.
The authors analyze the factors influencing retweet counts using OLS, Poisson, and Negative Binomial models, finding that account age and display text width have negative associations with retweets, while follower count and certain sentiment measures show complex relationships. Verified accounts and tweet length exhibit unexpected negative effects, and photo inclusion and user network activity positively influence retweet likelihood. The results highlight differences across models, particularly in the significance and direction of effects for verified status and other variables. Account age and display text width are negatively associated with retweet counts across all models. Verified accounts show a negative relationship with retweets in Poisson and Negative Binomial models, contrary to OLS findings. Photo inclusion and user network activity, such as following others, are positively associated with retweet likelihood.

The authors analyze the factors influencing retweet counts using multiple regression models, examining variables such as sentiment scores, account characteristics, and tweet content. Results show that certain sentiment metrics have nonlinear relationships with retweet counts, while account age and text length exhibit negative associations. Verified accounts and favoriting activity are found to have counterintuitive effects on retweet likelihood, with unverified accounts and shorter tweets being more likely to be retweeted. Sentiment scores exhibit nonlinear relationships with retweet counts, with some lexicons showing positive quadratic effects and others negative quadratic effects. Older accounts and longer tweets are associated with lower retweet counts, while unverified accounts and shorter text are more likely to be retweeted. Favoriting activity and account verification status have counterintuitive negative associations with retweet counts, suggesting complex social dynamics at play.
The experiments employ multiple regression frameworks to validate how account attributes, tweet content, sentiment, and network engagement shape retweet behavior. Results consistently indicate that older accounts and longer text suppress virality, whereas photo inclusion and active network participation significantly enhance retweet likelihood. Counterintuitively, verified status and favoriting activity demonstrate negative associations across models, highlighting complex social dynamics that contradict conventional expectations. Additionally, sentiment metrics exhibit nonlinear effects on retweet counts, emphasizing the nuanced role of emotional tone in content dissemination.