Command Palette
Search for a command to run...
One-click Deployment of YOLOv12
1. Tutorial Introduction 📖

YOLOv12 was launched in 2025 by researchers from the University at Buffalo and the University of Chinese Academy of Sciences. The related research paper is as follows: YOLOv12: Attention-Centric Real-Time Object Detectors .
YOLOv12’s Breakthrough Performance
- YOLOv12-N achieves a mAP of 40.6% with an inference latency of 1.64 milliseconds on a T4 GPU, which is 2.1%/1.2% higher than YOLOv10-N/YOLOv11-N.
- YOLOv12-S beats RT-DETR-R18 / RT-DETRv2-R18, running 42% faster, using only 36% of computation, and reducing parameters by 45%.
📜 YOLO development history and related tutorials
Since its launch in 2015, YOLO (You Only Look Once) has been a leader in object detection and image segmentation.The following is the evolution of the YOLO series and related tutorials:
- YOLOv2 (2016): Introducing batch normalization, anchor boxes, and dimension clustering.
- YOLOv3 (2018): Using more efficient backbone networks, multi-anchors and spatial pyramid pooling.
- YOLOv4 (2020): Introducing Mosaic data augmentation, anchor-free detection head and new loss function. → Tutorial:DeepSOCIAL realizes crowd distance monitoring based on YOLOv4 and sort multi-target tracking
- YOLOv5 (2020): Added hyperparameter optimization, experiment tracking, and automatic export capabilities. → Tutorial:YOLOv5_deepsort real-time multi-target tracking model
- YOLOv6 (2022): Meituan open source, widely used in autonomous delivery robots.
- YOLOv7 (2022): Supports pose estimation for the COCO keypoint dataset. → Tutorial:How to train and use a custom YOLOv7 model
- YOLOv8 (2023):Ultralytics released, supporting a full range of visual AI tasks. → Tutorial:Training YOLOv8 with custom data
- YOLOv9 (2024): Introducing Programmable Gradient Information (PGI) and Generalized Efficient Layer Aggregation Network (GELAN).
- YOLOv10 (2024): Tsinghua University introduced an end-to-end header and eliminated the non-maximum suppression (NMS) requirement. → Tutorial:YOLOv10 real-time end-to-end object detection
- YOLOv11(2024):Ultralytics latest model, supporting detection, segmentation, pose estimation, tracking and classification. → Tutorial:One-click deployment of YOLOv11
- YOLOv12 🚀 NEW(2025): The dual peaks of speed and accuracy, combined with the performance advantages of the attention mechanism!
This tutorial uses RTX 4090 as the computing resource.
2. Operation steps🛠️
1. After starting the container, click the API address to enter the Web interface

The output of an object detector is a set of bounding boxes that enclose the objects in the image, along with a class label and a confidence score for each bounding box. Object detection is a good choice if you need to identify objects of interest in a scene but don’t need to know their exact location or shape.
It is divided into the following two functions:
- Image detection
- Video Detection
2. Image detection
The input is an image and the output is an image with labels.
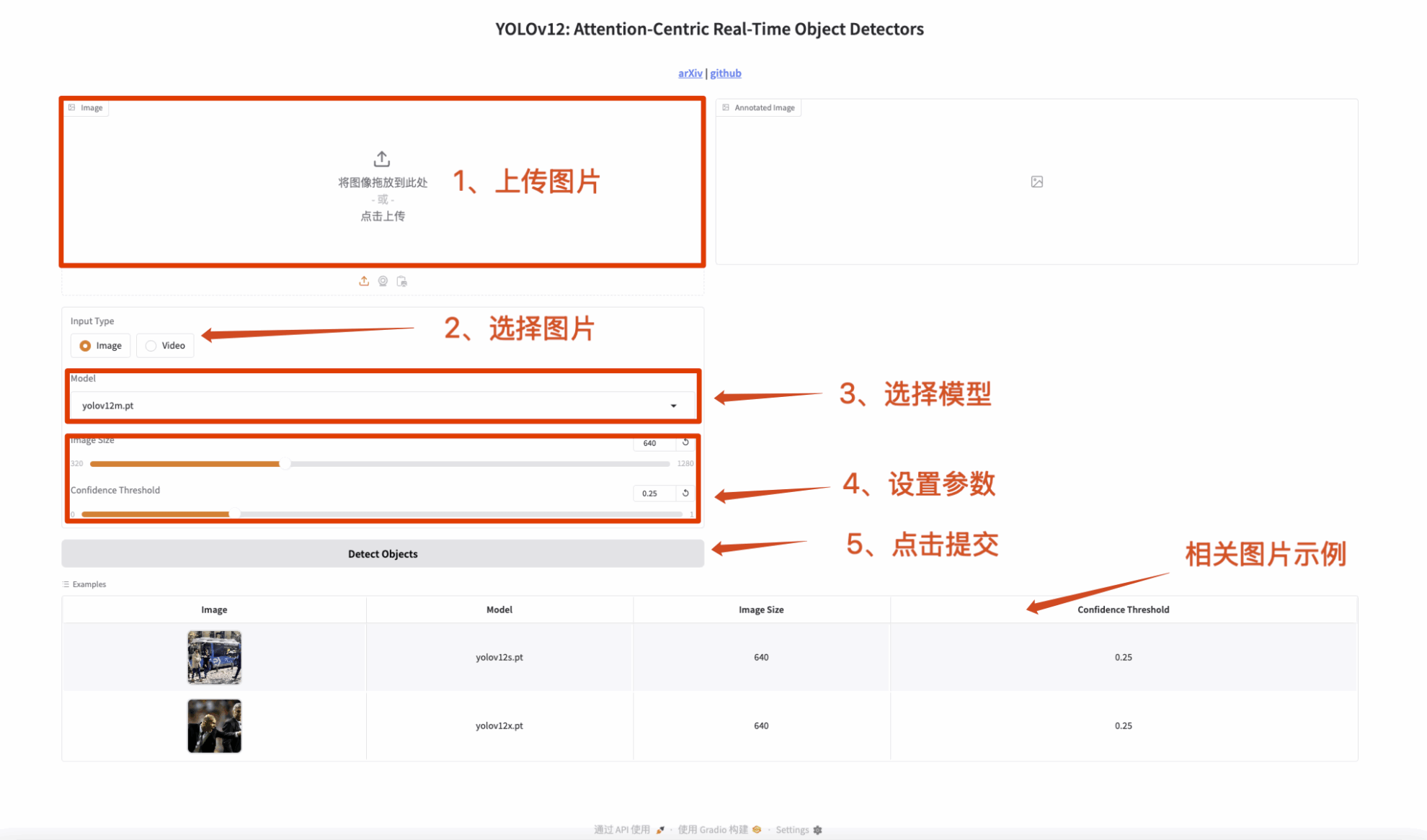

Figure 1 Image detection
3. Video Detection
The input is a video and the output is a video with labels.
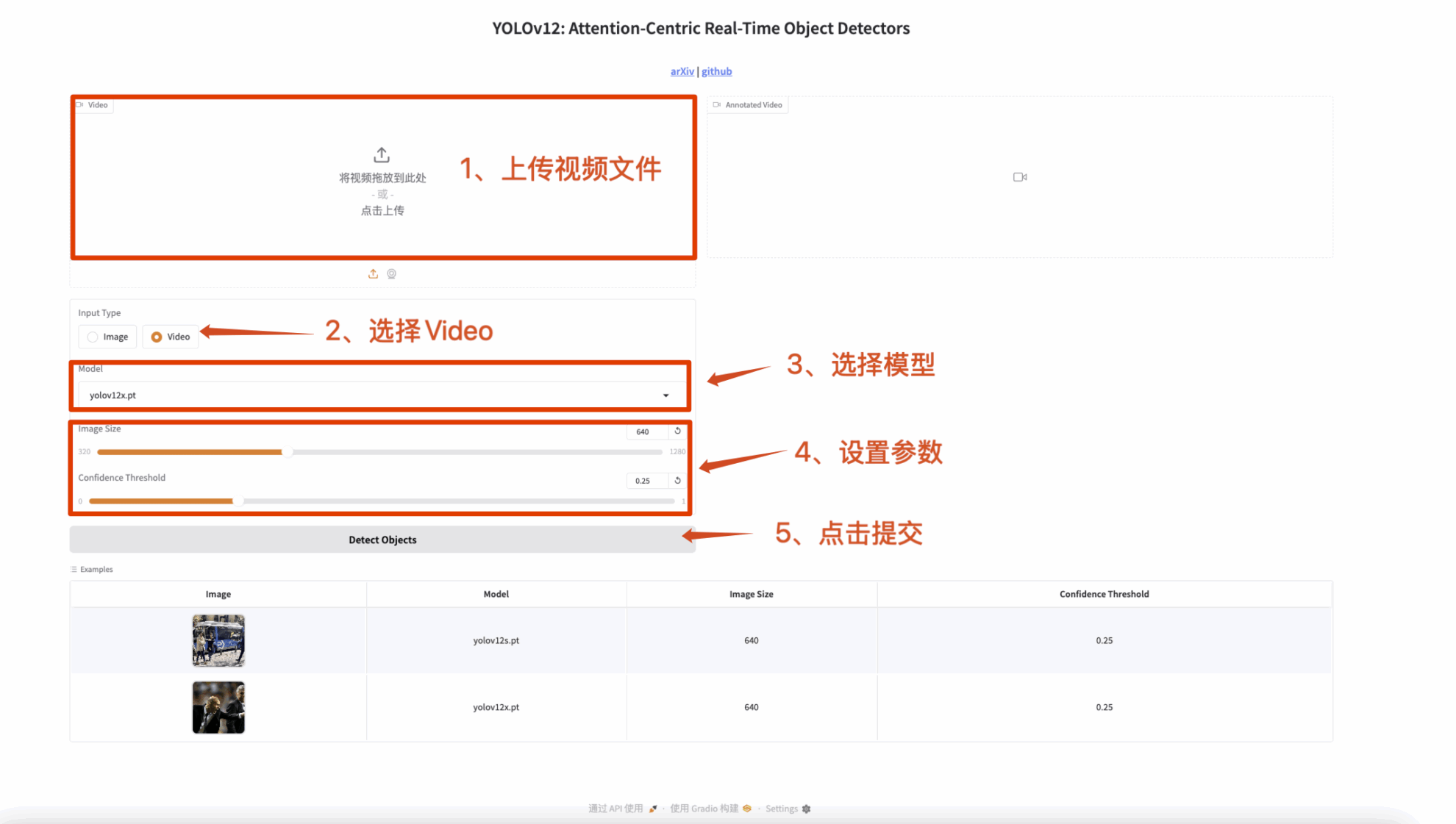
Figure 2 Video detection
🤝 Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

YOLOv12 is not only a technological leap, but also a revolution in the field of computer vision! Come and experience it! 🚀
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.