Command Palette
Search for a command to run...
Tutorial sur la réponse aux questions concernant des images avec l'apprentissage profond
Tutorial sur la réponse aux questions concernant des images avec l'apprentissage profond
Mateusz Malinowski Mario Fritz
Tutoriel Keras : Un guide pour débutants en apprentissage profond
Résumé
Aux côtés du développement de méthodes plus précises en vision par ordinateur et en compréhension du langage naturel, des architectures holistiques capables de répondre à des questions sur le contenu d’images du monde réel ont émergé. Dans ce tutoriel, nous proposons une approche neuronale pour répondre à des questions sur des images. Nous fondons notre tutoriel sur deux jeux de données : principalement DAQUAR, et dans une moindre mesure VQA. Avec de légères modifications, les modèles que nous présentons ici peuvent atteindre des performances compétitives sur les deux jeux de données ; en fait, ils figurent parmi les meilleures méthodes utilisant une combinaison de LSTM avec une représentation CNN globale de l’image en pleine résolution. Nous espérons qu’après la lecture de ce tutoriel, le lecteur sera en mesure d’utiliser des frameworks d’apprentissage profond, tels que Keras et Kraino, introduit dans ce tutoriel, afin de construire diverses architectures qui permettront d’améliorer davantage les performances sur cette tâche difficile.
One-sentence Summary
Malinowski and Fritz present a tutorial on constructing neural visual question answering architectures that combine LSTMs with global full-frame CNN representations, demonstrating competitive performance on the DAQUAR and VQA datasets while providing implementation guidance using Keras and the Kraino framework to enable further performance improvements.
Key Contributions
- This tutorial introduces a neural architecture for visual question answering that integrates long short-term memory networks with a global, full-frame convolutional neural network representation.
- The work provides Kraino, a Keras-based framework designed to streamline the implementation and training of deep learning architectures for visual question answering.
- Evaluated on the DAQUAR and VQA datasets, the proposed models achieve competitive performance and rank among the leading methods utilizing global image representations.
Introduction
Visual question answering bridges computer vision and natural language understanding by enabling machines to interpret real-world images and respond to natural language queries, a capability essential for advancing multimodal AI and intuitive applications. Prior approaches, however, frequently rely on global image representations that discard fine-grained details, struggle with semantic and spatial ambiguities, and depend on rigid accuracy metrics that fail to capture nuanced answer correctness. The authors address these gaps by presenting a streamlined neural architecture that combines long short-term memory networks with full-frame convolutional neural network features, demonstrating competitive performance on benchmark datasets while offering a practical guide for implementing and extending these models using modern deep learning frameworks.
Dataset
-
Dataset Composition and Sources: The authors utilize two visual question answering datasets: DAQUAR (Malinowski and Fritz, 2014), which provides scene-based question-answer-image triplets, and VQA (Antol et al., 2015), a large-scale open-ended dataset. Both supply paired textual queries, answers, and corresponding image identifiers.
-
Subset Details and Filtering Rules: DAQUAR is divided into training and testing splits, with answers occasionally containing multiple comma-separated terms. The VQA training subset is filtered using a single frequent answer mode and restricted to the top 1000 most common question-answer pairs, while model evaluation relies on the publicly available validation set because test labels are hidden.
-
Data Processing and Training Usage: Raw text is converted into numerical formats by building separate word-to-index dictionaries from the training corpus. Questions are padded to a fixed sequence length of 30 tokens, and answers are truncated to their first word before being padded to a single time step. The pipeline operates on token indices rather than sparse one-hot vectors to avoid inefficient matrix multiplications, while special tokens handle sequence alignment and out-of-vocabulary words.
-
Visual Feature Extraction and Metadata Alignment: Image data is processed by extracting features from pre-trained convolutional networks. The authors pull the 4096-dimensional second-to-last layer from VGG Net for DAQUAR and use the
pool5-7x7_s1layer from a designated CNN for VQA. Textual and visual modalities are aligned through shared image filenames, and a fixed embedding dimension of 1000 is applied to the final feature representations.
Method
The authors leverage a modular framework for building question answering models that process both textual and visual inputs, structured around a sequence-to-sequence paradigm with distinct encoding and fusion components. The overall approach begins with text-only models that learn to answer questions without visual input, serving as a baseline that captures dataset biases and common-sense knowledge. The framework then extends to joint language and vision models that integrate visual features extracted from images. The core design relies on a modular architecture where language and vision streams are processed separately and then combined through configurable fusion operations.
The text processing pipeline starts with encoding the input question into a sequence of word representations. The first module considered is the Bag-of-Words (BOW) model, which represents the question as a sparse one-hot vector for each word, which is then embedded into a dense vector space using a learnable embedding matrix We. The embedded word vectors are summed to produce a single fixed-length representation of the entire question. This aggregated representation is passed through a fully connected layer followed by a softmax activation to produce a probability distribution over possible answer words. The model is trained to minimize the cross-entropy loss, which measures the difference between the predicted and true answer distributions. The training process involves gradient-based optimization using the Adam algorithm, which adapts the learning rate for each parameter based on the first and second moments of the gradients.
To capture the sequential nature of language, the authors introduce a Recurrent Neural Network (RNN) module, specifically an LSTM, which processes the input question word by word. As shown in the figure below, each word embedding xt is fed into an LSTM cell, which maintains a hidden state ht that accumulates information from the sequence up to the current time step. The final hidden state ht of the sequence is used as the representation of the entire question. This representation is then passed through a dense layer and softmax for classification. The RNN architecture explicitly models the order of words, which is crucial for understanding questions where word position affects meaning.
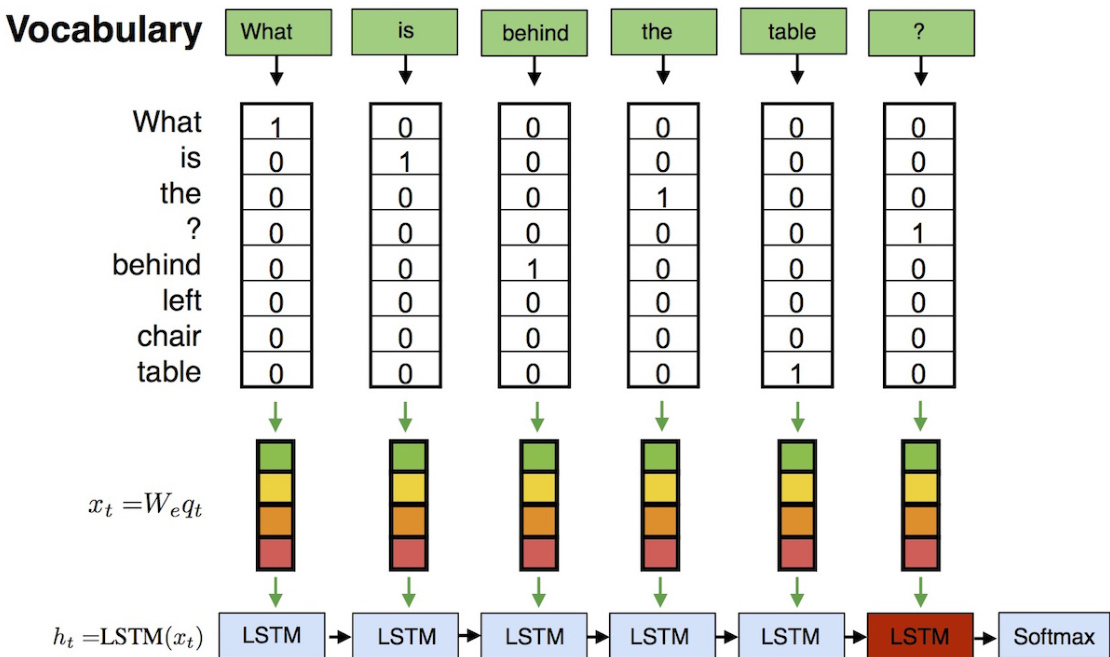
The integration of visual information is handled by a separate pathway. A Convolutional Neural Network (CNN) is used to extract a fixed-dimensional feature vector from the input image, which serves as the visual representation. This visual feature vector is processed through a dense layer to match the dimensionality of the language representation. The language and visual representations are then combined using a multimodal fusion operation. The framework supports multiple fusion strategies, including concatenation, element-wise multiplication, and summation. As illustrated in the figure below, the fused representation is passed through a dropout layer and a final classification layer to predict the answer. The model is trained end-to-end using the same cross-entropy loss and Adam optimization, with the gradients flowing through both the language and vision pathways.
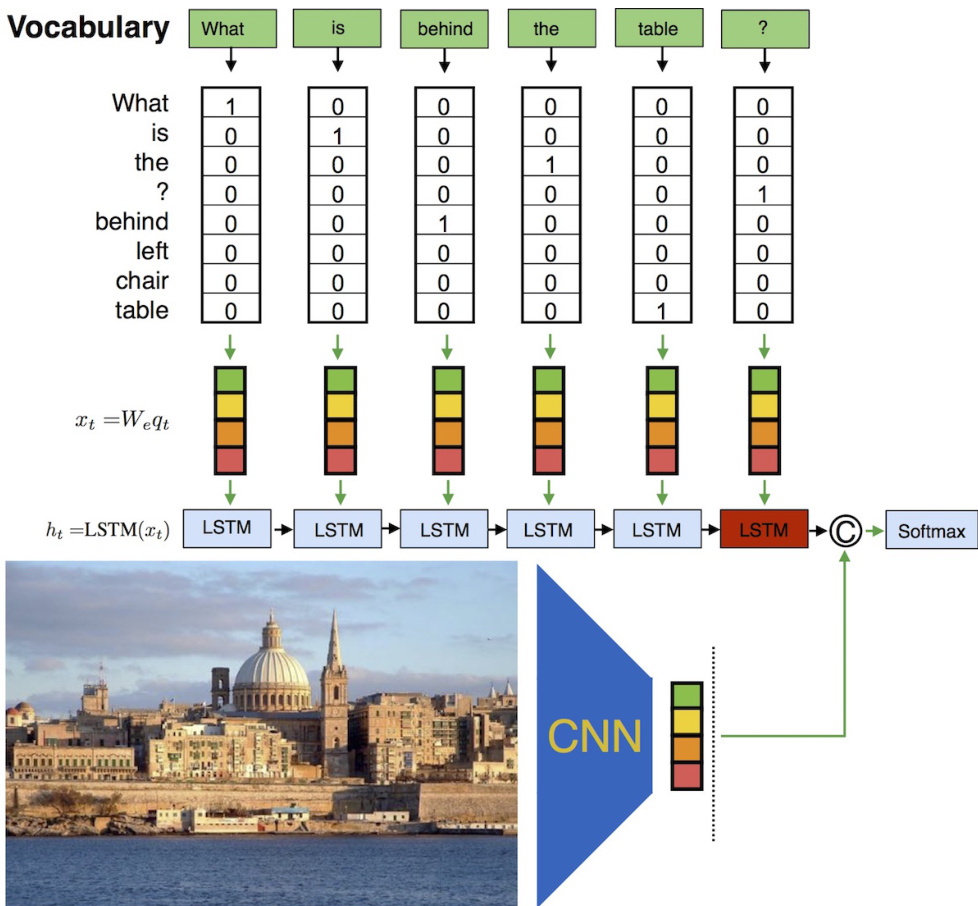
Experiment
The evaluation framework utilizes the WUPS metric to assess predictions against ground truth, effectively handling word-level ambiguities and set-based comparisons. Initial experiments validate text-only blind models, while subsequent tests introduce CNN-extracted visual features paired with both bag-of-words and recurrent neural network architectures. These multimodal experiments demonstrate that integrating visual data significantly enhances performance, with sequence-aware RNNs proving particularly effective for processing combined text and image inputs. Overall, the study highlights the critical role of modality fusion strategies and training configurations in achieving robust visual understanding.