Command Palette
Search for a command to run...
Démonstration Du Modèle De Génération Vidéo Pusa-VidGen
Date
URL du document
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel

Pusa V1, proposé par l'équipe de Yaofang-Liu le 25 juillet 2025, est un modèle de génération vidéo multimodal haute performance. Basé sur la technologie d'adaptation temporelle vectorisée (VTA), il résout les problèmes fondamentaux des modèles de génération vidéo traditionnels : coût d'entraînement élevé, faible efficacité d'inférence et faible cohérence temporelle. Contrairement aux méthodes classiques qui nécessitent d'importants volumes de données et une grande puissance de calcul, Pusa V1 réalise des optimisations majeures grâce à une stratégie de réglage fin légère, basée sur Wan2.1-T2V-14B : son coût d'entraînement est de seulement 500 $ (200 fois inférieur à celui des modèles similaires), l'ensemble de données requis est de seulement 4 000 échantillons (2 500 fois inférieur à celui des modèles similaires) et l'entraînement peut être effectué sur huit GPU de 80 Go, abaissant ainsi considérablement le seuil d'application de la technologie de génération vidéo. Ce logiciel possède simultanément de puissantes capacités multitâches, prenant en charge non seulement la vidéo pilotée par texte (T2V) et la vidéo guidée par image (I2V), mais aussi des tâches de génération automatique telles que la complétion vidéo, la génération de la première et de la dernière image, et les transitions entre scènes, sans nécessiter d'entraînement supplémentaire pour des scènes spécifiques. Plus important encore, ses performances de génération sont particulièrement remarquables. Grâce à une stratégie d'inférence à pas courts (surpassant le modèle de base en seulement 10 étapes), il a atteint un score total de 87,32% sur la plateforme VBench-I2V, démontrant d'excellentes performances en matière de reproduction des détails dynamiques (tels que les mouvements des membres et les variations d'éclairage) et de cohérence temporelle. De plus, le mécanisme d'adaptation non destructive implémenté via la technologie VTA intègre des capacités de dynamique temporelle au modèle de base tout en préservant la qualité de génération d'image du modèle original, obtenant ainsi un effet « 1+1>2 ». Au niveau du déploiement, sa faible latence d'inférence répond à divers besoins, de la prévisualisation rapide à la sortie haute définition, le rendant idéal pour la conception créative, la production de vidéos courtes et d'autres scénarios. Les résultats de l'article connexe sont... PUSA V1.0 : Surpassement de Wan-I2V avec un coût d’entraînement de $500 grâce à une adaptation vectorisée du pas de temps .
Ce tutoriel utilise des ressources RTX A6000 à double carte.
2. Exemples de projets
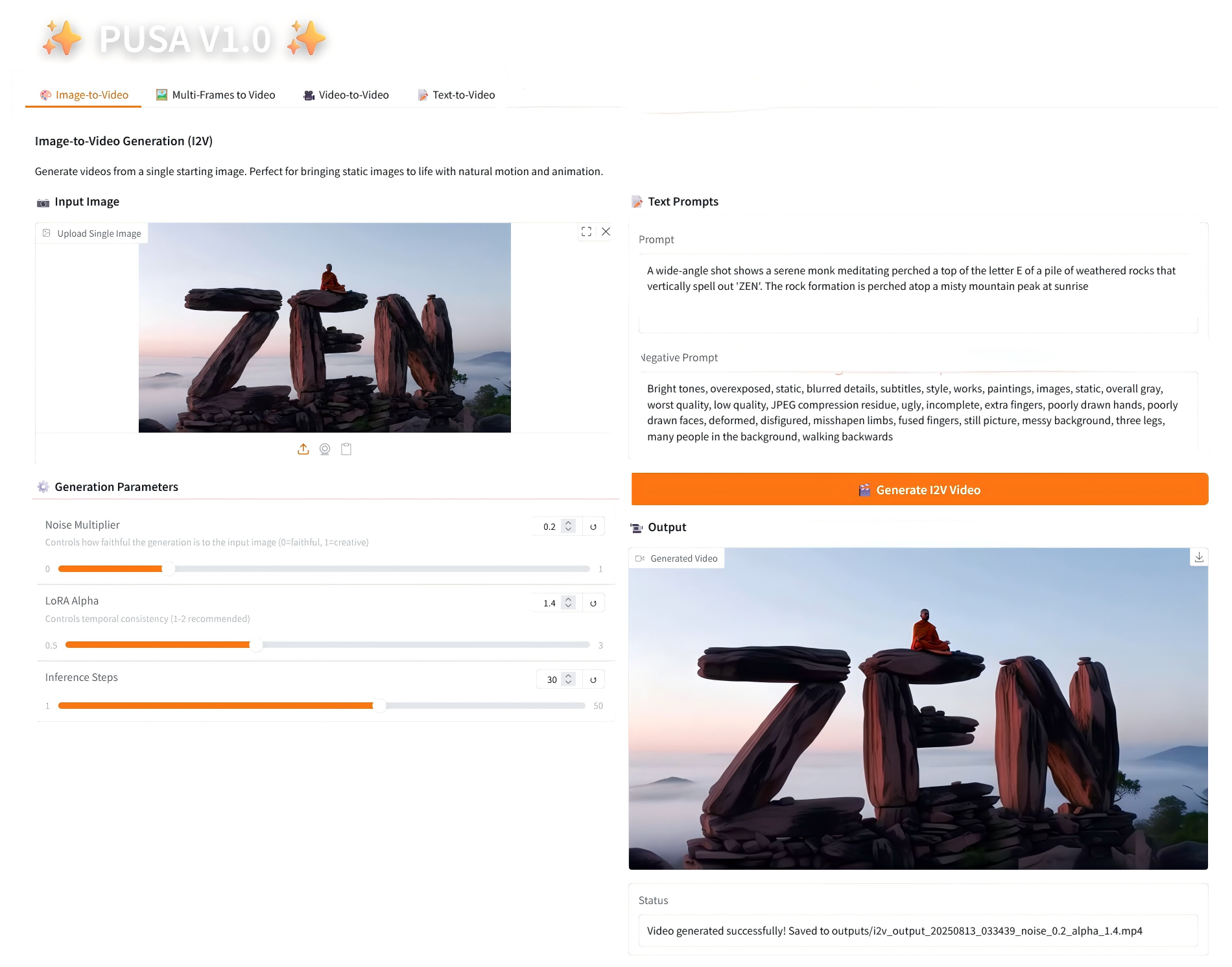
1. Image en vidéo
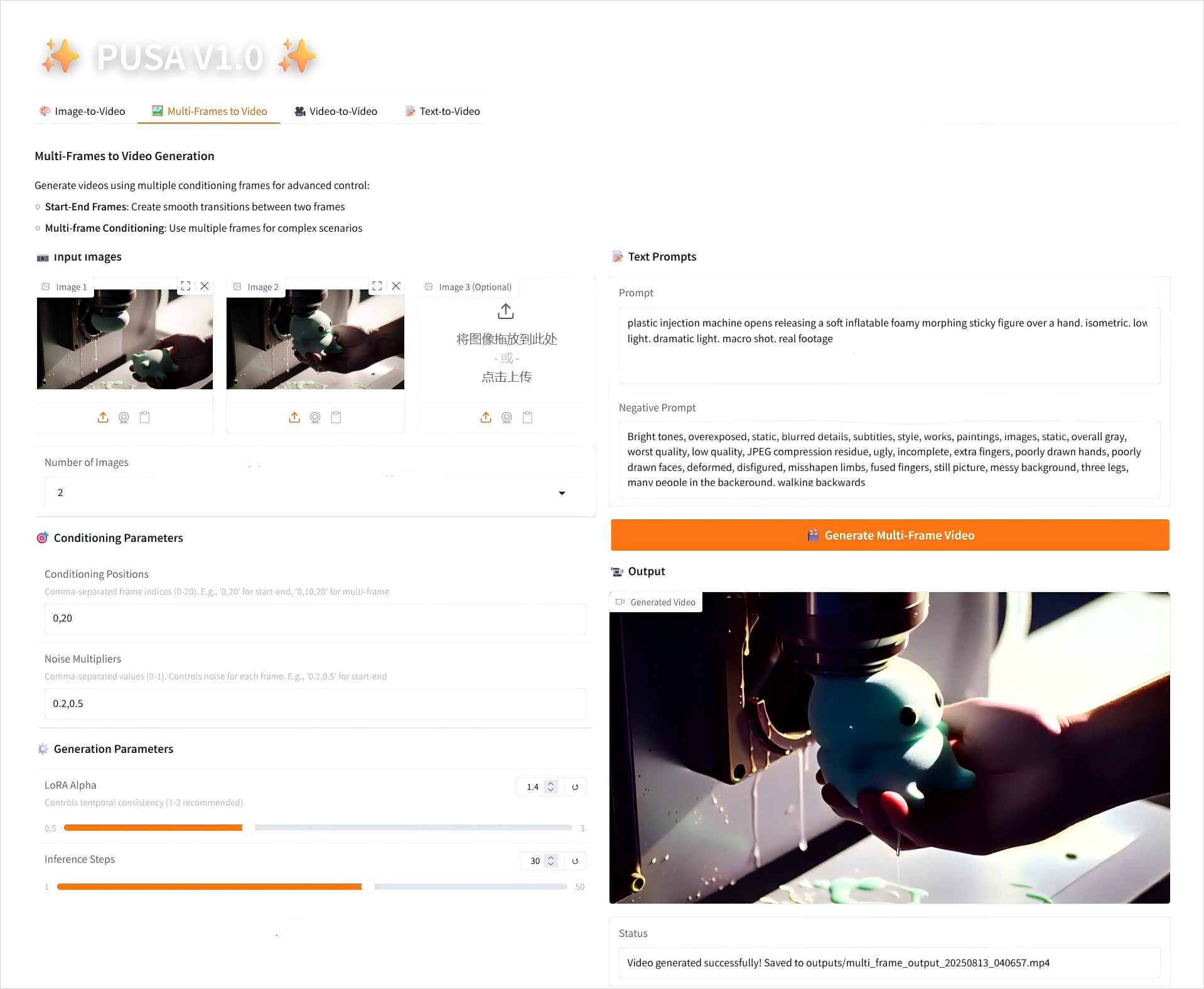
2. Multi-images en vidéo
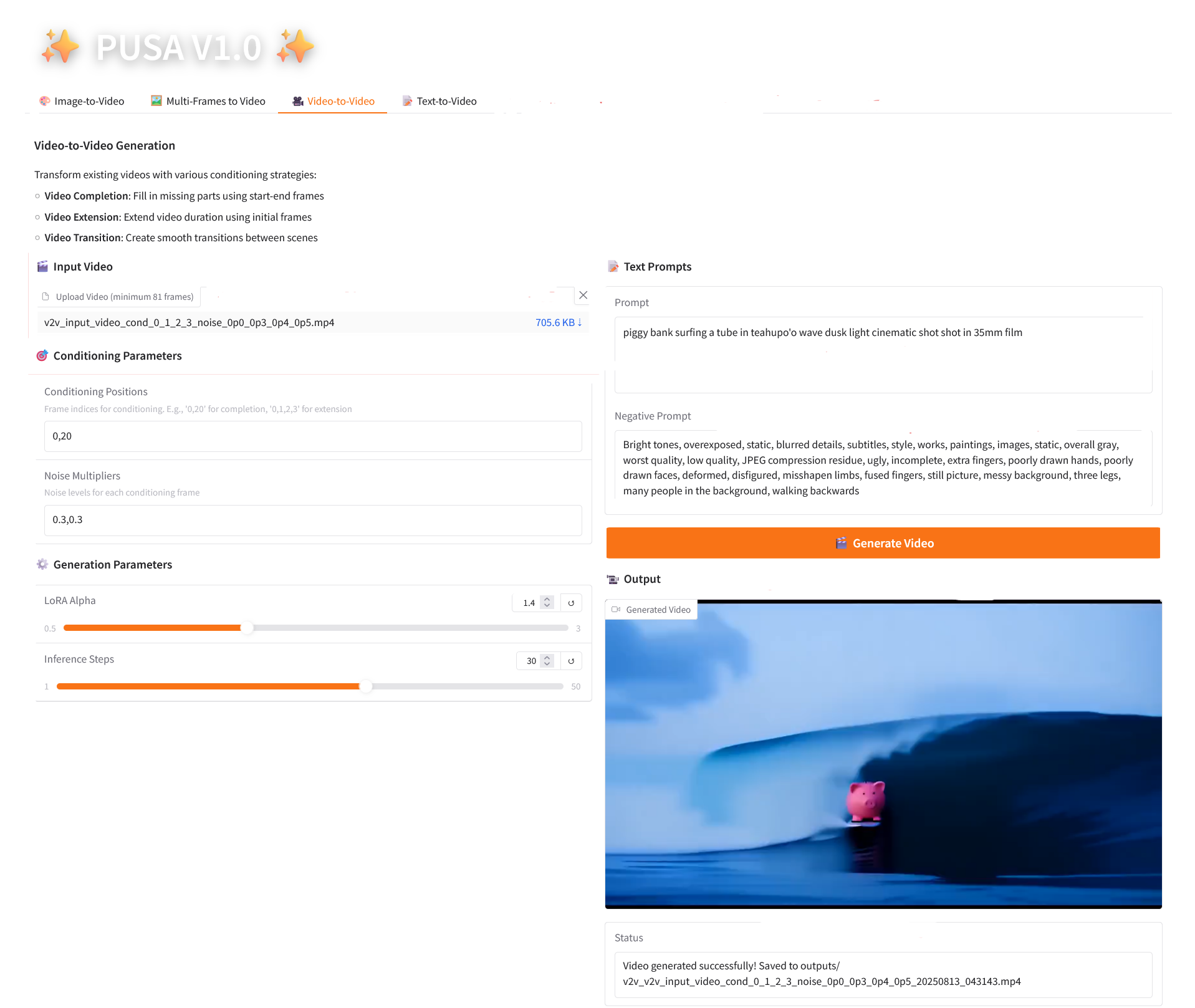
3. Vidéo vers vidéo
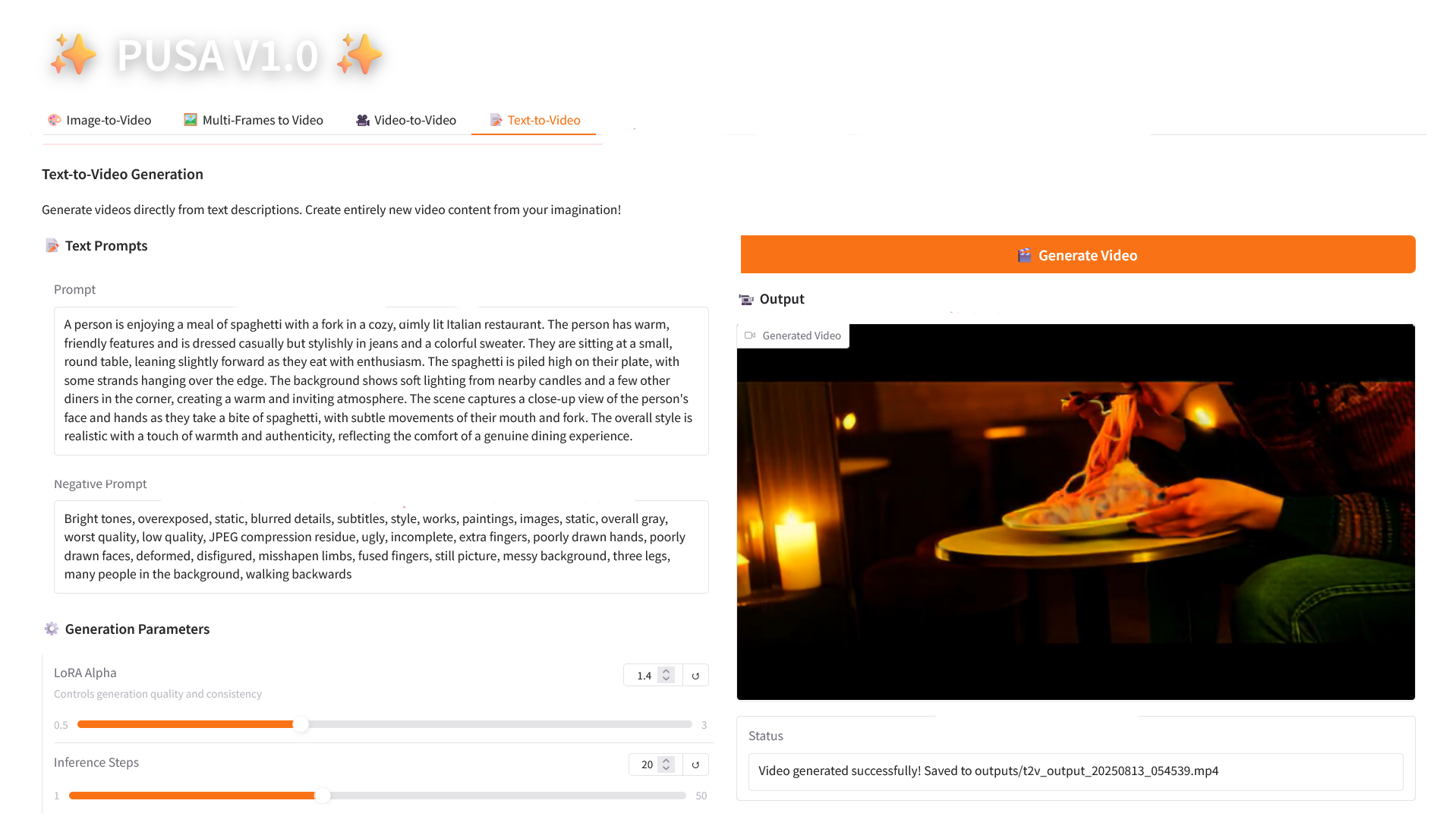
4. Texte en vidéo
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
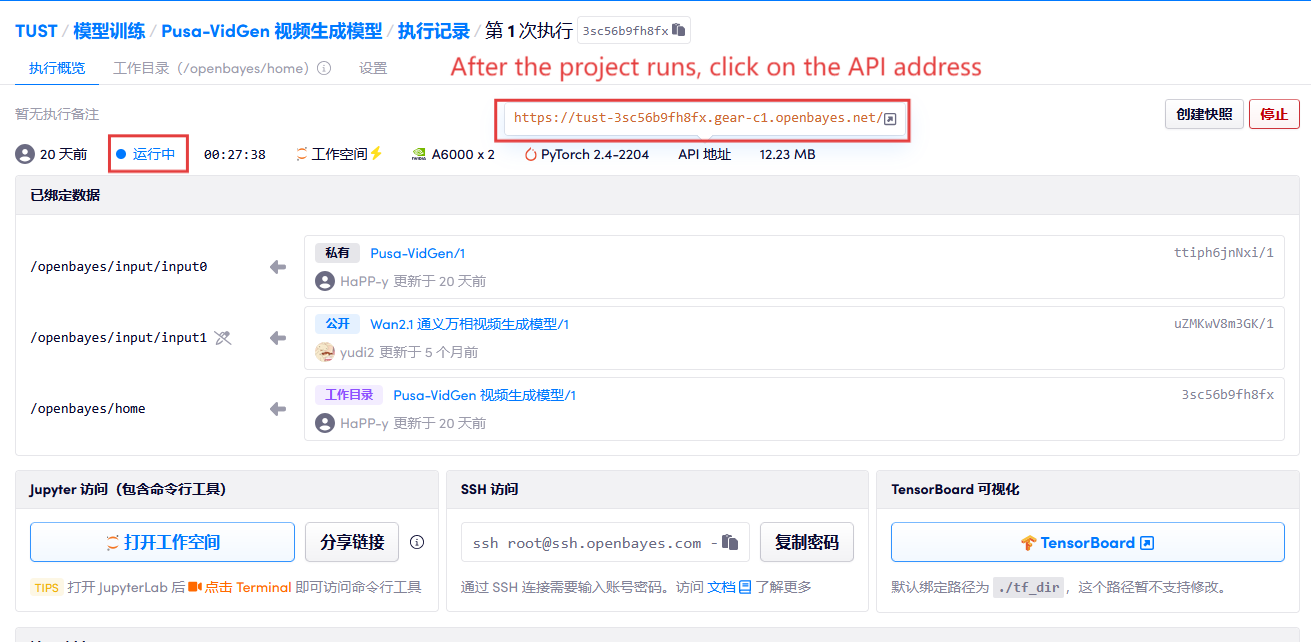
2. Étapes d'utilisation
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 2 à 3 minutes et actualiser la page.
2.1 Image vers vidéo
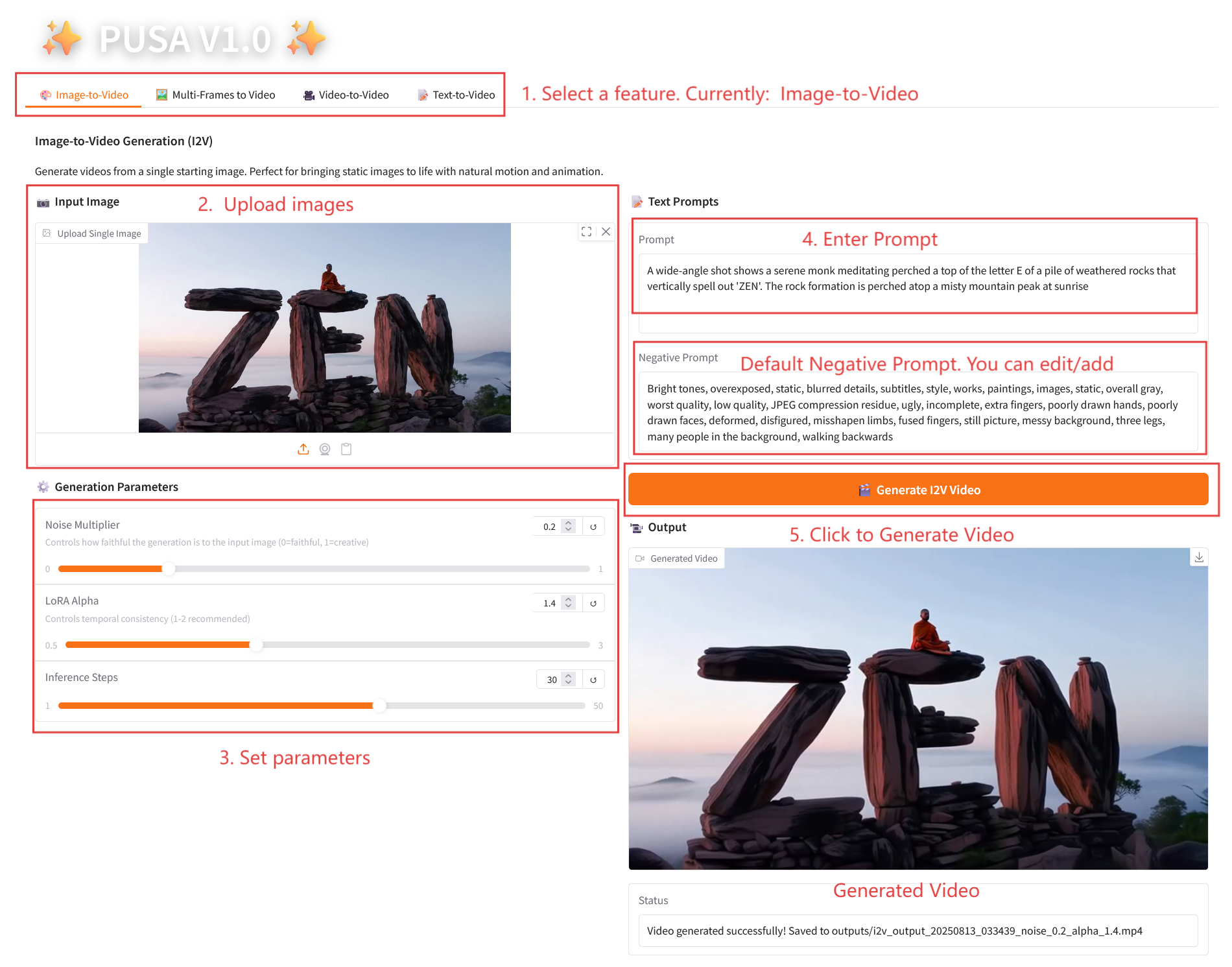
Description des paramètres
- Paramètres de génération
- Multiplicateur de bruit : réglable de 0,0 à 1,0, par défaut 0,2 (les valeurs inférieures sont plus fidèles à l'image d'entrée, les valeurs supérieures sont plus créatives).
- LoRA Alpha : 0,1-5,0 réglable, par défaut 1,4 (contrôle la cohérence du style, trop élevé et il sera rigide, trop bas et il perdra sa cohérence).
- Étapes d'inférence : réglables de 1 à 50, la valeur par défaut est 10 (plus le nombre d'étapes est élevé, plus les détails sont riches, mais le temps consommé augmente linéairement).
2.2 Multi-images en vidéo
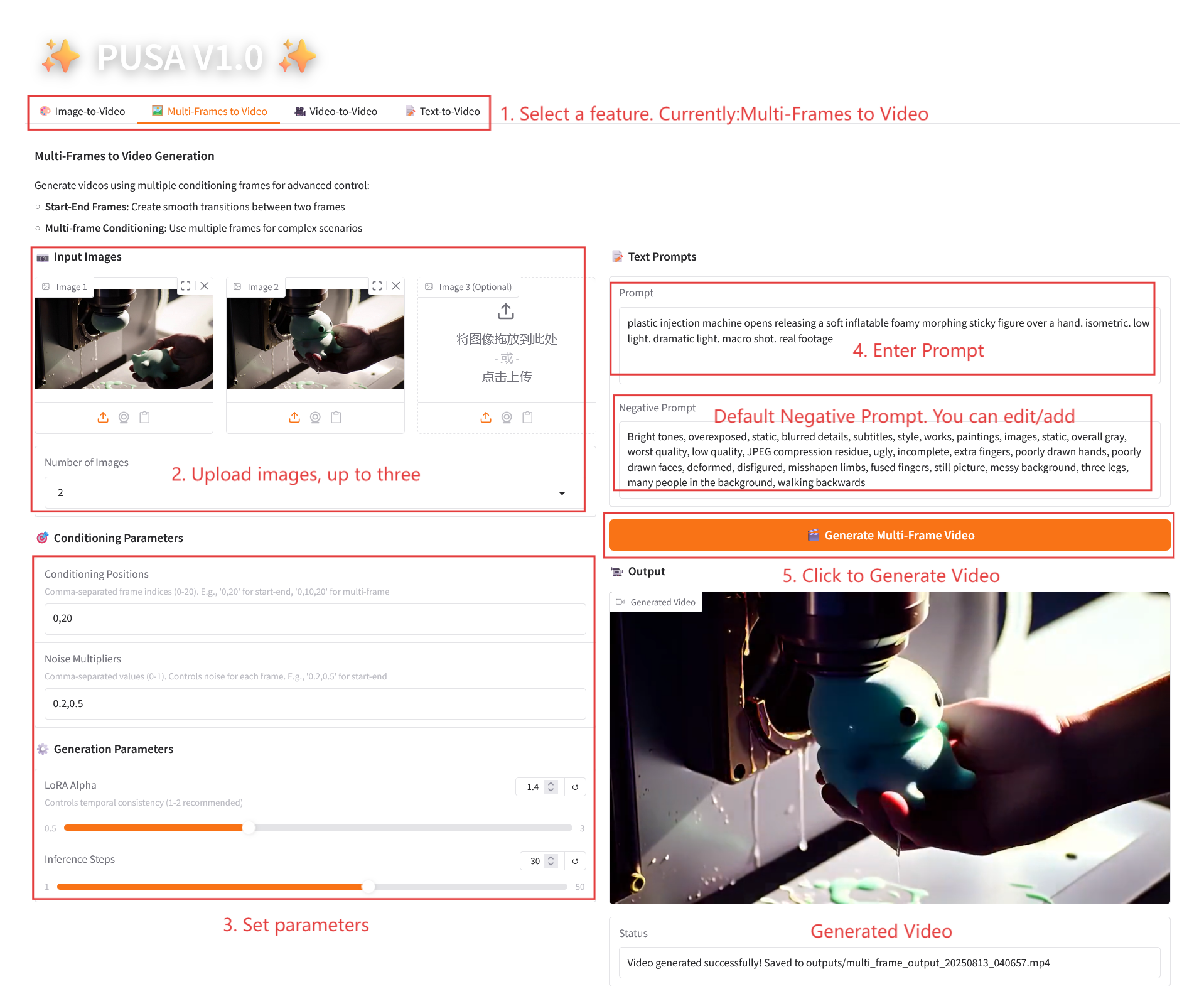
Description des paramètres
- Paramètres de conditionnement
- Positions de conditionnement : indices d'image séparés par des virgules (par exemple, « 0,20 » définit les points temporels des images clés dans la vidéo).
- Multiplicateurs de bruit : valeurs 0,0-1,0 séparées par des virgules (par exemple « 0,2,0,5 », correspondant à la liberté créative de chaque image clé, les valeurs inférieures sont plus fidèles à l'image, les valeurs supérieures sont plus variées).
- Paramètres de génération
- LoRA Alpha : 0,1-5,0 réglable, par défaut 1,4 (contrôle la cohérence du style, trop élevé et il sera rigide, trop bas et il perdra sa cohérence).
- Étapes d'inférence : réglables de 1 à 50, la valeur par défaut est 10 (plus le nombre d'étapes est élevé, plus les détails sont riches, mais le temps consommé augmente linéairement).
2.3 Vidéo vers vidéo
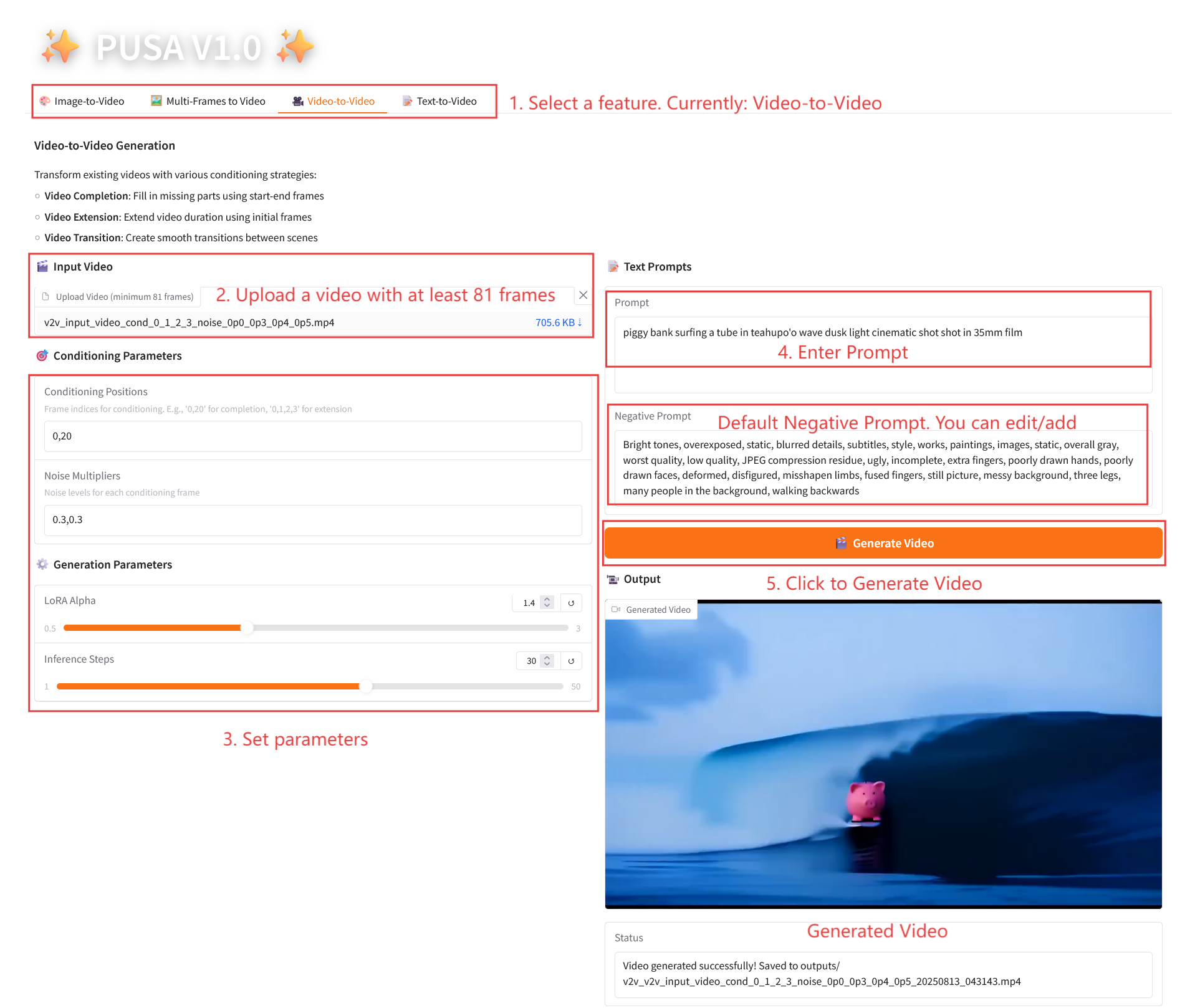
Description des paramètres
- Paramètres de conditionnement
- Positions de conditionnement : indices d'image séparés par des virgules (par exemple, « 0,1,2,3 », spécifiant les positions d'image clé dans la vidéo d'origine utilisées pour la génération de contraintes, obligatoire).
- Multiplicateurs de bruit : valeurs 0,0-1,0 séparées par des virgules (par exemple « 0,0,0,3 », correspondant au degré d'influence de chaque image conditionnelle, les valeurs inférieures sont plus proches de l'image d'origine, les valeurs supérieures sont plus flexibles).
- Paramètres de génération
- LoRA Alpha : 0,1-5,0 réglable, par défaut 1,4 (contrôle la cohérence du style, trop élevé et il sera rigide, trop bas et il perdra sa cohérence).
- Étapes d'inférence : réglables de 1 à 50, la valeur par défaut est 10 (plus le nombre d'étapes est élevé, plus les détails sont riches, mais le temps consommé augmente linéairement).
2.4 Texte en vidéo
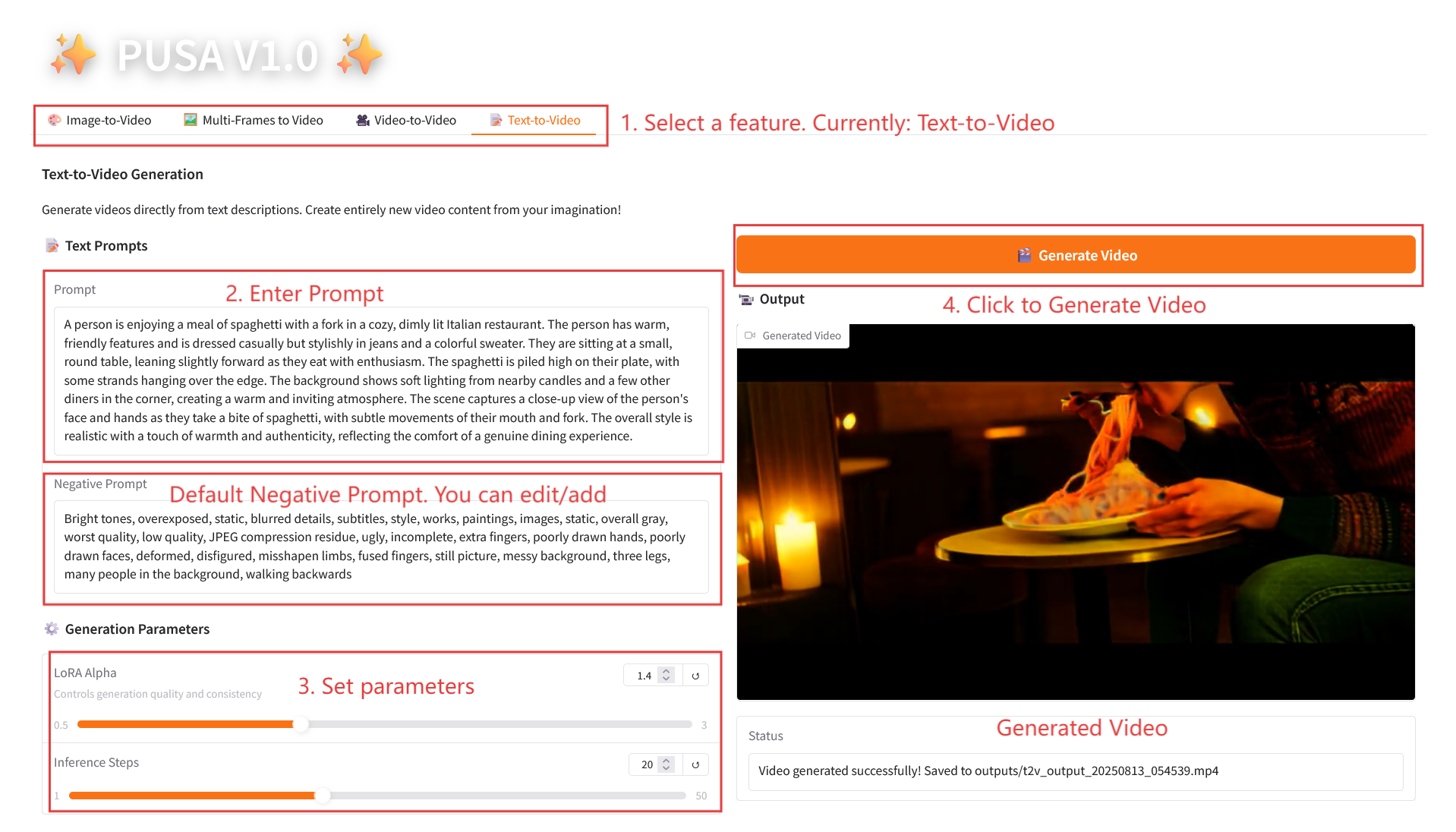
Description des paramètres
- Paramètres de génération
- LoRA Alpha : 0,1-5,0 réglable, par défaut 1,4 (contrôle la cohérence du style, trop élevé et il sera rigide, trop bas et il perdra sa cohérence).
- Étapes d'inférence : réglables de 1 à 50, la valeur par défaut est 10 (plus le nombre d'étapes est élevé, plus les détails sont riches, mais le temps consommé augmente linéairement).
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{liu2025pusa,
title={PUSA V1. 0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation},
author={Liu, Yaofang and Ren, Yumeng and Artola, Aitor and Hu, Yuxuan and Cun, Xiaodong and Zhao, Xiaotong and Zhao, Alan and Chan, Raymond H and Zhang, Suiyun and Liu, Rui and others},
journal={arXiv preprint arXiv:2507.16116},
year={2025}
}
@misc{Liu2025pusa,
title={Pusa: Thousands Timesteps Video Diffusion Model},
author={Yaofang Liu and Rui Liu},
year={2025},
url={https://github.com/Yaofang-Liu/Pusa-VidGen},
}
@article{liu2024redefining,
title={Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach},
author={Liu, Yaofang and Ren, Yumeng and Cun, Xiaodong and Artola, Aitor and Liu, Yang and Zeng, Tieyong and Chan, Raymond H and Morel, Jean-michel},
journal={arXiv preprint arXiv:2410.03160},
year={2024}
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.