Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Déploiement en un clic de Mellum-4b-base : un modèle conçu pour la complétion de code
Résumé
Please provide the title and abstract you would like me to translate.
One-sentence Summary
The authors propose a sequence model for modern IDE code completion that prioritizes practical deployment constraints over next-token prediction accuracy by ensuring type-checking validity, delivering instantaneous inference, and maintaining a compact disk and memory footprint for local offline use, unlike prior deep neural networks optimized solely for predictive metrics.
Key Contributions
- A partial token language model is introduced to satisfy practical IDE constraints by generating type-valid suggestions, returning instantaneous results, and maintaining a compact disk and memory footprint.
- A rigorous data preprocessing pipeline eliminates duplicate examples across training and test splits to prevent artificially inflated accuracy metrics.
- Evaluation on an open-source GitHub Dart corpus demonstrates that the model achieves higher next-token prediction accuracy than prior pointer network-based approaches.
Introduction
Code completion has evolved into a critical IDE feature that accelerates typing, verifies correctness, and streamlines API navigation, yet developers demand instantaneous suggestions that fit within strict latency and local compute constraints. Prior machine learning approaches, ranging from n-gram models to recurrent networks and pointer architectures, have improved contextual ranking but consistently struggle with out-of-vocabulary identifiers, limited workstation memory, and guaranteeing syntactically valid output. Additionally, inconsistent evaluation protocols and undetected dataset duplication have historically inflated accuracy metrics across studies. The authors address these bottlenecks by introducing a partial token language model specifically optimized for modern IDE environments, which achieves state-of-the-art prediction accuracy on a rigorously deduplicated Dart corpus while carefully balancing inference speed, model size, and output validity.
Dataset
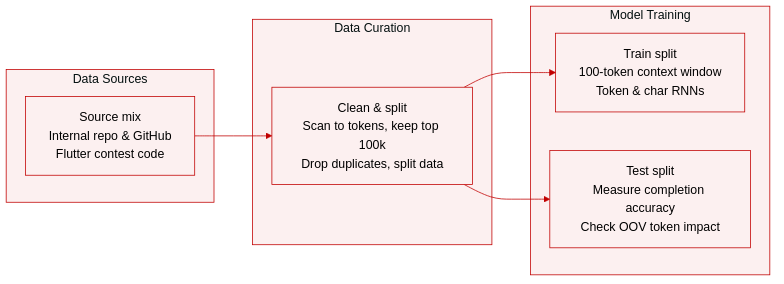
- Dataset Composition and Sources: The authors evaluate three distinct Dart corpora to analyze vocabulary overlap and autocompletion performance. The first is an internal repository from a large software company, the second consists of open-source Dart code hosted on GitHub, and the third contains submissions from a Flutter mobile application development contest.
- Subset Details and Filtering: The Internal corpus primarily features AngularDart web applications and exhibits an 80 percent unique vocabulary rate. The GitHub corpus contains general-purpose Dart frameworks and libraries without company-specific references, showing a 71 percent unique vocabulary rate. The Flutter Create corpus is smaller but highly diverse, containing mobile apps constrained to 5kb of Dart. It has a 54 percent unique vocabulary rate and contains fewer than 100,000 total unique tokens.
- Data Processing and Model Usage: The authors apply a token scanner to convert source files into token lists and select the most frequent 100,000 tokens for the output vocabulary. Rare tokens are replaced with a special placeholder symbol to stabilize training. To prevent data leakage from widespread code duplication, exact duplicate sequences are removed. Each corpus is divided into training and test splits, and two separate RNNs are trained per dataset, one processing token sequences and the other processing character sequences.
- Context Window and Training Strategy: The authors construct next-token prediction examples using a fixed 100-token context window. Each keyword, identifier, or literal serves as the target label for the preceding 100 inputs. Although the corpora share only about 13 percent of their combined vocabulary, the overlapping tokens account for over 90 percent of the overall probability mass, demonstrating that a fixed output vocabulary combined with local references remains effective for code completion.
Method
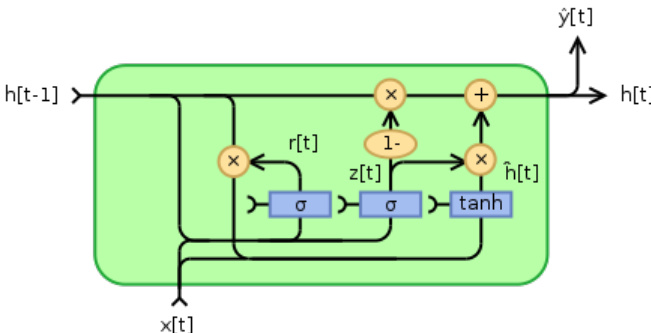
The authors leverage a hybrid neural architecture designed to balance predictive accuracy with the stringent performance constraints of interactive code completion systems. The core framework combines a character-level input representation with a token-level output, enabling the model to predict entire tokens while still capturing the fine-grained patterns of source code. This design allows the model to meaningfully represent out-of-vocabulary (OOV) tokens through local repetition detection, a mechanism that assigns probability to tokens appearing in the input sequence. The overall architecture is built upon a recurrent neural network (RNN) using Gated Recurrent Unit (GRU) cells to handle sequential dependencies, with a projection layer between the hidden state and the output softmax to reduce prediction latency and model size. As shown in the figure below, the GRU cell integrates the current input with the previous hidden state through a reset gate and an update gate, allowing the network to selectively retain or forget information and effectively manage long-term dependencies in code sequences.
The model's input representation is a critical component of its design. To address the challenge of processing long sequences within the limited memory capacity of RNNs, the authors employ subtoken encoding, breaking identifier names into morphemes based on camelCase and snake_case conventions. This approach, illustrated in Figure 4, allows the model to process a longer context of preceding code in fewer time steps compared to a pure character-level input. The subtoken encoding enables the model to relate related lexemes, such as "ResourceProvider" and "FileResourceProvider," by treating them as sequences of shared morphemes. This strategy is a direct response to the limitations of pure character-level models, which require a large number of time steps to represent a single token and are computationally expensive.
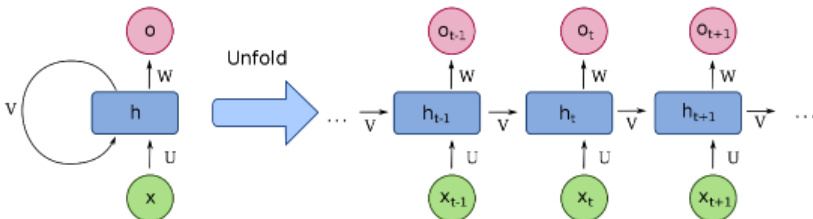
To generate predictions, the model processes a sequence of tokens from the code context preceding the cursor. For the token-level model, this sequence is directly fed into the network. For the subtoken model, each token is first split into its constituent subtokens. The network then unrolls over this sequence, producing a hidden state at each time step. The final hidden state is projected through a linear layer and fed into a softmax layer to compute a probability distribution over the output vocabulary. A key innovation is the integration of a separate, auxiliary network that predicts the probability of local repetition. This network shares the same input and hidden representations as the main language model but uses a sigmoid function to output a single probability value. During prediction, this probability is used to reweight the main model's output distribution, scaling the probability mass assigned to tokens from the input sequence to the repetition probability and the rest to one minus that probability. This mechanism allows the model to assign non-zero probability to OOV tokens that repeat from the context, effectively leveraging the frequent occurrence of local repetition in source code. The final prediction is a combination of the model's output and the results from static analysis, which enumerates valid keywords and in-scope identifiers, ensuring that the suggestions are both accurate and syntactically valid.
Experiment
The evaluation assessed model quality through top-k accuracy measurements across multiple corpora and architectures, alongside a latency benchmark designed to simulate realistic prediction workloads. Results indicate that the partial token architecture consistently outperforms standard token models, with predictive capability scaling positively alongside training data volume and significantly exceeding static analysis baselines. The integrated repetition detection mechanism effectively identifies recurring tokens and recalibrates probability distributions with high reliability. Additionally, post-training quantization successfully optimized inference speed to meet interactive latency targets, confirming that the current model size is well-suited for user experience while highlighting the impracticality of multi-subword prediction approaches for real-time code completion.
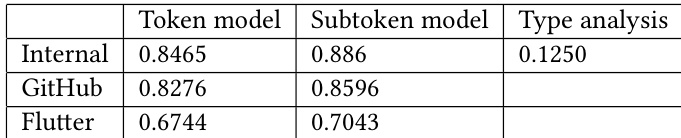
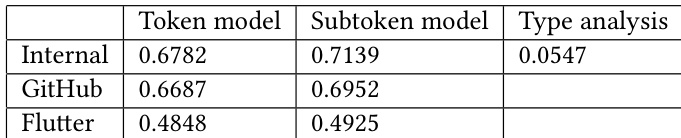
The authors compare two model variants, a token model and a subtoken model, across different code corpora, showing that the subtoken model achieves higher accuracy. Results indicate that model performance improves with larger corpus size, and the subtoken model consistently outperforms the token model across all datasets. The evaluation also includes latency benchmarks, demonstrating significant speed improvements after post-training quantization, with most requests completing under a target threshold. The subtoken model outperforms the token model in accuracy across all corpora. Accuracy increases as the corpus size grows, with the subtoken model showing consistent improvements. Post-training quantization reduces prediction latency, with most requests completing under a target threshold.
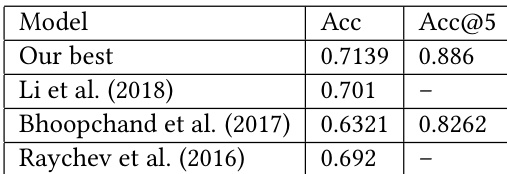
The authors compare their model against state-of-the-art approaches using accuracy metrics, showing that their model achieves higher performance. Results indicate that the model's predictive ability improves with larger corpus sizes and outperforms existing methods in both top-1 and top-5 accuracy. The model also meets latency requirements after quantization, suggesting it is optimized for real-time use. the model achieves higher top-1 and top-5 accuracy compared to prior work. The model's performance improves with larger corpus sizes and outperforms existing approaches. Post-training quantization reduces prediction latency, enabling real-time use within target limits.
The authors evaluate two model variants across three corpora, showing that the subtoken model outperforms the token model in accuracy, with improvements observed as corpus size increases. Performance benchmarks indicate that post-training quantization significantly reduces prediction latency, bringing it close to a target threshold while maintaining efficiency. The subtoken model achieves higher accuracy than the token model across all corpora. Accuracy improves with larger corpus size for both model variants. Post-training quantization reduces prediction latency, with most requests completing under 110ms.
The evaluation compares token and subtoken model variants across multiple code corpora while benchmarking inference latency against state-of-the-art approaches. Results demonstrate that the subtoken architecture consistently yields superior accuracy, with predictive performance scaling positively as training data volume increases. Furthermore, latency benchmarks confirm that post-training quantization effectively optimizes inference speed, enabling real-time deployment without compromising model reliability. Collectively, these experiments validate the architectural advantages of subtoken modeling and the practical viability of quantization for production environments.