Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Introduction intuitive à la traduction automatique neuronale avec les mécanismes d'attention de Bahdanau et Luong
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
A trivial transfer learning method for low-resource neural machine translation trains a high-resource parent model and continues training on a low-resource pair solely by replacing the training corpus, yielding a child model that significantly outperforms baselines across unrelated languages and different alphabets without requiring shared target languages or linguistic relatedness.
Key Contributions
- This work introduces a simplified transfer learning approach for neural machine translation, where a child model continues training on a low-resource language pair by replacing the training corpus of a high-resource parent model without specialized preprocessing or altered training schedules.
- The method extends transfer learning beyond prior constraints by demonstrating effective knowledge transfer across unrelated languages with different alphabets and by allowing the target language to change between parent and child models.
- Experiments utilizing the Transformer architecture demonstrate that the adapted child models significantly outperform baselines trained exclusively on the low-resource data.
Introduction
Neural machine translation delivers state-of-the-art results but consistently fails when parallel training data falls below one million sentences. Transfer learning addresses this low-resource bottleneck by reusing knowledge from high-resource language pairs, yet prior approaches typically demand shared target languages, linguistic relatedness, or complex training adjustments and specialized preprocessing. The authors leverage a streamlined transfer learning strategy built on the Transformer architecture to train a parent model on a high-resource pair and seamlessly continue training on a low-resource pair simply by swapping the dataset. This method delivers significant performance gains across unrelated languages with different scripts and even when the target language changes, all without requiring custom training regimes or data manipulation.
Dataset

- Dataset Composition and Sources: The authors assemble a multilingual training corpus spanning low-resource, high-resource, and unrelated language pairs to evaluate transfer learning in neural machine translation. The dataset primarily draws from WMT shared tasks, Europarl, Rapid, CzEng 1.7, News Commentary, Yandex, and the UN corpus. Estonian-English and Slovak-English serve as the low-resource targets, while Finnish-English and English-Czech act as high-resource baselines. Russian-English functions as the parent model source, and Arabic-Russian, French-Russian, Spanish-French, and Spanish-Russian pairs evaluate cross-lingual transfer to unrelated languages.
- Subset Details:
- Estonian-English: Trained on Europarl and Rapid data; validated and tested on WMT news 2018.
- Finnish-English: Prepared following established protocols with Wikipedia headlines removed; validated and tested on WMT news 2015.
- English-Czech: Built from WMT2018 permitted parallel data excluding Paracrawl, supplemented by filtered CzEng 1.7; validated on WMT newstest2011 and tested on WMT newstest2017.
- Slovak-English: Sourced from Galuščákova and Bojar (2012) and detokenized with Moses; validated and tested on WMT newstest2011.
- Russian-English: Compiled from News Commentary, Yandex, and UN Corpus; validated on WMT newstest 2012.
- Unrelated pairs: Sourced entirely from the UN corpus.
- Exact training sentence counts vary by language pair and are documented in the paper reference table.
- Data Usage and Processing: The authors generate a shared sub-word vocabulary by concatenating parent and child training corpora. They enforce a strict 1:1 sentence ratio during vocabulary construction to balance both language pairs. The tokenization targets approximately 32k sub-word types, yielding actual vocabulary sizes between 26.1k and 34.8k. All experiments within a given language set share this identical vocabulary. Byte pair encoding or wordpieces are applied to manage out-of-vocabulary terms and optimize sequence efficiency.
- Filtering and Cropping Strategy: Training sentences containing fewer than 4 or more than 75 words on either the source or target side are removed. This length capping accelerates Transformer training and enables larger batch sizes without negatively impacting translation quality. Development and test sets remain unfiltered to preserve evaluation fidelity. The authors also exclude the Paracrawl corpus across relevant pairs due to noise concerns.
Method
The authors leverage a straightforward transfer learning approach for neural machine translation (NMT) that involves training a model on a high-resource language pair—referred to as the parent—before continuing training on a low-resource language pair—referred to as the child—without resetting any model parameters or hyperparameters. This method mirrors the transfer learning framework introduced by Zoph et al. (2016), but differs by employing a shared subword vocabulary across both language pairs, as proposed by Nguyen and Chiang (2017). The key innovation lies in removing the constraint that the parent and child language pairs must be related, demonstrating that effective transfer can occur even between fully unrelated language pairs. This approach is applicable to both source and target language sides, not restricted to cases where the target language is shared.
The method requires no modifications to existing NMT frameworks. The only necessary condition is the use of a shared subword vocabulary, which is constructed using word-piece segmentation (Johnson et al., 2017) trained on the concatenated source and target sides of both the parent and child language pairs. The vocabulary is shared across both the encoder and decoder in the Transformer architecture, enabling potential information reuse. During training, the model is first trained on the parent language pair until convergence. This trained model is then used as the initialization for training on the child language pair, with only the training corpus being switched. All other training parameters remain unchanged throughout the process.
Experiment
The evaluation utilizes a Transformer sequence-to-sequence model to assess transfer learning across various high-resource parent and low-resource child language pairs. The experiments demonstrate that finetuning parent models substantially improves child translation quality, revealing that performance gains are driven primarily by the volume of parent training data rather than linguistic relatedness or shared scripts. The approach proves effective even with extremely limited child datasets and when translation directions are reversed or no languages are shared, as long as the parent model has fully converged. Ultimately, the findings confirm that leveraging larger pre-trained models is a highly reliable strategy for deploying neural machine translation in low-resource environments.
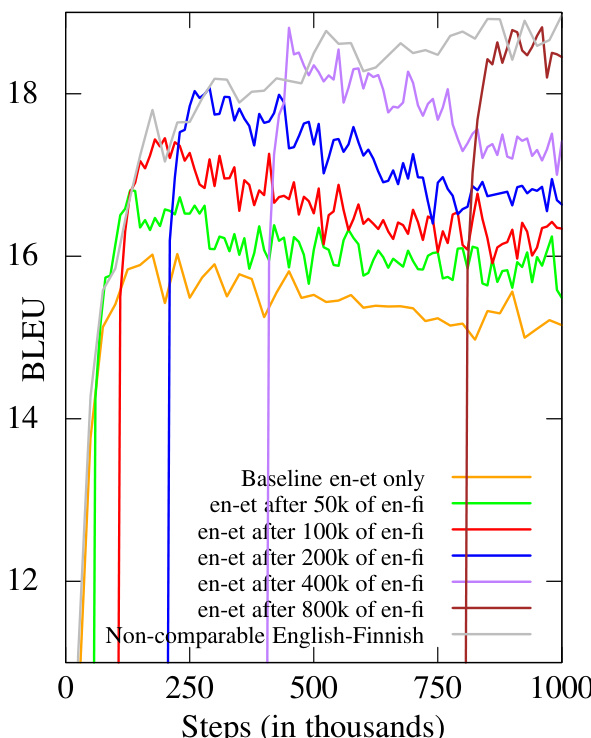
The authors investigate transfer learning in neural machine translation by training a child model on reduced data while initializing it with a pre-trained parent model. Results show that the transfer learning approach consistently outperforms the baseline model across various levels of child training data, with performance improving as the amount of child data increases. The gains are not solely due to longer output lengths, as improvements are also seen in n-gram precisions and the introduction of new, contextually appropriate tokens. Transfer learning consistently improves translation performance compared to training from scratch on reduced data The improvement is more pronounced with larger amounts of child training data The gains are not due to longer outputs alone, as n-gram precisions also improve
The authors compare translation performance of a child model trained from scratch versus one initialized with a parent model, using various metrics. Results show that initializing with a parent model leads to improvements across multiple evaluation measures, with the best-performing setup achieving higher scores in BLEU, nPER, nTER, nCDER, chrF3, and nCharacterTER compared to the baseline. Initializing the child model with a parent model improves translation quality across multiple metrics. The best-performing setup achieves higher scores in BLEU, nPER, nTER, nCDER, chrF3, and nCharacterTER than the baseline. The improvements are consistent across different evaluation measures, indicating robust gains from transfer learning.

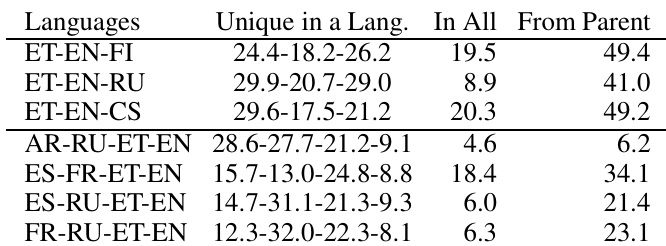
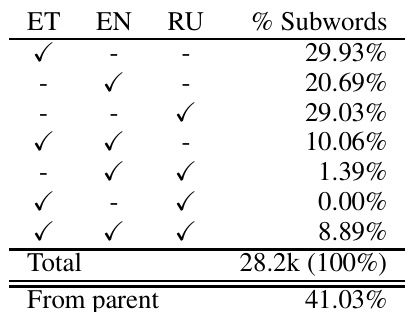
The authors analyze the composition of subword vocabulary in translation experiments involving Estonian, English, and Russian, focusing on the contribution of each language to the total vocabulary. The results indicate that the parent model contributes a significant portion of the vocabulary, with substantial overlap between the languages in the subword units used. The analysis reveals that the majority of the vocabulary comes from the parent model, suggesting that transfer learning leverages the parent's linguistic resources effectively. The parent model contributes the majority of the subword vocabulary in the experiments. There is a significant overlap in subword units between the languages, especially between English and Estonian. The total vocabulary is dominated by contributions from the parent model, indicating effective transfer of linguistic resources.
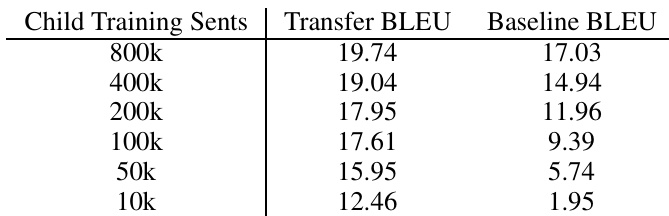
The authors evaluate transfer learning in neural machine translation by using a parent model to improve a child model, with results showing consistent gains across various language pairs. The performance improvements are observed even when the parent and child languages share no common vocabulary or are unrelated, indicating that the size of the parent corpus plays a more significant role than language relatedness. The results also highlight that the transfer learning method is effective in low-resource settings and benefits from a converged parent model. Transfer learning consistently improves translation performance across different language pairs, even when the languages are unrelated. The size of the parent training data is more important than language relatedness for achieving performance gains. The method is effective in low-resource scenarios and benefits from a well-trained parent model.
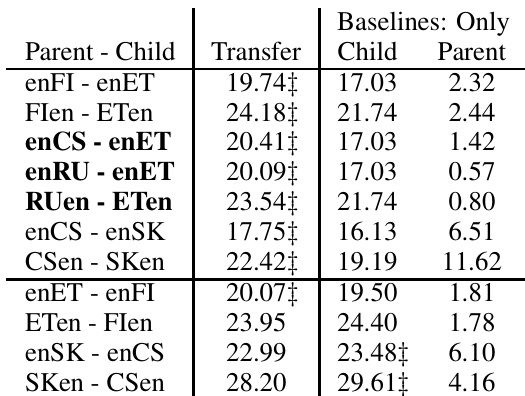
The authors analyze the impact of transfer learning on translation performance by comparing baseline models with those initialized using a parent model. Results show that the transfer learning approach leads to improvements in BLEU scores and output length, with gains primarily attributed to better n-gram precision rather than increased output length. The improvements are consistent across different parent models, indicating that the size of the parent corpus plays a significant role in enhancing translation quality. Transfer learning improves BLEU scores and output length compared to baseline models. The gains are mainly due to better n-gram precision rather than increased output length. The improvements are consistent across different parent models, suggesting corpus size is more important than language relatedness.

The experiments evaluate transfer learning in neural machine translation by initializing child models with pre-trained parent models and training them on varying amounts of target data. Across multiple validation phases, the approach consistently enhances translation quality, demonstrating that performance gains arise from improved n-gram precision and effective vocabulary transfer rather than increased output length. Furthermore, linguistic and cross-lingual analyses confirm that parent corpus size outweighs language relatedness in driving results, validating transfer learning as a highly effective strategy for low-resource translation scenarios.