Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Réseaux de neurones convolutifs
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
This study introduces a dropout training framework for convolutional neural networks that replaces standard max-pooling with probabilistic weighted pooling to perform test-time model averaging via multinomial activation sampling, achieving state-of-the-art performance on MNIST and highly competitive results on CIFAR-10 and CIFAR-100 without data augmentation.
Key Contributions
- Applying dropout to max-pooling layers is mathematically equivalent to randomly selecting activations according to a multinomial distribution during training. This equivalence clarifies the stochastic mechanism underlying standard max-pooling dropout operations.
- Probabilistic weighted pooling is proposed as a direct replacement for deterministic max-pooling to perform model averaging at test time. Empirical evaluations demonstrate the superior performance of this probabilistic approach compared to conventional pooling methods.
- Simultaneously designing dropout for max-pooling and fully-connected layers achieves state-of-the-art accuracy on MNIST and highly competitive results on CIFAR-10 and CIFAR-100 without data augmentation. Furthermore, convolutional dropout is shown to meaningfully improve generalization despite the inherent regularization provided by convolutional architectures.
Introduction
Deep convolutional neural networks have revolutionized visual recognition but remain highly susceptible to overfitting when trained on limited data. While dropout has become a standard regularization technique for fully connected layers, prior research largely overlooked its application to convolutional and pooling layers under the assumption that architectural weight sharing already mitigated overfitting. The authors leverage dropout in both max-pooling and convolutional layers to systematically improve model generalization. They demonstrate that max-pooling dropout functions as multinomial activation sampling and introduce probabilistic weighted pooling at test time to efficiently approximate the average of exponentially many sub-models. This approach yields state-of-the-art performance on MNIST and highly competitive results on CIFAR benchmarks without relying on data augmentation, outperforming established stochastic pooling methods.
Dataset

- Dataset Composition and Sources: The authors utilize the CIFAR-10 dataset, which contains ten classes of natural images originally sourced from the web-based Tiny Images collection.
- Subset Details: The dataset comprises 50,000 training samples and 10,000 testing samples, with every image formatted as a 32x32 RGB frame.
- Data Processing: Pixel values are normalized to the [0, 1] range, and the authors subtract the channel-wise mean calculated across the entire dataset from each image.
- Model Usage and Training: The data follows the standard 50,000 training and 10,000 testing split. The authors train a deeper convolutional network for 1000 epochs to handle high intra-class variability, applying dropout to convolutional, max-pooling, and fully connected layers with retaining probabilities of 0.3, 0.5, and 0.7. They evaluate models using probabilistic weighted pooling and explicitly note that the reported results exclude any training data augmentation.
Method
The authors leverage max-pooling dropout as a stochastic mechanism to introduce variability during training in convolutional neural networks, particularly within pooling layers. The framework begins with standard forward propagation through convolutional and pooling layers, where activations are processed using a pooling function such as max-pooling. In the presence of max-pooling dropout, a binary mask is applied element-wise to the activations in each pooling region. This mask, drawn from a Bernoulli distribution with retention probability p, randomly zeros out activations with probability q=1−p. The modified activations are then passed to the pooling operation. 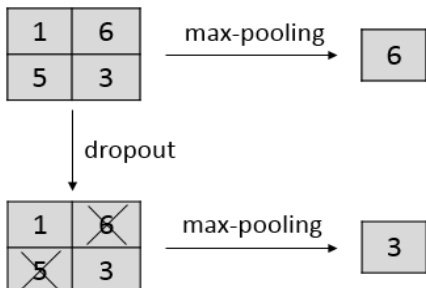
As shown in the figure below, without dropout, max-pooling selects the maximum activation within a pooling region. With dropout, the selection becomes stochastic: for instance, if the activations are 1, 6, 5, and 3, and the mask zeros out the 6 and 5, then the maximum of the remaining values (1 and 3) is 3, which becomes the output. This stochasticity arises because the selection of the pooled activation corresponds to sampling from a multinomial distribution, where the probability of selecting activation ai(l) is pi=pqn−i, with n being the number of units in the pooling region. A special case occurs when all units are dropped out, resulting in a zero output with probability qn. This formulation reveals that max-pooling dropout effectively trains a mixture of models, each corresponding to a different selection of active units in the pooling region.
To approximate model averaging at test time, the authors propose probabilistic weighted pooling. Instead of using a simple scaling of the maximum activation, the pooled output is computed as a weighted sum of all activations within the region, where each activation is weighted by its probability of being selected during training. This ensures that the test-time output matches the expected output under the multinomial distribution used at training. This approach efficiently averages over the exponentially many possible models generated by dropout without explicitly instantiating them.
The authors also introduce convolutional dropout, which applies dropout directly to feature maps before convolutional layers. Here, a binary mask is applied to each feature map independently, and the modified activations are convolved with learned filters. The number of possible distinct convolved outputs is exponential in the number of parameters, leading to a large ensemble of models. At test time, the network is evaluated using all units with filter weights scaled by the retention probability, providing an estimate of averaging over these models. Empirical results show that while convolutional dropout improves generalization, it is less effective than max-pooling or fully-connected dropout due to the inherent regularization provided by the shared-filter and local-connectivity structure of convolutional layers.
Experiment
The experiments evaluate various pooling strategies and dropout placements across standard CNN architectures trained on MNIST, CIFAR-10, and CIFAR-100 datasets. Results demonstrate that probabilistic weighted pooling serves as a more accurate and effective test-time approximation for averaging dropout models than traditional alternatives, consistently improving generalization. Furthermore, investigating dropout across different network layers reveals that while all placements mitigate overfitting, combining max-pooling dropout with fully-connected dropout yields the most robust regularization and superior performance. Ultimately, the study confirms that probabilistic weighted pooling and strategic dropout integration significantly enhance model accuracy without relying on data augmentation.
The authors evaluate different dropout techniques on CNN models, focusing on max-pooling dropout and its impact on model performance. Results show that combining max-pooling dropout with fully-connected dropout achieves the lowest error rate, indicating improved generalization compared to other dropout configurations. Probabilistic weighted pooling is highlighted as a superior method for test-time inference compared to max-pooling and scaled max-pooling. Combining max-pooling dropout with fully-connected dropout yields the best performance on the tested dataset. Probabilistic weighted pooling outperforms max-pooling and scaled max-pooling at test time. Using dropout in multiple layers can improve performance, but improper combinations may degrade results.
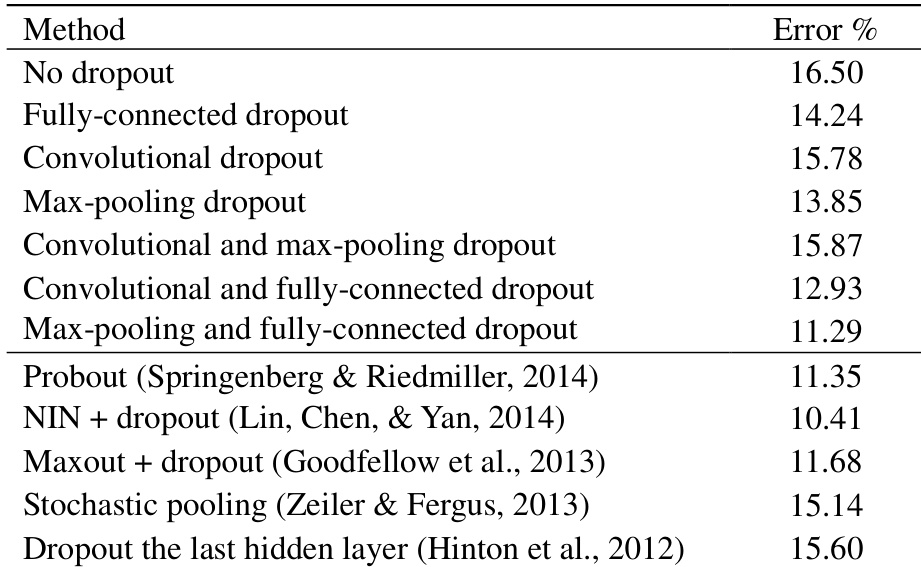
{"summary": "The authors compare different pooling methods at test time after training with max-pooling dropout, focusing on their effectiveness in reducing error rates across varying retention probabilities. Results show that probabilistic weighted pooling consistently outperforms both max-pooling and scaled max-pooling, especially at lower retention probabilities, indicating better generalization and a more accurate approximation of model averaging.", "highlights": ["Probabilistic weighted pooling achieves lower error rates than max-pooling and scaled max-pooling across all retention probabilities.", "The performance gap between probabilistic weighted pooling and other methods is most pronounced at lower retention probabilities.", "As retention probability increases, the error rates across all pooling methods converge, with probabilistic weighted pooling maintaining a consistent advantage."]
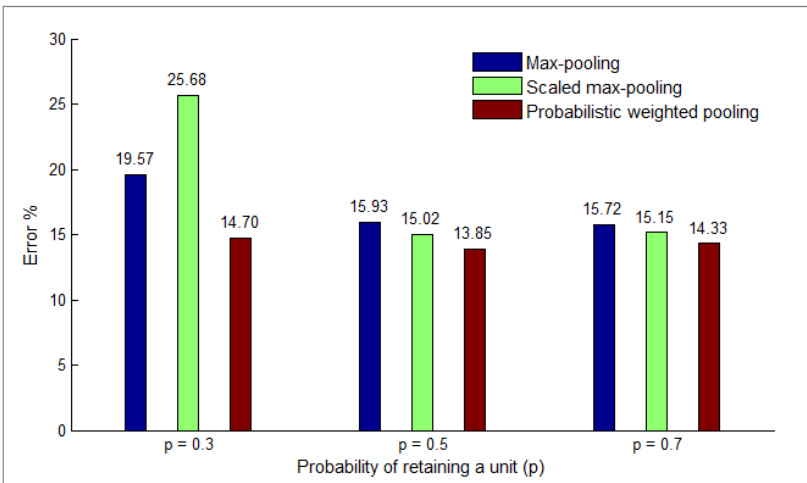
The authors evaluate different dropout methods on MNIST, comparing their effectiveness in reducing test errors. Results show that combining max-pooling dropout with fully-connected dropout achieves the lowest error rate, outperforming other configurations and previous state-of-the-art methods. Probabilistic weighted pooling is found to be superior to max-pooling and scaled max-pooling in approximating model averaging at test time. Combining max-pooling dropout with fully-connected dropout achieves the lowest test error on MNIST. Probabilistic weighted pooling outperforms max-pooling and scaled max-pooling in test performance. Using dropout in different layers improves generalization, but improper combinations can degrade performance.
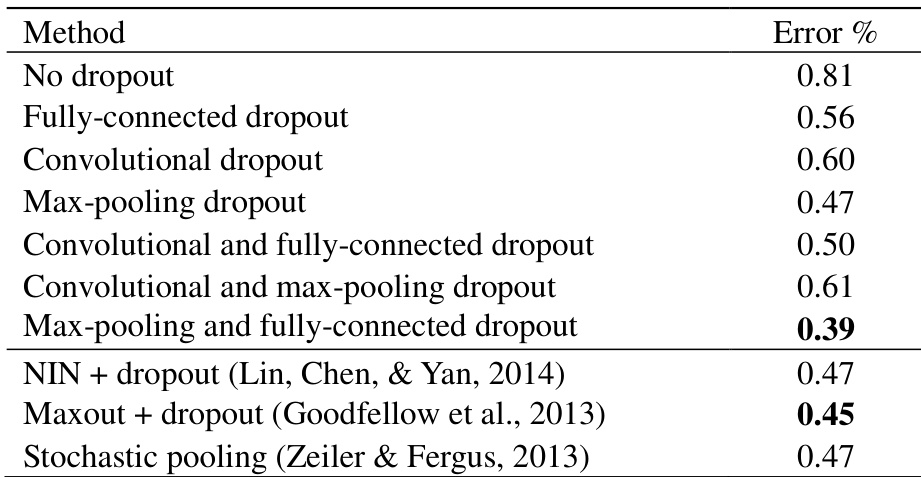
The authors evaluate different dropout strategies and pooling methods on MNIST, comparing their impact on model performance. Results show that combining max-pooling dropout with fully-connected dropout achieves the lowest error rate, outperforming individual dropout methods and baseline approaches. Probabilistic weighted pooling consistently improves performance over max-pooling and scaled max-pooling across all configurations. Combining max-pooling and fully-connected dropout achieves the best test performance on MNIST. Probabilistic weighted pooling consistently outperforms max-pooling and scaled max-pooling in all tested configurations. Using dropout in multiple layers simultaneously can improve performance, but improper combinations may degrade results.
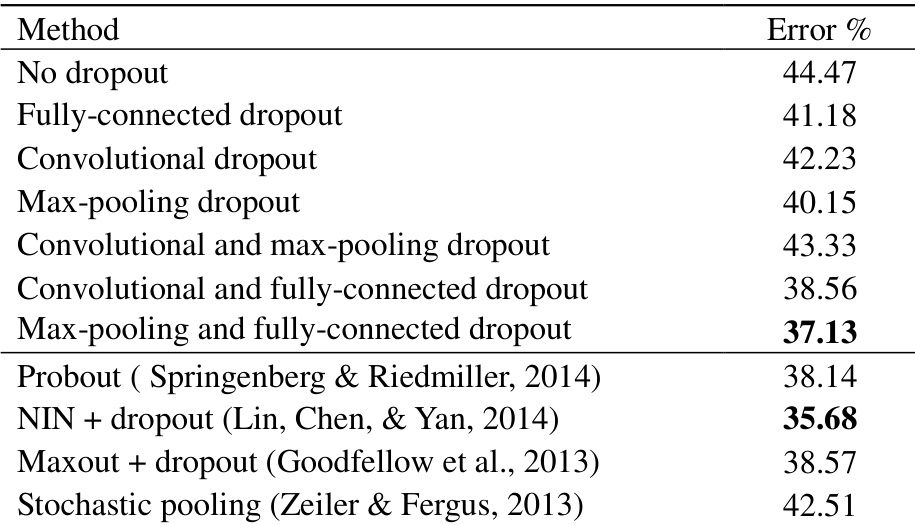
The experiments evaluate CNN models on benchmark datasets to assess how various dropout configurations during training and pooling strategies during inference affect generalization and test error. The training evaluations validate that combining max-pooling dropout with fully-connected dropout yields the most robust performance, while the inference evaluations confirm that probabilistic weighted pooling consistently surpasses standard and scaled max-pooling by better approximating model averaging. Ultimately, the qualitative findings demonstrate that strategically coordinated multi-layer dropout enhances generalization, whereas mismatched combinations can degrade overall model accuracy.