Command Palette
Search for a command to run...
YOLOE: See Everything in Real Time
Date
Size
1.94 GB
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

YOLOE is a novel real-time vision model proposed by a research team at Tsinghua University in 2025, aiming to achieve the goal of "seeing everything in real time." It inherits the real-time and efficient characteristics of the YOLO series models and deeply integrates zero-shot learning and multimodal prompting capabilities, enabling object detection and segmentation in various scenarios, including text, vision, and unhinted scenarios. Related research papers are available. YOLOE: Real-Time Seeing Anything .
Since its launch in 2015, YOLO (You Only Look Once) has been a leader in object detection and image segmentation.The following is the evolution of the YOLO series and related tutorials:
- YOLOv2 (2016): Introducing batch normalization, anchor boxes, and dimension clustering.
- YOLOv3 (2018): Using more efficient backbone networks, multi-anchors and spatial pyramid pooling.
- YOLOv4 (2020): Introducing Mosaic data augmentation, anchor-free detection head and new loss function. → Tutorial:DeepSOCIAL realizes crowd distance monitoring based on YOLOv4 and sort multi-target tracking
- YOLOv5 (2020): Added hyperparameter optimization, experiment tracking, and automatic export capabilities. → Tutorial:YOLOv5_deepsort real-time multi-target tracking model
- YOLOv6 (2022): Meituan open source, widely used in autonomous delivery robots.
- YOLOv7 (2022): Supports pose estimation for the COCO keypoint dataset. → Tutorial:How to train and use a custom YOLOv7 model
- YOLOv8 (2023):Ultralytics released, supporting a full range of visual AI tasks. → Tutorial:Training YOLOv8 with custom data
- YOLOv9 (2024): Introducing Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN).
- YOLOv10 (2024): Tsinghua University introduced an end-to-end header and eliminated the non-maximum suppression (NMS) requirement. → Tutorial:YOLOv10 real-time end-to-end object detection
- YOLOv11(2024):Ultralytics latest model, supporting detection, segmentation, pose estimation, tracking and classification. → Tutorial:One-click deployment of YOLOv11
- YOLOv12 🚀 NEW(2025): The dual peaks of speed and accuracy, combined with the performance advantages of the attention mechanism!
Core Features
- Any text type

2. Multimodal prompts:
- Visual cues (boxes/dots/hand-drawn shapes/reference images)

- Fully automatic silent detection – Automatically identify scene objects

Demo environment: YOLOv8e/YOLOv11e series + RTX4090
2. Operation steps
1. After starting the container, click the API address to enter the Web interface
If "Bad Gateway" is displayed, it means the model is initializing. Please wait for about 1-2 minutes and refresh the page.

2. YOLOE function demonstration
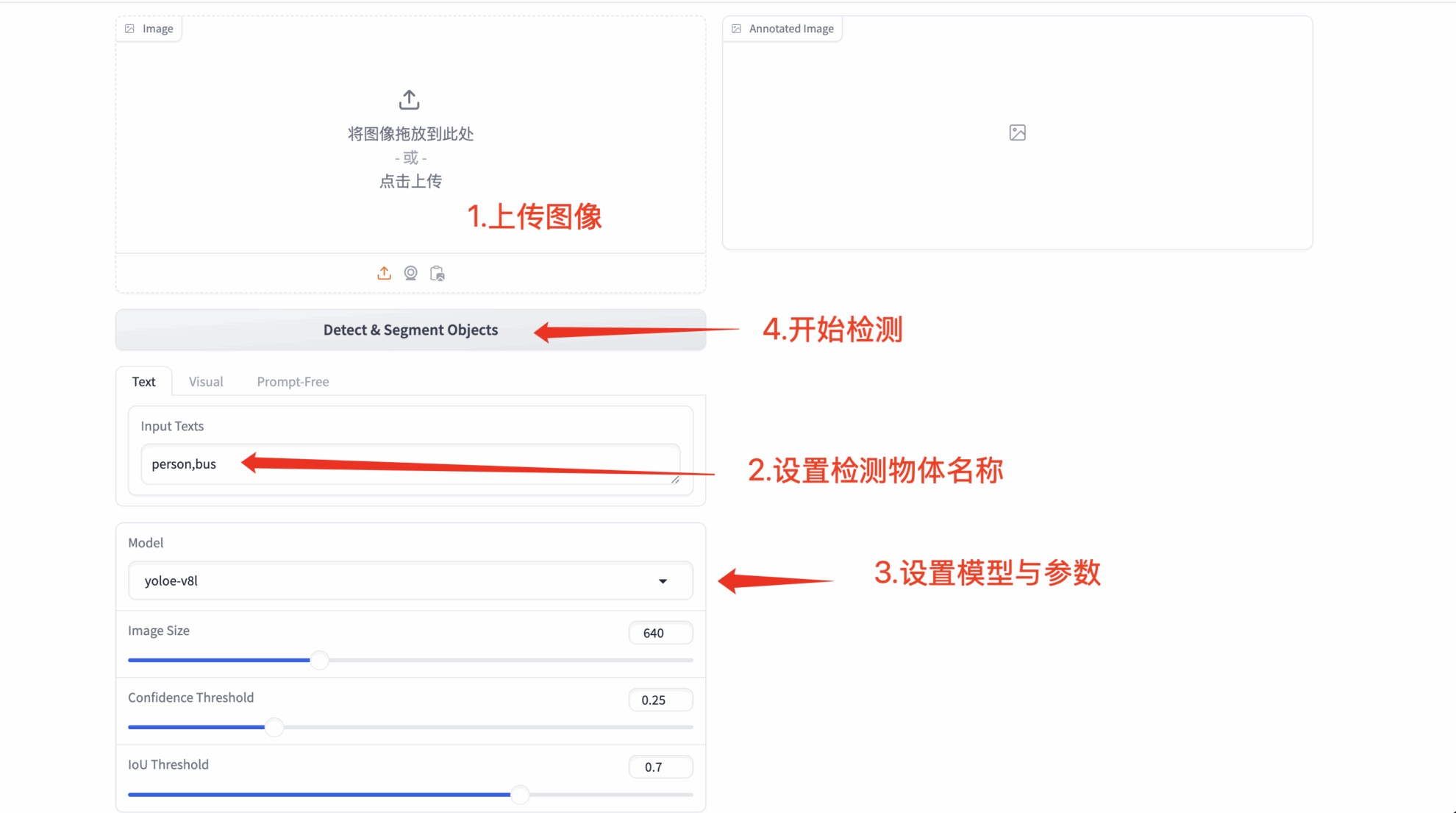
1. Text prompt detection
- Any text type
- Custom prompt words: Allows the user to enter arbitrary text (recognition results may vary depending on semantic complexity)

2. Multimodal visual cues
- 🟦 Box selection detection (bboxes)
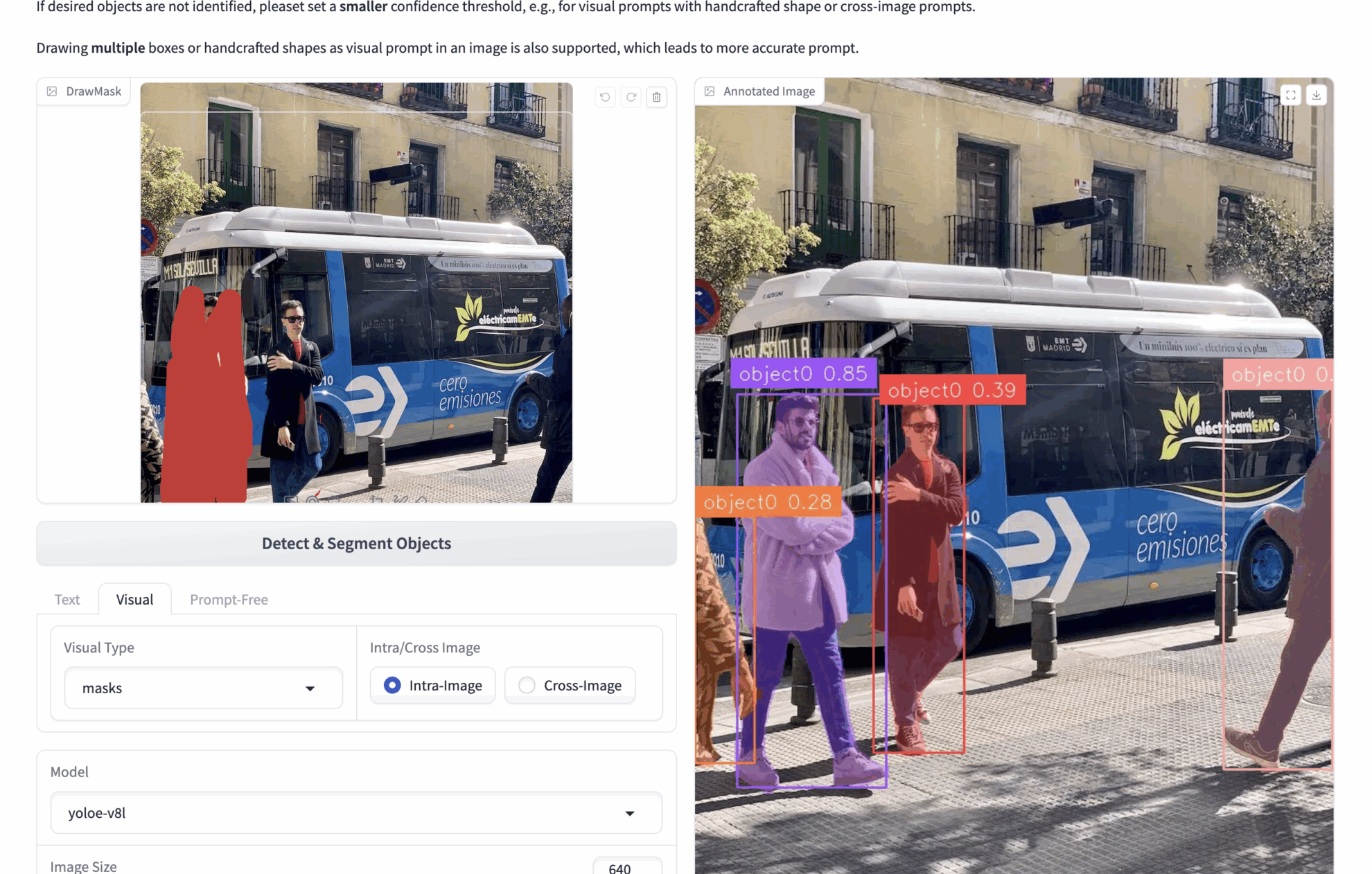
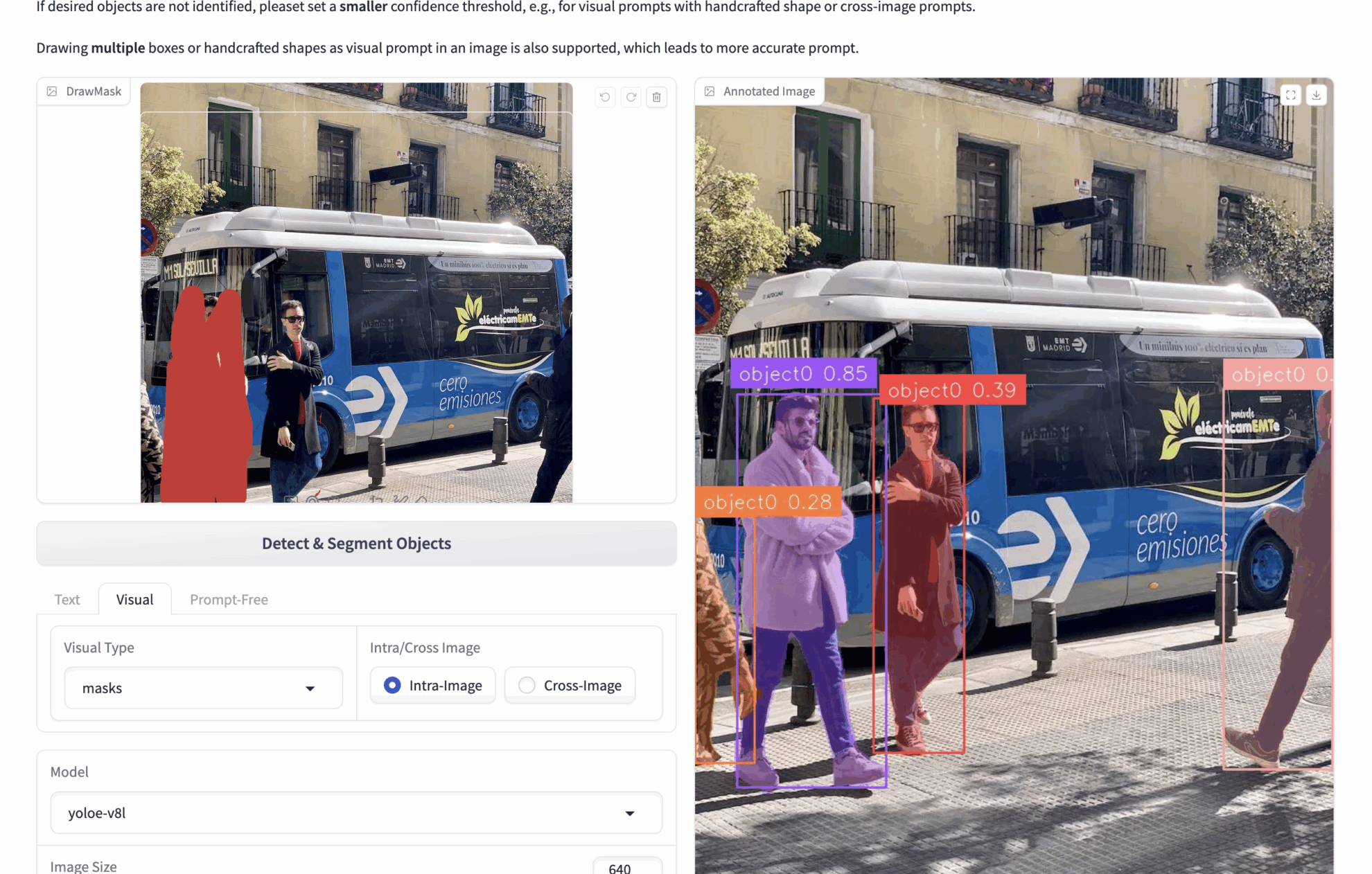
bboxes: For example, if you upload an image containing many people and want to detect people in the image, you can use bboxes to frame one person. During inference, the model will identify all the people in the image based on the content of the bboxes.
Multiple bboxes can be drawn to get more accurate visual cues. - ✏️ Click/draw area (masks)
Masks: For example, if you upload an image containing many people and want to detect people in the image, you can use masks to cover one person. During inference, the model will recognize all the people in the image based on the content of the masks.
You can draw multiple masks to get more accurate visual cues. - 🖼️ Reference image comparison (Intra/Cross)
Intra: Operate bboxes or masks on the current image and perform inference on the current image.
Cross: Operate bboxes or masks on the current image and infer on other images.
Core Concepts
| model | Functional Description | Application Scenario |
|---|---|---|
| Intra-image | Modeling object relationships within a single graph | Local target precise positioning |
| Cross-image | Cross-image feature matching | Similar object retrieval |

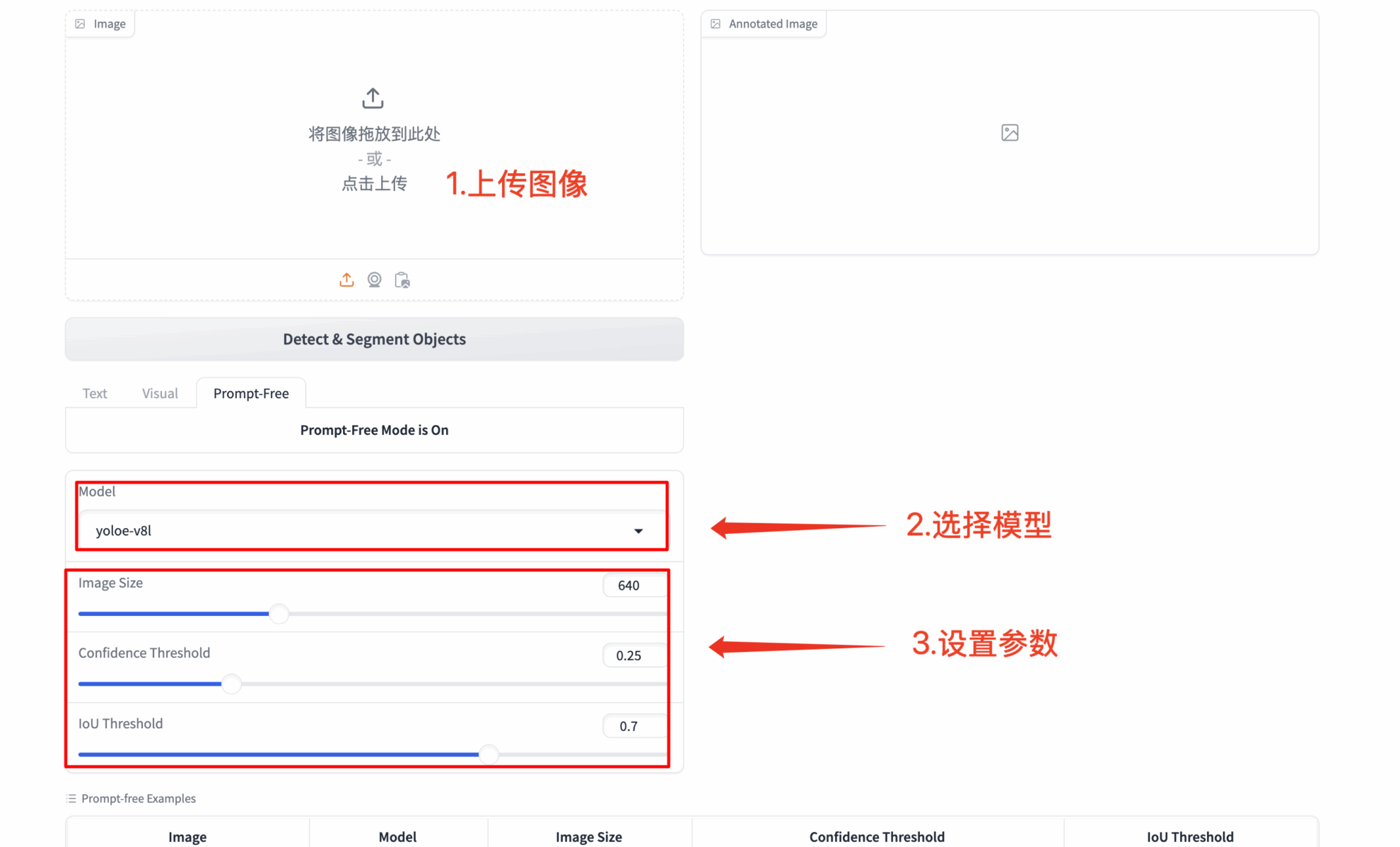
3. Fully automatic detection without prompting
- 🔍 Intelligent scene analysis: Automatically identify all salient objects in an image
- 🚀 Zero configuration startup: Works without any prompt input

Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.