Command Palette
Search for a command to run...
Le titre est vide. Veuillez fournir le titre à traduire.
Le titre est vide. Veuillez fournir le titre à traduire.
Déploiement en un clic de FractalGen : génération d'images haute résolution pixel par pixel
Résumé
Please provide the title and abstract you would like me to translate into French.
One-sentence Summary
This paper proposes an integer-valued estimation of information quantity in a digital image pixel based on a binary hierarchy of pixel clusters, develops methods for constructing these hierarchies and generating hierarchical sequences of image approximations that minimally differ from the original image by a standard deviation, and experimentally compares the resulting estimates with those obtained using classical formulas.
Key Contributions
- Defines an integer-valued information quantity for individual image pixels by constructing a binary hierarchy of pixel clusters, thereby addressing the non-integer output limitations of classical Shannon and Hartley estimations. This quantized metric aligns with steganographic embedding capacity requirements and optimal image segmentation frameworks.
- Develops methods for constructing cluster hierarchies and generating hierarchical sequences of image approximations that minimally differ from the original image by a standard deviation. The framework reduces structural analysis to segment reduction operations within quasioptimal approximations.
- Compares the proposed integer estimation against classical continuous formulas through experimental evaluations, confirming its plausibility for steganographic applications and structural image analysis. The results validate the metric as a consistent alternative for quantizing information units in digital images.
Introduction
Digital image processing relies on accurate information quantification, particularly for steganography and image segmentation where pixels serve as discrete storage units. Traditional Hartley and Shannon formulas yield real-valued outputs that conflict with the discrete nature of bits and hinder practical embedding capacity assessments. The authors address this limitation by introducing an integer-valued estimation framework built on a binary hierarchy of pixel clusters. They develop algorithms to construct these hierarchies and generate optimal image approximations, validating their discrete metric against classical methods and establishing a practical foundation for steganographic data storage and efficient image partitioning.
Method
The authors leverage a hierarchical approach to model image information quantity through a binary decomposition of pixel clusters, forming the foundation of their method. This framework begins by treating uniform clusters—sets of pixels with identical intensities—as indivisible units. A binary hierarchy is constructed by recursively partitioning non-uniform clusters into two sub-clusters based on differences in average intensity, enabling a structured representation of information content. The integer information quantity of a pixel is defined as the number of non-uniform clusters that contain it, effectively capturing the depth of its inclusion in the hierarchical decomposition. This definition aligns with classical information-theoretic estimations: when the hierarchy consists of uniform clusters with equal numbers of pixels at each level, it corresponds to Shannon’s estimation, while equal partitioning of cluster counts yields Hartley’s estimation.
The method proceeds to define a compact, isomorphic invariant representation Hu of the original image u. This representation encodes the hierarchical structure of pixel clusters through a pseudo-ternary number system, where non-negative integers are expressed using coefficients 0, 1, and 2. In this system, the extracted bits of information are encoded as 0 and 2, while the neutral value 1 signifies the absence of information extraction from a pixel within an indivisible uniform cluster. The construction of Hu unfolds iteratively: starting with all pixels assigned to a single cluster and Hu initialized to zero, each non-uniform cluster is split into two sub-clusters at each iteration. The pixel values in Hu are then updated according to a specific rule: the representation is doubled for all pixels, and if the pixel belongs to a uniform cluster, its value is incremented by 1; if it belongs to a sub-cluster with higher average intensity, the value is increased by 2. This process continues until the image is fully decomposed into uniform clusters. The resulting Hu thus encodes the entire hierarchy of cluster splits, allowing for the direct computation of the integer information quantity by analyzing the sequence of pixel values through iterative arithmetic transformations.
The invariant representation Hu is termed "invariant" because it remains unchanged under linear transformations of pixel intensities when the splitting algorithm is invariant to such transformations, such as Otsu thresholding. It commutes with image negation and scaling via pixel duplication, preserving the information content regardless of these operations. The transformation H from image u to Hu is isotone, meaning it preserves the order of intensity levels within clusters by mapping average intensities to integer pixel values in Hu without altering their relative ordering. This property ensures that Hu is isomorphic to a piece-wise constant approximation of the original image, where pixel values are replaced by the average intensities within their respective clusters.
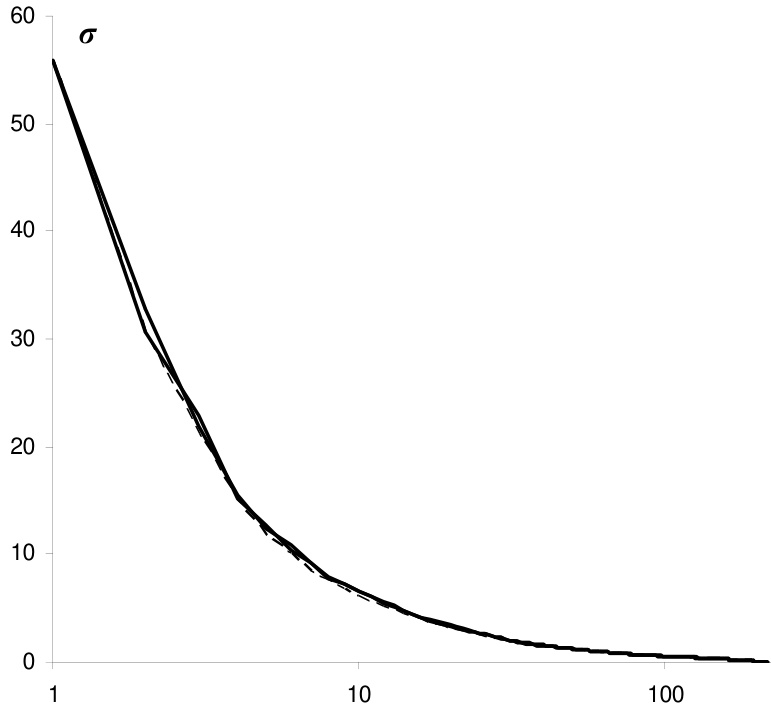
To obtain quasioptimal image approximations, the method focuses on constructing a hierarchical sequence of approximations with increasing numbers of clusters. The approach avoids the complexity of analyzing cluster repetitions by decoupling the process into two stages. First, a compact invariant representation Hu is computed, which inherently defines a sequence of partitions into 1,2,4,8,… clusters. Second, this representation is expanded into a sequence of approximations with successively increasing cluster counts, where each step maximizes the reduction of the total squared error E=Nσ2. The resulting approximations maintain convexity in the sequence of total squared errors Ei, satisfying the inequality:
Ei≤2Ei−1+Ei+1,i=2,3,…,g−1.This convexity ensures that the quasioptimal approximations preserve the desirable properties of optimal approximations while enabling conversion into isomorphic invariant representations. The method thus provides a structured, hierarchical framework for image approximation and information quantification that is both computationally tractable and theoretically grounded in information-theoretic principles.
Experiment
The experiments evaluate image approximation techniques using the standard Lena dataset, comparing optimal methods with computationally simpler quasioptimal approaches based on iterative thresholding and cluster merging. Visual and statistical assessments demonstrate that the quasioptimal approximations achieve comparable reconstruction quality while offering enhanced robustness for pattern recognition through invariant representation. The study further validates a novel integer-based information quantity estimation against classical Shannon and Hartley measures across different clustering strategies. Results confirm that this integer estimation consistently aligns with established information theory metrics, establishing it as a reliable and efficient alternative for image analysis.