Command Palette
Search for a command to run...
Nanonets-OCR-s: Document Information Extraction and Benchmarking Tool
1. Tutorial Introduction

Nanonets-OCR-s is an optical character recognition (OCR) model released by Nanonets on June 10, 2025. Ordinary OCR technology mainly focuses on extracting plain text from images, while Nanonets-OCR-s goes a step further. It can recognize multiple elements in documents, such as mathematical formulas, pictures, signatures, watermarks, checkboxes, and tables, and organize them into a structured Markdown format. This ability allows it to perform well when processing complex documents, such as academic papers, legal documents, or business reports. Its output is not only easy for humans to read, but also provides a solid foundation for downstream automated processing.
This tutorial uses a single RTX 4090 card as the resource. This tutorial contains two functions: 1. Extract information from documents. 2. Convert images and PDFs to Markdown.
2. Project Examples
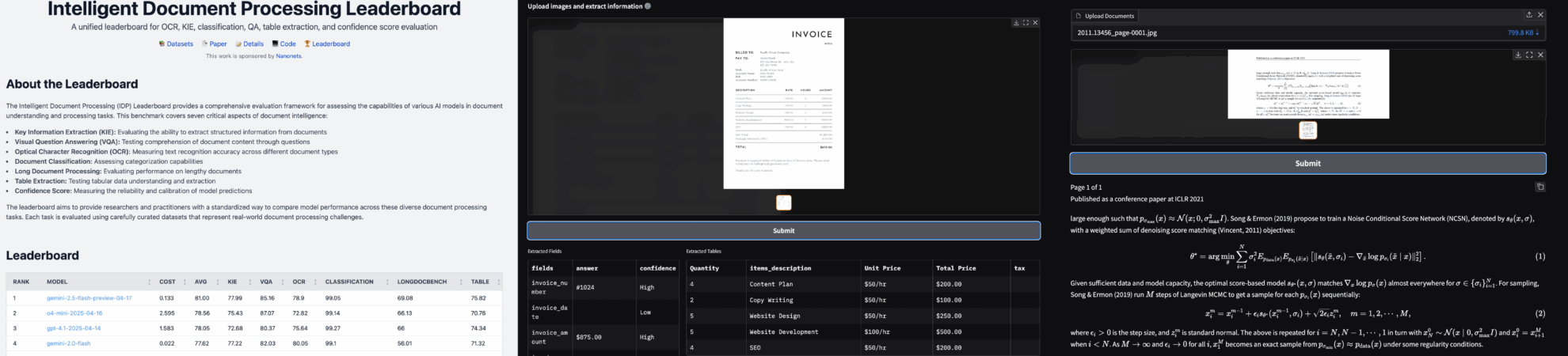
3. Operation steps
1. After starting the container, click the API address to enter the Web interface
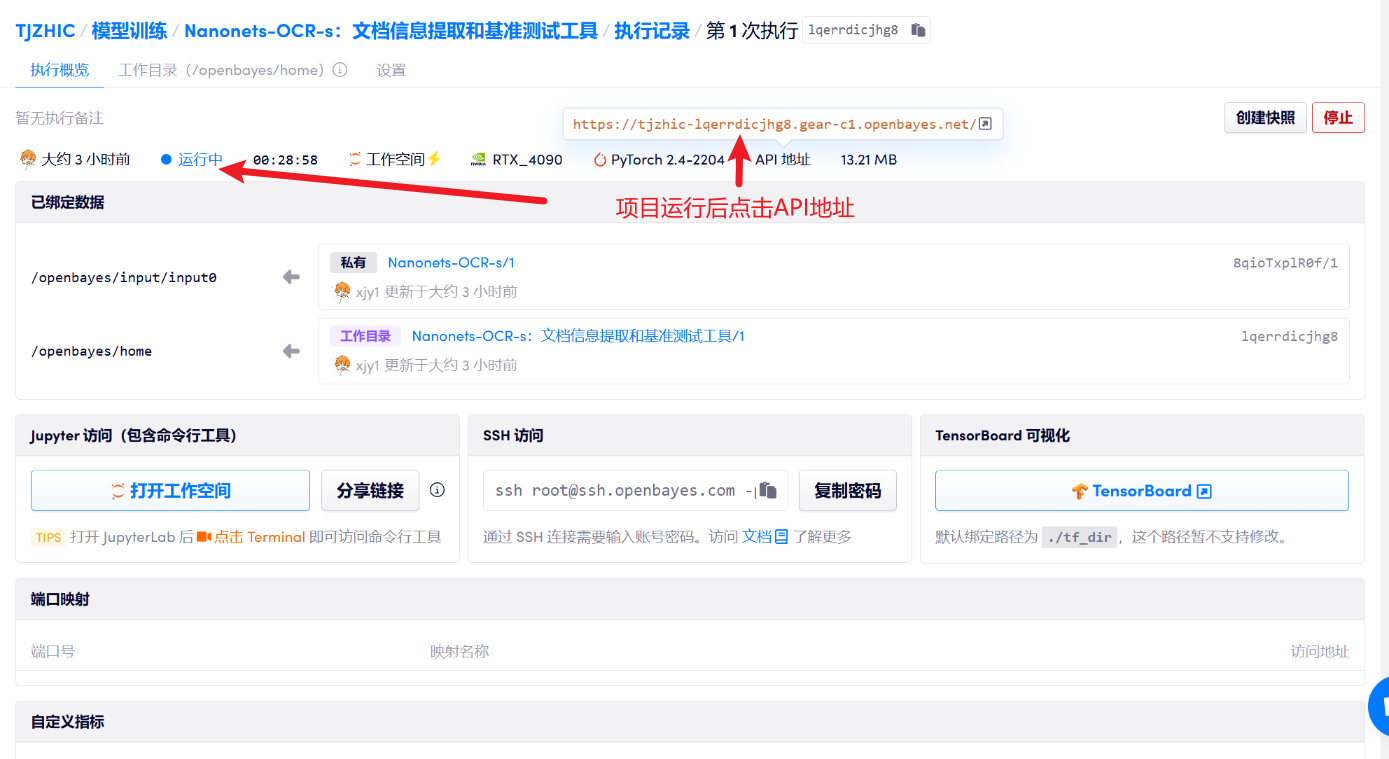
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
2.1 Extracting information from documents
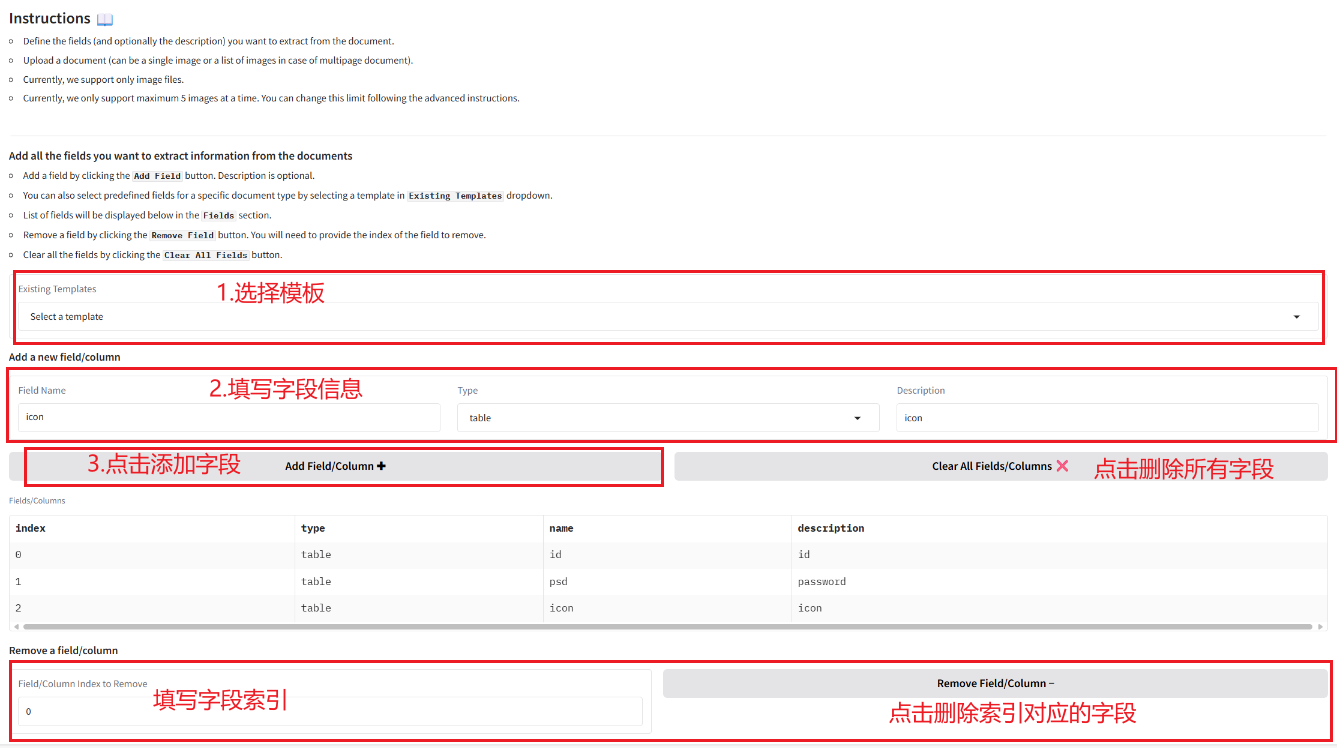
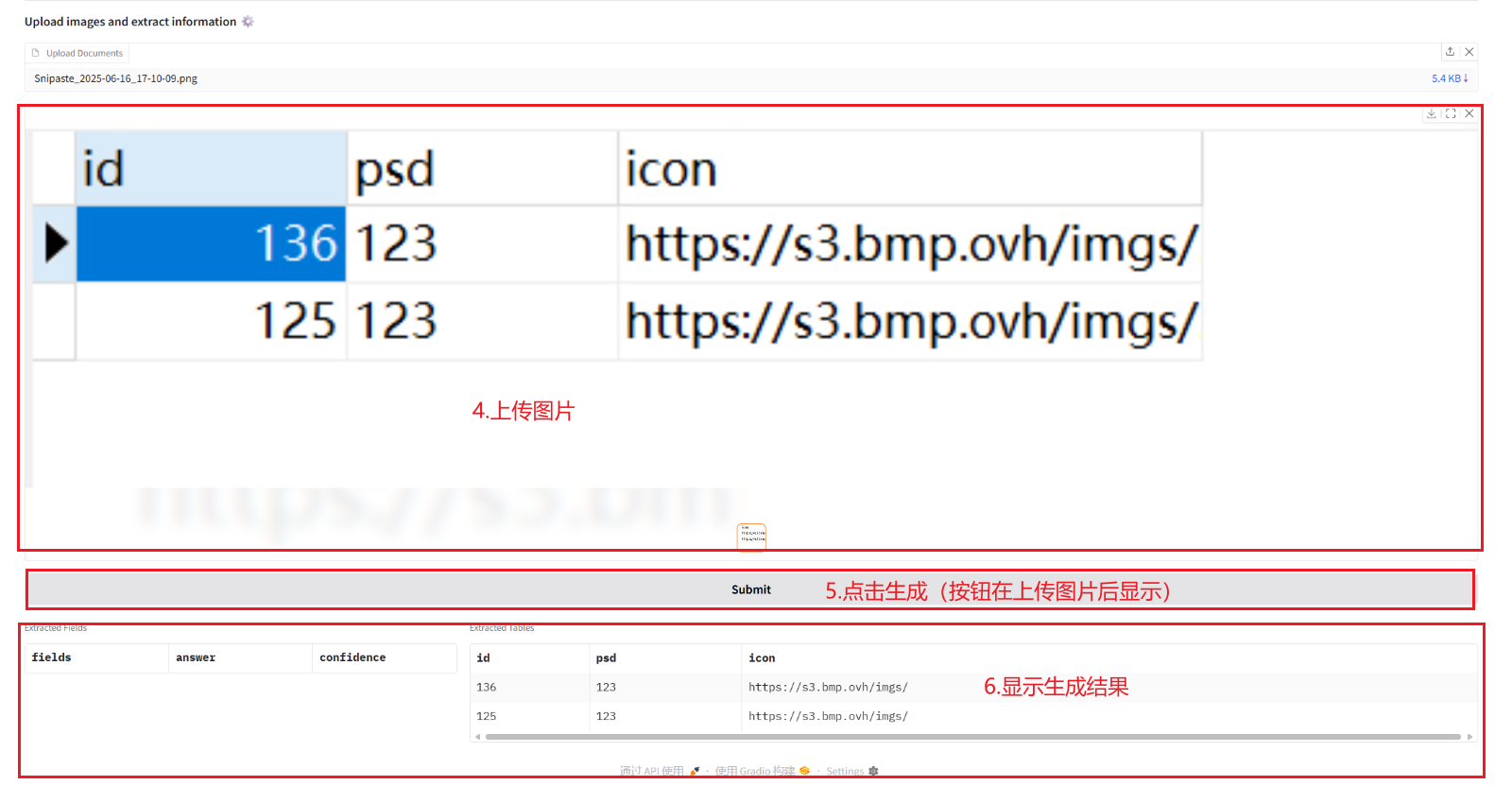
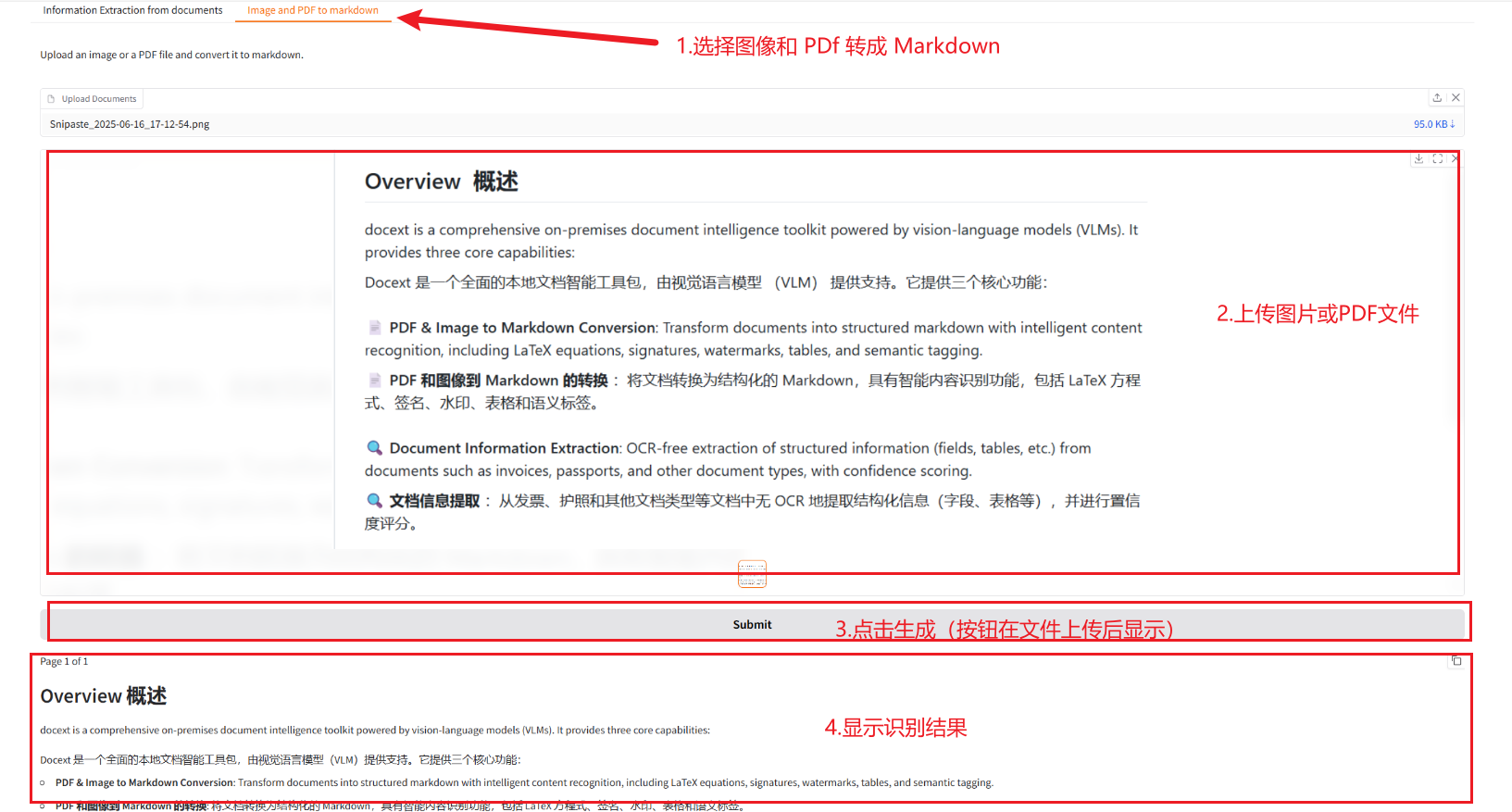
2.2 Convert images and PDF to Markdown
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.