Command Palette
Search for a command to run...
Une représentation neuronale des dessins de croquis
Une représentation neuronale des dessins de croquis
David Ha Douglas Eck
Sketch-RNN : Un modèle génératif pour les dessins vectoriels
Résumé
Nous présentons sketch-rnn, un réseau de neurones récurrents (RNN) capable de construire des dessins à base de traits d'objets courants. Le modèle est entraîné sur un ensemble de données d'images dessinées par des humains représentant de nombreuses classes différentes. Nous exposons un cadre pour la génération de croquis conditionnelle et inconditionnelle, et décrivons de nouvelles méthodes d'entraînement robustes pour générer des dessins de croquis cohérents dans un format vectoriel.
One-sentence Summary
The authors present sketch-rnn, a recurrent neural network trained on a dataset of human-drawn images across multiple classes that employs robust conditional and unconditional training frameworks to generate coherent, stroke-based, vector-format sketches of common objects.
Key Contributions
- The paper introduces sketch-rnn, a recurrent neural network trained on a large-scale collection of human-drawn vector sketches to generate stroke-based drawings of common objects. The architecture provides a unified framework for both conditional and unconditional sketch generation.
- Robust training procedures are established to stabilize the vector generation process and ensure coherent output synthesis. These methods enable direct conditioning on input sketches and facilitate smooth interpolation across object categories within the model's latent space.
- A publicly available dataset of human-drawn vector sketches is released to address prior data scarcity in generative vector drawing research. The model produces diverse, class-specific designs that support creative design and educational sketch training applications.
Introduction
While neural networks have transformed image generation through pixel-based models like GANs and autoregressive architectures, they rarely capture the sequential, abstract nature of human visual communication. Prior approaches to vector image synthesis relied on traditional statistical methods or focused on mimicking photographs rather than learning generative stroke patterns, and progress has been consistently hampered by the scarcity of large-scale public datasets. The authors leverage recurrent neural networks to model hand-drawn sketches as sequences of pen movements, introducing a robust training framework for unconditional and conditional vector generation. By exploring the model's latent space for creative interpolation and releasing a substantial open-source dataset, they establish a practical foundation for machines to learn and generate abstract visual concepts much like humans do.
Dataset
• Source and Composition: The authors construct the dataset using vector sketches from the Quick, Draw! online game, where participants draw objects within a 20-second limit. The collection spans hundreds of categories, with the authors initially selecting 75 classes for their experiments.
• Subset Breakdown: Each category is strictly partitioned into 70,000 training samples, 2,500 validation samples, and 2,500 test samples.
• Data Representation and Processing: Sketches are formatted as sequential lists of 5-element vectors. The first two elements capture relative x and y offsets from the previous point, while the final three form a one-hot vector indicating the pen state: drawing, lifting, or ending the sketch. The authors initialize the starting coordinate at the origin and apply the Ramer-Douglas-Peucker algorithm with an epsilon value of 2.0 to simplify strokes.
• Normalization and Usage: Because the original recordings use pixel dimensions, the authors normalize the offset values using a single scaling factor derived from the training set to achieve a standard deviation of 1. They intentionally skip zero-mean normalization since the original means are negligible. This processed vector sequence serves as the direct input for the model.
Method
The sketch-rnn model employs a variational autoencoder (VAE) framework with a recurrent neural network architecture designed for generating stroke-based vector drawings. The overall framework consists of an encoder-decoder structure where the encoder processes an input sketch sequence to produce a latent vector, and the decoder generates a new sketch sequence conditioned on this latent representation. Refer to the framework diagram for an overview of the model's structure.
The encoder is a bidirectional recurrent neural network (RNN) that processes the input sketch sequence S={S1,S2,…,SNs}, where each Si=(Δxi,Δyi,p1,p2,p3) represents a stroke with offset coordinates and pen states. The forward and backward RNNs process the sequence in opposite directions, producing hidden states hF and hB at each time step. The final hidden states from both directions, h−=hNsF and h+=h1B, are concatenated to form a combined representation h=[hNsF;h1B]. This representation is then passed through a fully connected layer to compute the mean μ and log-variance σ^ of the latent distribution. The latent vector z is sampled from a Gaussian distribution N(μ,σ2), where σ=exp(σ^/2), and this sampled z serves as the initial state for the decoder.
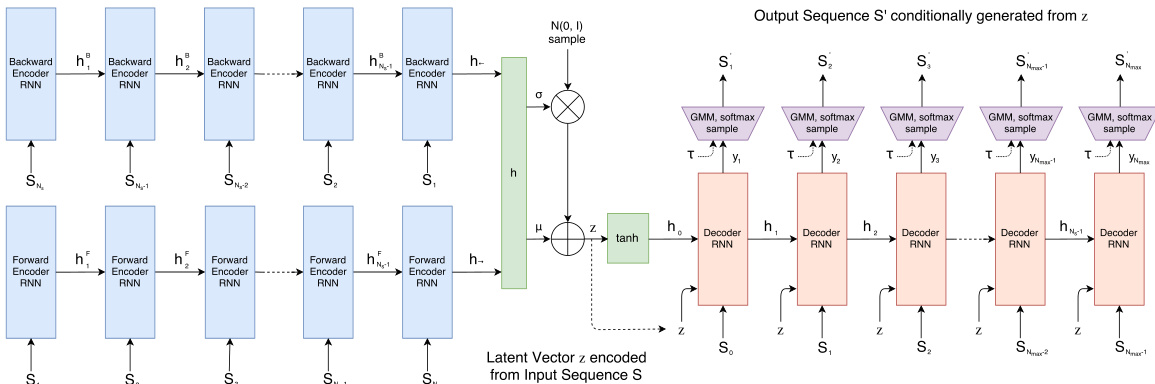
The decoder is a unidirectional RNN that generates the output sketch sequence S′ autoregressively. It takes as input the latent vector z and the previous output stroke Si−1′ at each time step. The decoder RNN's hidden state is initialized with z, and the initial pen state is determined by the model's internal logic. At each step, the decoder predicts the parameters of a mixture of Gaussians (MoG) for the (Δx,Δy) offsets and the probabilities for the pen states p1,p2,p3. The output is sampled from this distribution, and the process continues until the pen is lifted (p1=0) or the maximum sequence length is reached. The model is trained to reconstruct the input sketch sequence while also ensuring that the latent space follows a prior distribution.

The training objective is a weighted sum of two loss terms: the reconstruction loss LR and the Kullback-Leibler divergence loss LKL. The reconstruction loss is composed of two parts: Ls, which measures the log-likelihood of the offset terms (Δx,Δy) using a mixture of Gaussians, and Lp, which measures the log-likelihood of the pen state terms p1,p2,p3 using a categorical distribution. The KL divergence loss measures the difference between the learned latent distribution and a standard Gaussian prior. The total loss is Loss=LR+wKLLKL, where wKL is a hyperparameter controlling the tradeoff between reconstruction and regularization. To improve training stability, the KL loss term is annealed during training using a schedule that starts at a low value and increases over time. This annealing helps the model first focus on minimizing reconstruction error before enforcing the latent prior, leading to better overall performance.
Experiment
The Sketch-RNN model was evaluated across single and multi-class QuickDraw datasets by training with varying KL loss weights to assess how regularization impacts sketch generation and latent space organization. Experiments on conditional reconstruction, latent interpolation, and vector arithmetic demonstrate that the architecture successfully captures high-level conceptual features, enabling smooth morphing and meaningful drawing analogies. Qualitatively, higher KL regularization consistently produces more coherent and semantically structured outputs by filtering out noisy or inconsistent stroke details, whereas lower regularization prioritizes precise stroke matching at the expense of conceptual clarity. These findings establish that carefully balancing reconstruction fidelity and latent regularization is crucial for learning interpretable and manipulable sketch representations.
The authors evaluate the Sketch-RNN model on various datasets using different settings for the KL loss weight, observing trade-offs between reconstruction and KL loss terms. Results show that models with higher KL loss weights produce more coherent reconstructions and smoother latent space interpolations, while models with lower KL loss weights tend to generate incoherent outputs and less meaningful interpolations. The model's ability to perform sketch drawing analogies and multi-sketch interpolations demonstrates the organization of the latent space in terms of conceptual features. Models with higher KL loss weights produce more coherent reconstructions and smoother latent space interpolations compared to models with lower KL loss weights. The model can perform sketch drawing analogies by manipulating latent vectors, allowing for the addition or removal of conceptual features such as bodies or animal parts. The reconstruction quality and coherence of generated sketches are more strongly influenced by the KL loss weight than the reconstruction loss alone, with lower KL loss weights leading to incoherent outputs.
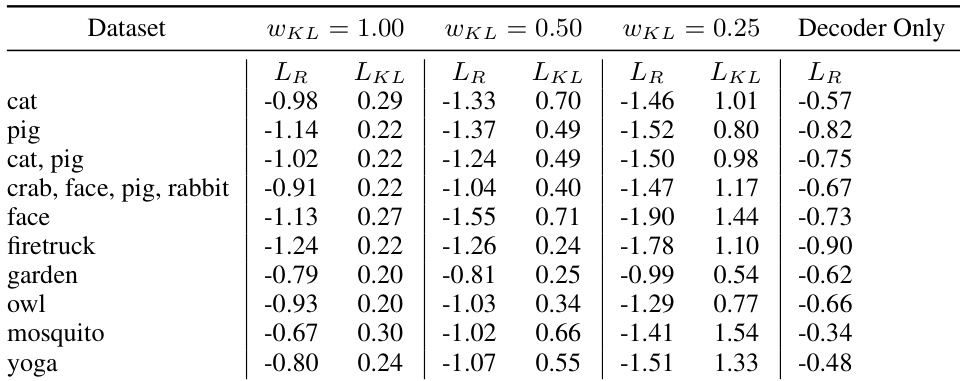
The authors evaluated the Sketch-RNN model across multiple datasets by systematically varying the KL loss weight to validate its influence on latent space organization and generative coherence. The experiments demonstrate that higher KL weights produce structurally sound reconstructions and smooth latent interpolations, whereas lower weights result in fragmented and less meaningful outputs. Qualitatively, the model successfully executes sketch analogies and multi-sketch interpolations by manipulating latent vectors to add or remove conceptual features. These findings establish that the KL loss weight is the dominant factor in shaping a meaningful latent space, enabling the model to effectively capture and recombine high-level visual concepts.