Command Palette
Search for a command to run...
VIRES: Sketch-and-text dual-guided Video Redrawing
Date
Size
48.17 MB
Tags
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

VIRES is a video instance redrawing method that combines sketches and text guidance, jointly proposed in 2025 by the Camera Intelligence Laboratory of Peking University (Shi Baixin's team) in conjunction with OpenBayes Bayesian Computing and the team of Associate Professor Li Si from the Pattern Recognition Laboratory of the School of Artificial Intelligence of Beijing University of Posts and Telecommunications. It supports a variety of editing operations such as redrawing, replacement, generation and removal of video subjects. This method uses the prior knowledge of the text-generated video model to ensure temporal consistency. It also proposes a Sequential ControlNet with a standardized adaptive scaling mechanism, which can effectively extract structural layouts and adaptively capture high-contrast sketch details. Furthermore, the research team introduced a sketch attention mechanism in the DiT (diffusion transformer) backbone to interpret and inject fine-grained sketch semantics. Experimental results show that VIRES outperforms existing SOTA models in many aspects such as video quality, temporal consistency, conditional alignment and user ratings.
Related research VIRES: Video Instance Repainting via Sketch and Text Guided Generation The topic has been selected for CVPR 2025.
This tutorial uses resources for a single card A6000.
2. Project Examples

3. Operation steps
1. After starting the container, click the API address to enter the Web interface

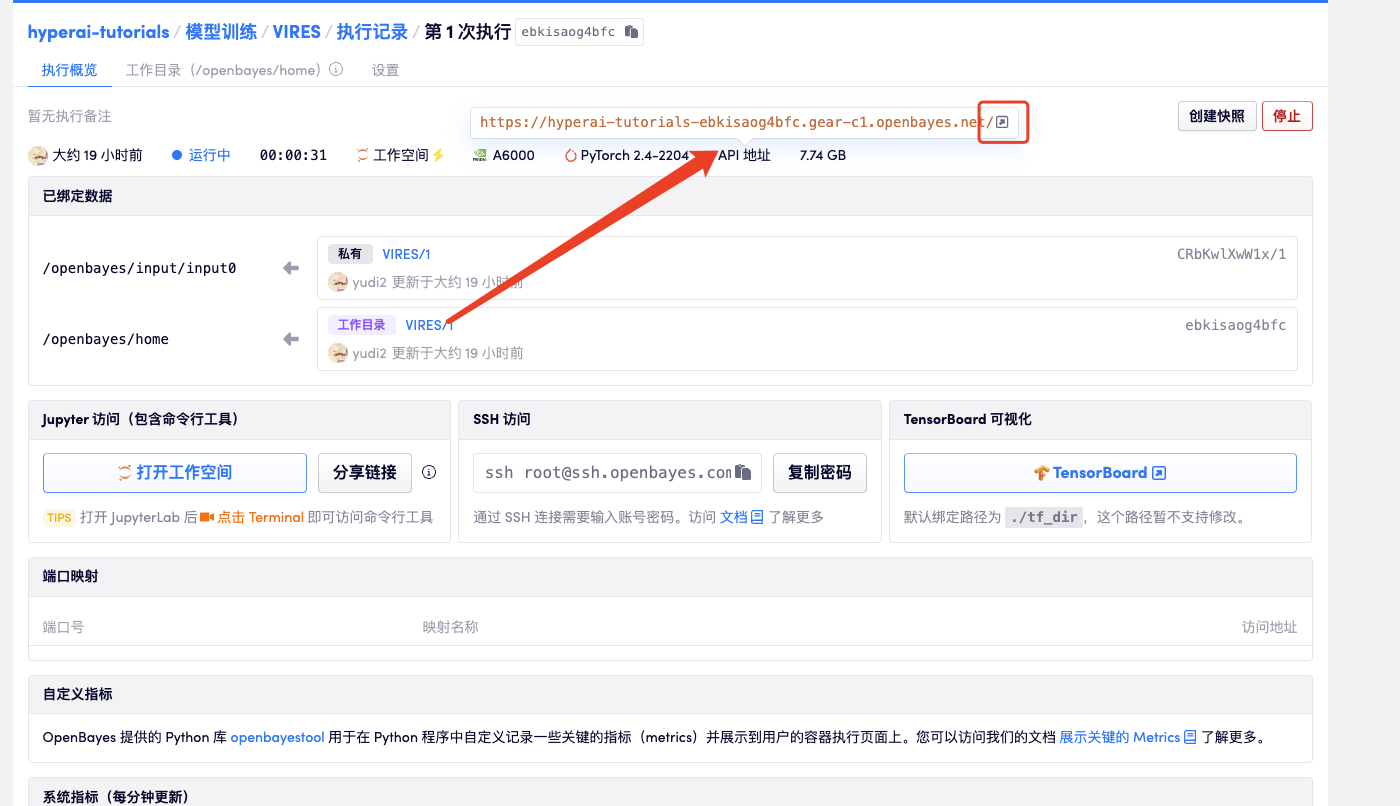
2. Once you enter the webpage, you can use the model
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
How to use
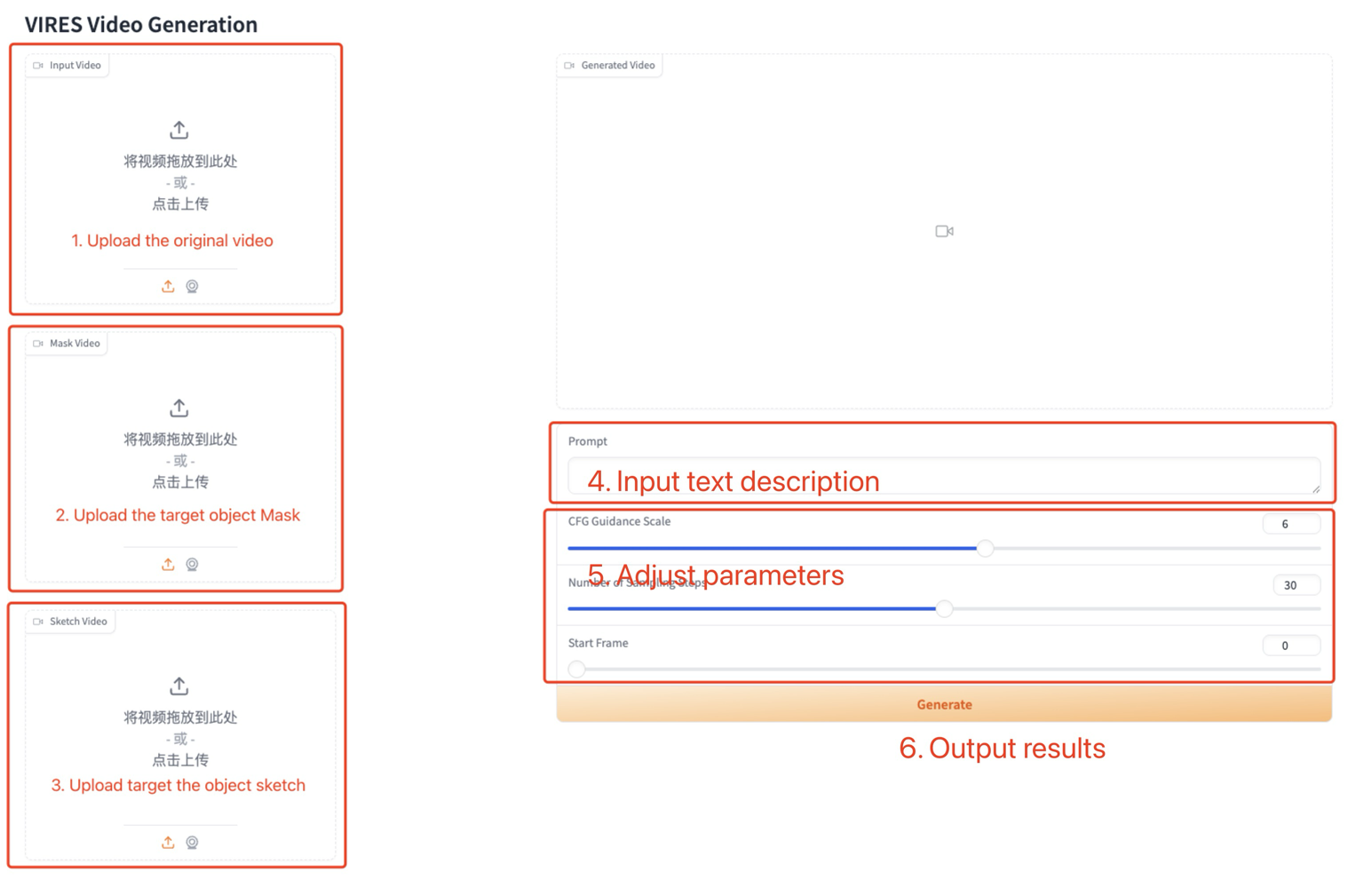
Parameter Description:
- CFG Guidance Scale: Unconditional guidance strength.
- Number of Sampling Steps: Number of sampling steps.
- Start Frame: Edit the start frame.
Citation Information
@article{vires,
title={VIRES: Video Instance Repainting via Sketch and Text Guided Generation},
author={Weng, Shuchen and Zheng, Haojie and Zhang, Peixuan and Hong, Yuchen and Jiang, Han and Li, Si and Shi, Boxin},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={28416--28425},
year={2025}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.