Command Palette
Search for a command to run...
HuMo-1.7B : Un Cadre Pour La Génération De Vidéos Multimodales
Date
URL du document
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel

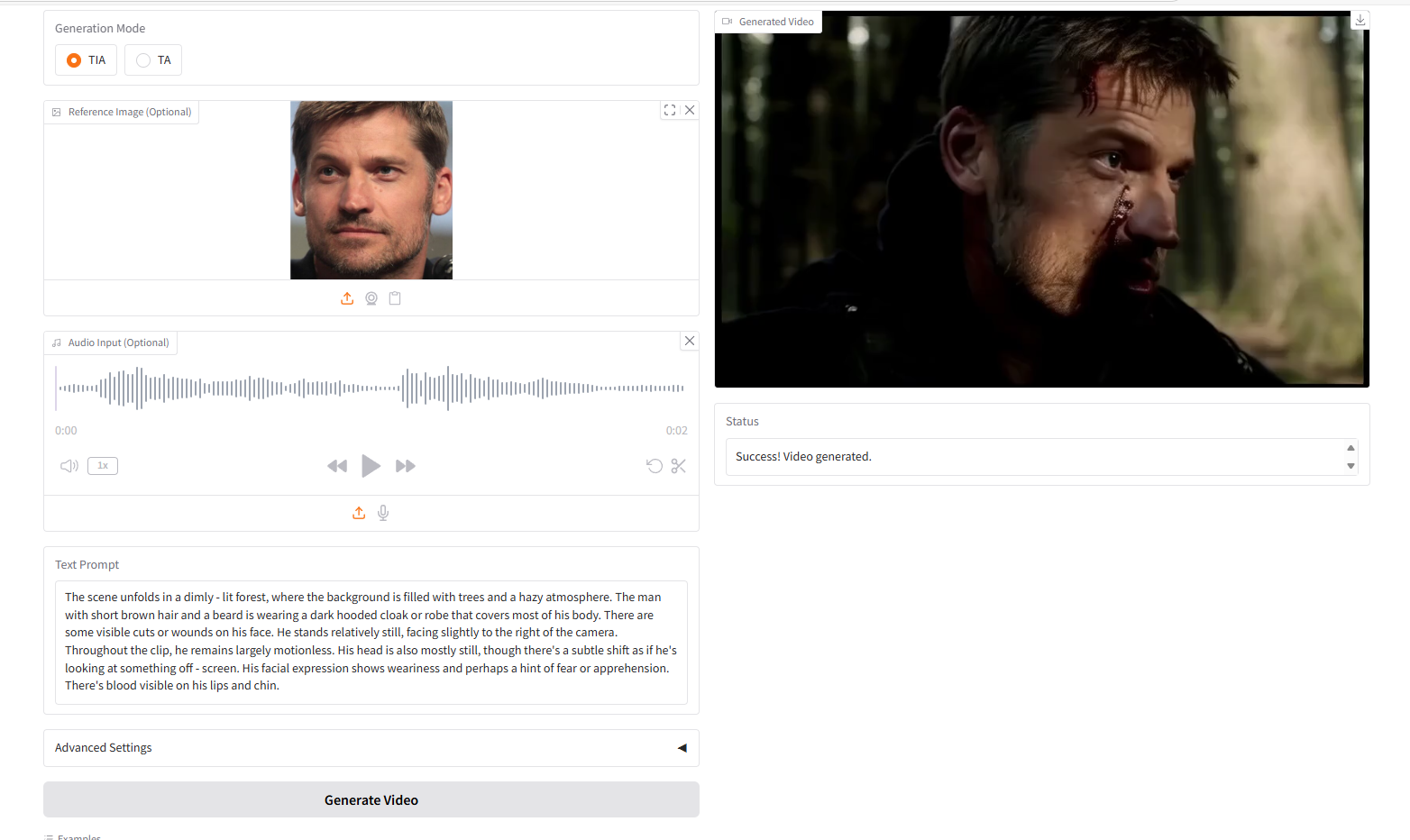
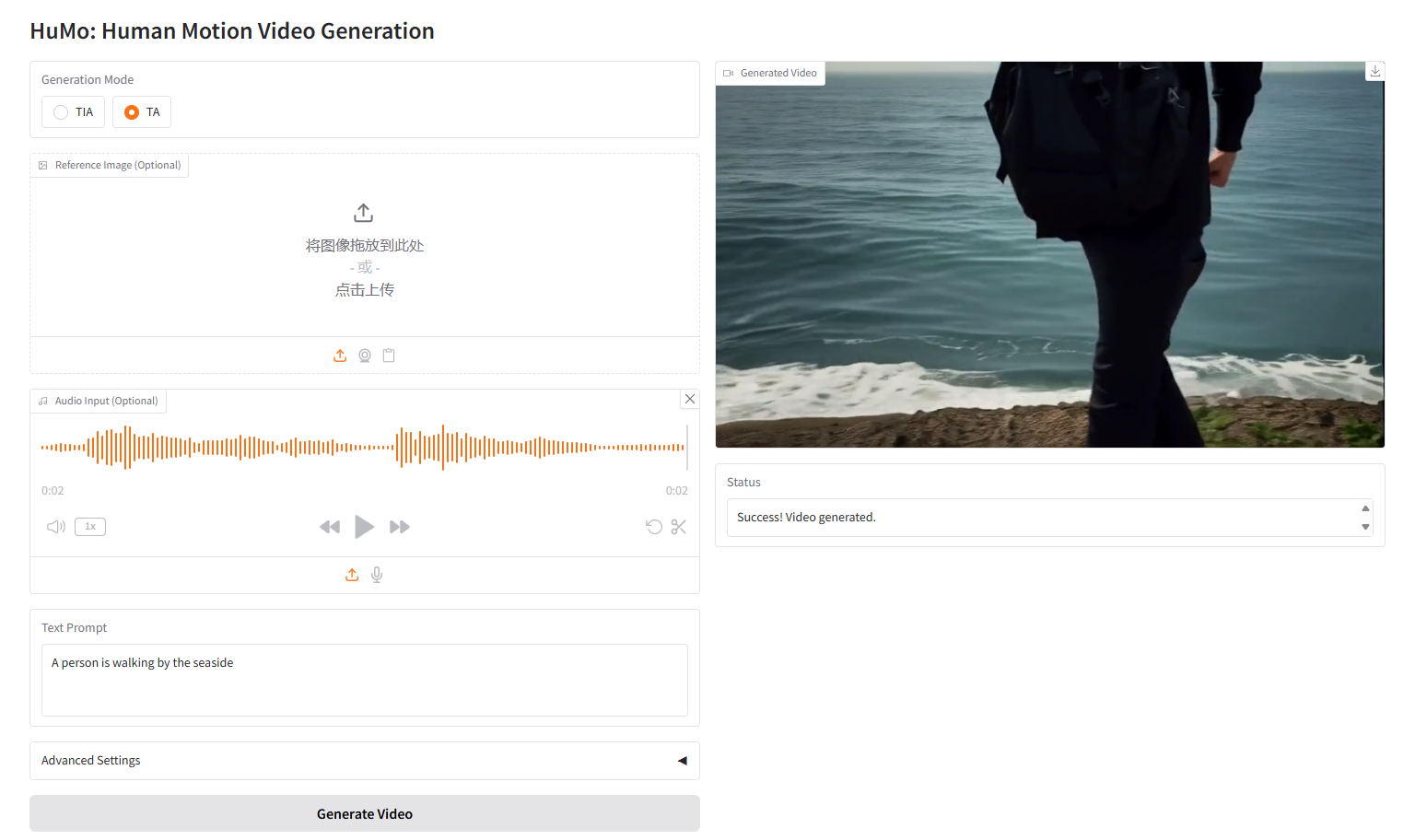
HuMo, développé en septembre 2025 par l'Université Tsinghua et le laboratoire de création intelligente de ByteDance, est un framework de génération vidéo multimodal axé sur l'humain. Il permet de générer des vidéos de haute qualité, détaillées et contrôlables, à partir de multiples entrées modales telles que du texte, des images et de l'audio. HuMo offre des fonctionnalités avancées de suivi des indices textuels, de préservation du sujet et de synchronisation des mouvements par l'audio. Il prend en charge la génération vidéo à partir de texte et d'image (VideoGen à partir de texte et d'image), de texte et d'audio (VideoGen à partir de texte et d'audio) et de texte, d'image et d'audio (VideoGen à partir de texte, d'image et d'audio), offrant ainsi aux utilisateurs une personnalisation et un contrôle accrus. Des articles de recherche associés sont disponibles. HuMo : Génération vidéo centrée sur l'humain via un conditionnement multimodal collaboratif .
Le projet HuMo propose le déploiement de modèles selon deux spécifications : 1.7B et 17B. Ce tutoriel utilise le modèle 1.7B et une seule carte RTX 5090 comme ressource.
2. Exemples de projets
VideoGen à partir de Texte-Image-Audio, TIA
VideoGen de Text-Audio,TA
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
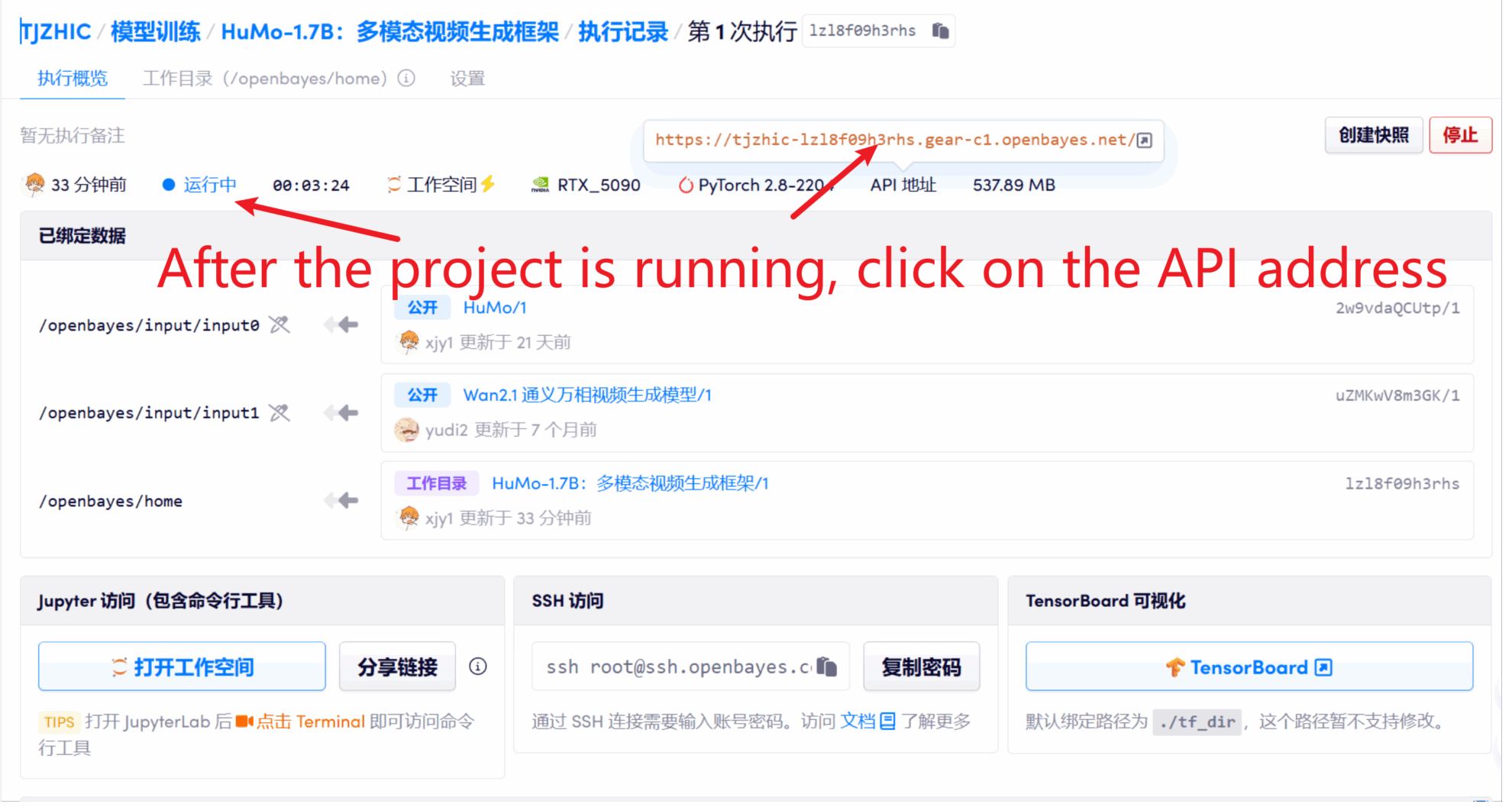
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page. Remarque : lorsque les étapes d’échantillonnage sont définies sur 10, la génération des résultats prend environ 3 à 5 minutes.
VideoGen à partir de Texte-Image-Audio (TIA)
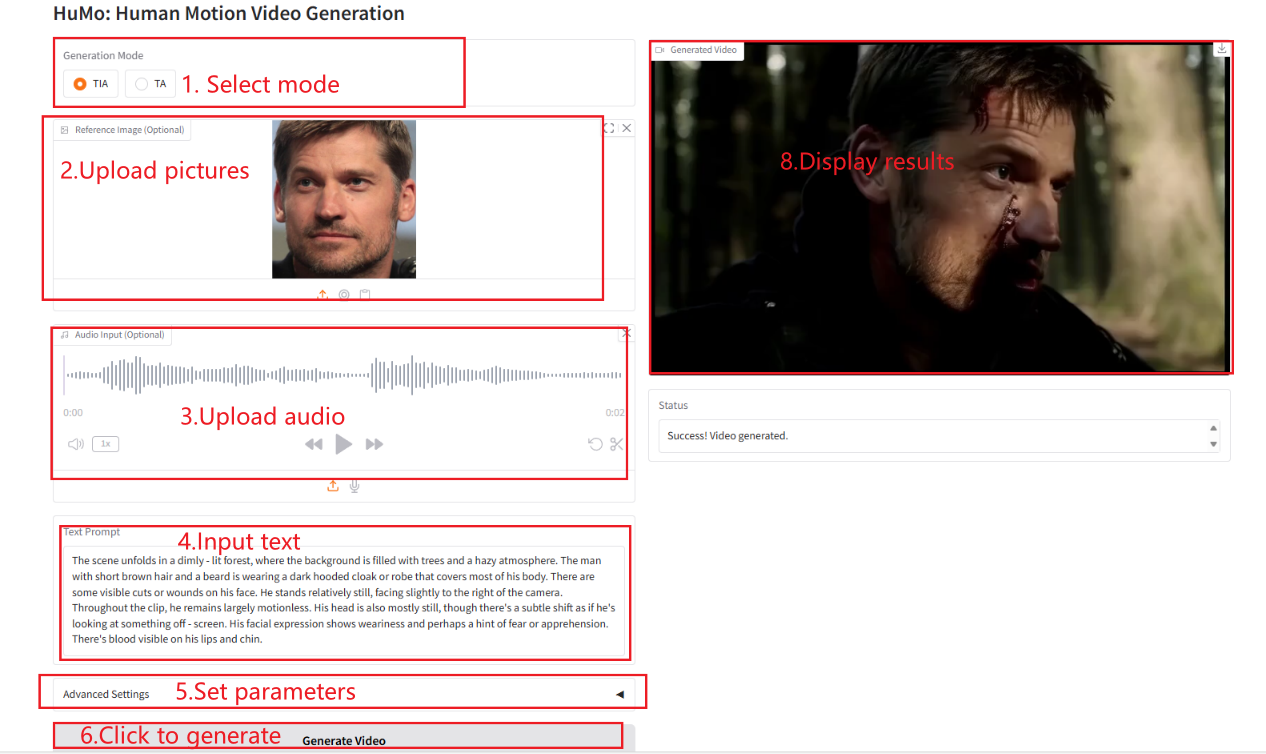
VideoGen à partir de texte-audio (TA)
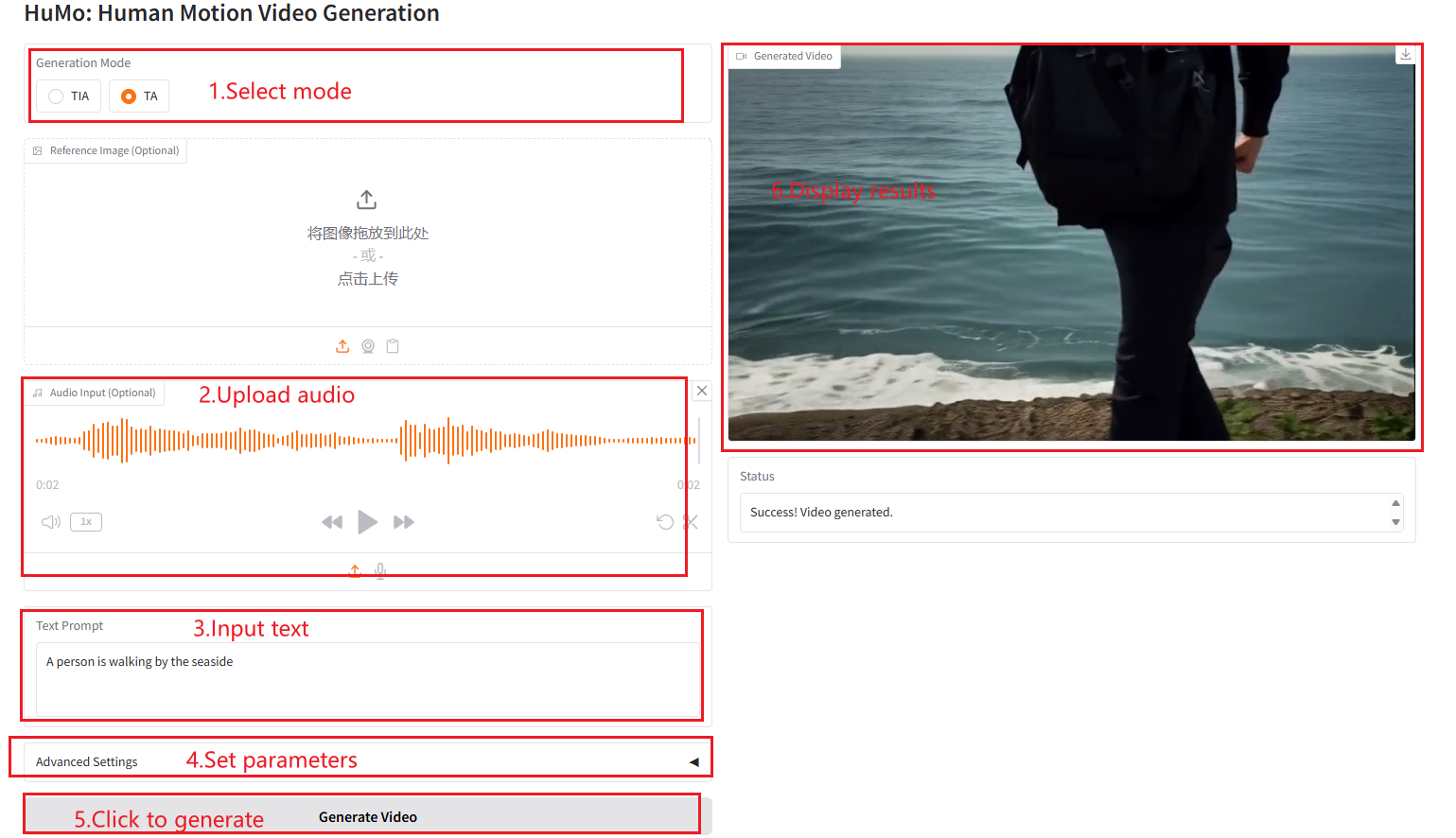
Description des paramètres
- Hauteur : définissez la hauteur de la vidéo.
- Largeur : définissez la largeur de la vidéo.
- Images : définissez le nombre d’images vidéo.
- Échelle de guidage du texte : mise à l'échelle du guidage du texte, utilisée pour contrôler l'impact des invites de texte sur la génération de vidéo.
- Échelle de guidage d'image : mise à l'échelle du guidage d'image, utilisée pour contrôler l'influence des repères d'image sur la génération vidéo.
- Échelle de guidage audio : mise à l'échelle du guidage audio, utilisée pour contrôler l'influence des signaux audio sur la génération vidéo.
- Étapes d'échantillonnage : le nombre d'étapes d'échantillonnage utilisées pour contrôler la qualité et les détails de la vidéo générée.
4. Discussion
Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@misc{chen2025humo,
title={HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning},
author={Liyang Chen and Tianxiang Ma and Jiawei Liu and Bingchuan Li and Zhuowei Chen and Lijie Liu and Xu He and Gen Li and Qian He and Zhiyong Wu},
year={2025},
eprint={2509.08519},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.08519},
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.