Command Palette
Search for a command to run...
Qwen3-ASR Technical Report
Qwen3-ASR Technical Report
Abstract
In this report, we introduce Qwen3-ASR family, which includes two powerful all-in-one speech recognition models and a novel non-autoregressive speech forced alignment model. Qwen3-ASR-1.7B and Qwen3-ASR-0.6B are ASR models that support language identification and ASR for 52 languages and dialects. Both of them leverage large-scale speech training data and the strong audio understanding ability of their foundation model Qwen3-Omni. We conduct comprehensive internal evaluation besides the open sourced benchmarks as ASR models might differ little on open-sourced benchmark scores but exhibit significant quality differences in real-world scenarios. The experiments reveal that the 1.7B version achieves state-of-the-art performance among open-sourced ASR models and is competitive with the strongest proprietary APIs while the 0.6B version offers the best accuracy–efficiency trade-off. Qwen3-ASR 0.6B can achieve an average time-to-first-token as low as 92ms and transcribe 2,000 seconds speech in 1 second at a concurrency of 128. Qwen3-ForcedAligner-0.6B is an LLM based NAR timestamp predictor that is able to align text-speech pairs in 11 languages. Timestamp accuracy experiments show that the proposed model outperforms the three strongest force alignment models and takes more advantages in efficiency and versatility. To further accelerate the community research of ASR and audio understanding, we release these models under the Apache 2.0 license.
One-sentence Summary
Qwen Team introduces the Qwen3-ASR family—comprising the 1.7B and 0.6B ASR models, which leverage Qwen3-Omni’s audio understanding to support 52 languages and dialects, and the 0.6B non-autoregressive Qwen3-ForcedAligner for 11-language speech-text alignment—demonstrating state-of-the-art open-source ASR performance, competitive accuracy against proprietary APIs, superior efficiency with 92ms time-to-first-token and 2,000 seconds speech transcribed per second at 128 concurrency, and outperforming prior forced alignment models in timestamp accuracy, efficiency, and versatility.
Key Contributions
-
Qwen3-ASR-1.7B and Qwen3-ASR-0.6B achieve state-of-the-art performance among open-source ASR models across 52 languages and dialects, leveraging Qwen3-Omni’s audio understanding to outperform proprietary APIs in real-world conditions including noisy and singing speech, with the 0.6B variant delivering sub-100ms latency and high throughput at 128 concurrency.
-
Qwen3-ForcedAligner-0.6B is the first LLM-based non-autoregressive forced aligner supporting 11 languages, surpassing MFA and NFA in timestamp accuracy and efficiency, with end-to-end processing under five minutes per sample and flexible alignment at word, sentence, and paragraph levels.
-
The Qwen3-ASR family is fully open-sourced with a unified, user-friendly framework supporting streaming transcription, multilingual processing, and reproducible fine-tuning, providing an all-in-one solution that fills a critical gap in scalable speech labeling and real-world deployment tooling.
Introduction
The authors leverage the audio understanding capabilities of Qwen3-Omni to build Qwen3-ASR, a family of open-source speech recognition models that support multilingual ASR and language identification across 52 languages and dialects, while also introducing a novel non-autoregressive forced aligner for timestamp prediction. Prior ASR systems often struggle with real-world variability—such as noise, singing, or dialects—and rely on separate, language-specific tools for timestamping, which limits scalability and efficiency. The Qwen3-ASR family addresses these gaps by delivering state-of-the-art accuracy on real-world internal benchmarks, offering efficient inference (e.g., 92ms time-to-first-token), and providing the first lightweight, multilingual LLM-based forced aligner that supports flexible granularities and outperforms existing tools in both speed and accuracy. All models are released under Apache 2.0 with a unified inference and fine-tuning framework to accelerate community research.
Dataset
The authors use a multi-source dataset for training Qwen3-ASR, combining public and proprietary speech data. Key details:
-
Composition and sources:
- Includes public datasets like LibriSpeech, CommonVoice, and AISHELL-3.
- Augmented with large-scale internal speech corpora from Alibaba’s ecosystem.
- Covers diverse accents, domains, and speaking styles to improve generalization.
-
Subset details:
- LibriSpeech: 960 hours of clean read speech, filtered for high transcription accuracy.
- CommonVoice: ~1,000 hours across 100+ languages, with strict quality and alignment thresholds.
- AISHELL-3: 85 hours of Mandarin multi-speaker data, cleaned for speaker consistency.
- Internal data: Over 50,000 hours of noisy, real-world speech, filtered using ASR confidence scores and audio quality metrics.
-
Usage in training:
- Data split: 90% training, 5% validation, 5% test — stratified by speaker and domain.
- Mixture ratios: Public data weighted at 30%, internal data at 70% to prioritize real-world robustness.
- Processing: All audio resampled to 16 kHz, segmented into 30-second chunks with 50% overlap; silence removed via VAD.
-
Additional processing:
- Cropping strategy: Random 10–30 second segments during training to simulate variable utterance lengths.
- Metadata: Each sample tagged with speaker ID, language, domain, and SNR estimate for curriculum learning.
- Augmentation: SpecAugment applied during training with time masking, frequency masking, and speed perturbation.
Method
The authors leverage a modular architecture for the Qwen3-ASR family, built upon the Qwen3-Omni foundation model, to achieve robust, multilingual, and streaming-capable speech recognition. The core audio processing is handled by the AuT encoder, a separately pretrained attention-encoder-decoder (AED) model that downsamples 100Hz Fbank features by a factor of 8, yielding a 12.5Hz token rate representation. This encoder supports dynamic flash attention windows ranging from 1s to 8s, enabling flexible deployment in both streaming and offline scenarios. The architecture integrates this encoder with a Qwen3 LLM via a projector, forming a unified multimodal pipeline. For instance, Qwen3-ASR-1.7B combines Qwen3-1.7B with a 300M-parameter AuT encoder, while Qwen3-ASR-0.6B uses a more compact 180M-parameter encoder to balance efficiency and accuracy.
As shown in the figure below, the overall framework illustrates the integration of the pretrained AuT encoder with the Qwen3 LLM, where speech is first encoded into a sequence of hidden states, then projected and fed into the language model for transcription. The decoder side of the AuT model, shown on the left, operates under the AED paradigm with cross-attention and self-attention layers, while the right side depicts the end-to-end Qwen3-ASR structure where the LLM directly generates text conditioned on the audio embeddings.
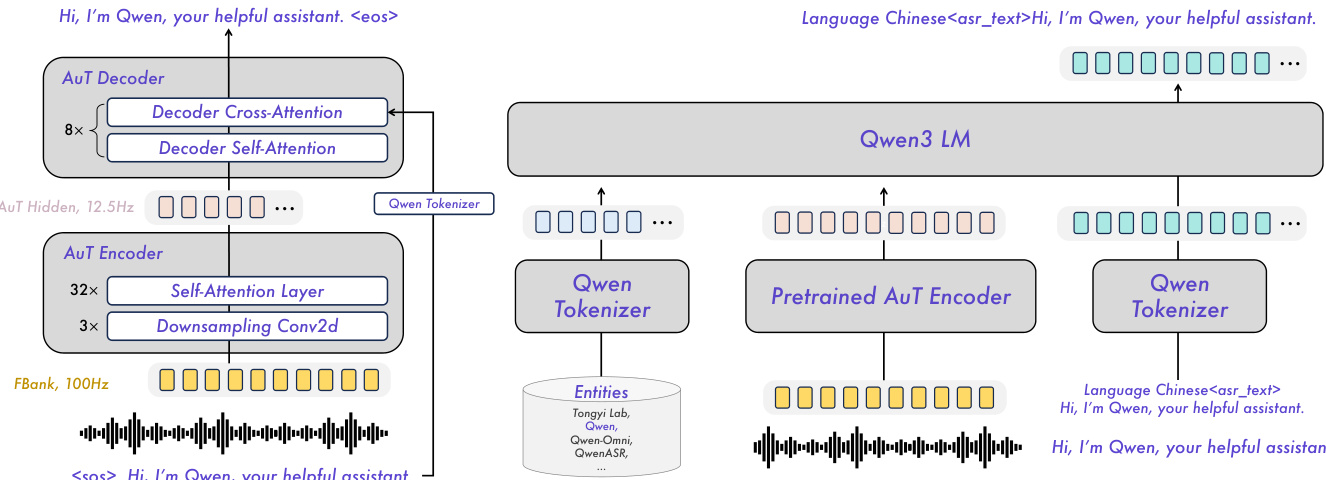
Training proceeds in four stages: AuT pretraining, Omni pretraining, ASR supervised finetuning (SFT), and ASR reinforcement learning (RL). The AuT encoder is pretrained on approximately 40 million hours of pseudo-labeled ASR data, primarily in Chinese and English, to learn stable audio representations under variable attention windows. Omni pretraining then aligns the Qwen3-Omni model with multi-modal data, training both Qwen3-ASR variants on 3 trillion tokens to acquire cross-modal understanding. During SFT, the model is fine-tuned on a smaller, disjoint multilingual dataset with specialized data types—including non-speech, streaming-enhancement, and context biasing data—to enforce ASR-only behavior and mitigate instruction-following failures. The model is trained to output transcriptions with or without human speech, and to utilize context tokens in the system prompt for customized results. Finally, RL via Group Sequence Policy Optimization (GSPO) refines transcription quality using 50k utterances, enhancing noise robustness and stability in complex acoustic environments.
For forced alignment, Qwen3-ForcedAligner-0.6B reframes the task as slot filling: given a transcript augmented with [time] tokens marking word or character boundaries, the model predicts discrete timestamp indices for each slot. The architecture, as illustrated in the figure below, uses the same pretrained AuT encoder to extract speech embeddings, while the transcript is tokenized with [time] placeholders. These are discretized into indices based on the 80ms frame duration of the encoder output. The combined sequence is processed by the Qwen3-0.6B LLM, followed by a linear timestamp prediction layer that outputs indices for all slots simultaneously, supporting up to 300s of audio (3,750 classes).
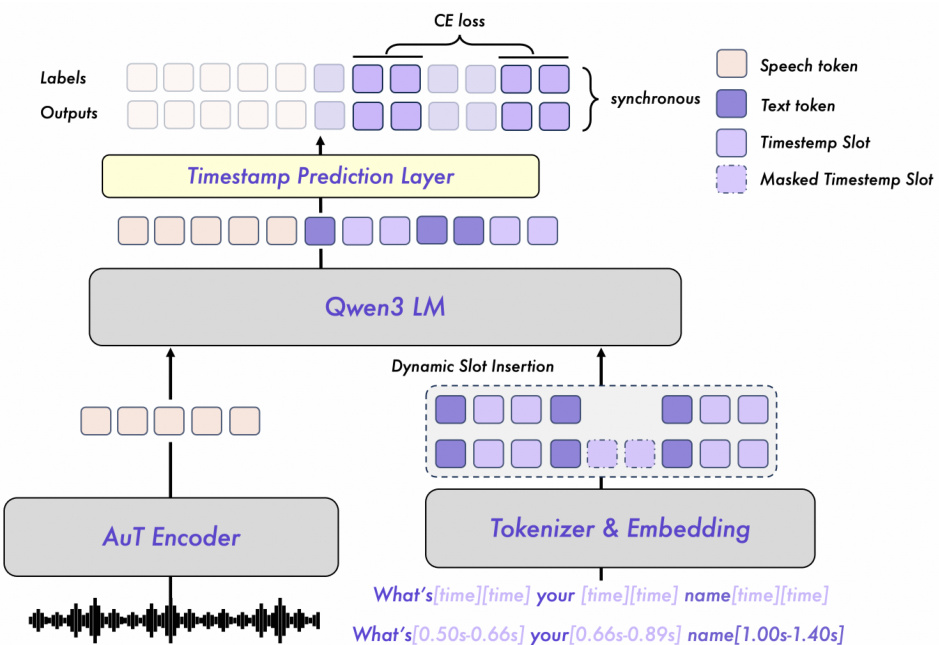
Training employs pseudo-labels generated by the Montreal Forced Aligner (MFA), which are distilled and smoothed to reduce systematic shifts. Unlike standard next-token prediction, the model uses causal training: output and label sequences remain non-shifted, allowing the model to explicitly recognize timestamp slots and leverage prior context for globally consistent predictions. Cross-entropy loss is applied only at timestamp slots, focusing optimization on slot filling. A dynamic slot insertion strategy randomly inserts start/end slots during training to improve generalization. At inference, users can insert [time] tokens after any word or character, and the model performs non-autoregressive decoding to predict all timestamp indices simultaneously, which are then converted to actual timestamps by multiplying by 80ms.
Experiment
The Qwen3-ASR family, evaluated across public and internal benchmarks, demonstrates state-of-the-art performance in multilingual and multi-dialect ASR, particularly excelling in Mandarin Chinese and 22 Chinese dialects, with robustness to accents, noise, and singing voice recognition—even under background music. On English benchmarks, it outperforms open-source models and matches or exceeds commercial APIs, especially in real-world, non-curated speech. The 1.7B variant consistently surpasses the 0.6B model, achieving up to 2000x real-time throughput at 128 concurrency and maintaining strong streaming accuracy. Qwen3-ForcedAligner-0.6B further delivers precise, cross-lingual timestamps with low AAS, outperforming language-specific baselines on both short and long utterances.
The authors evaluate Qwen3-ASR-1.7B on singing voice and full-song transcription with background music, comparing it against commercial and open-source baselines. Results show Qwen3-ASR-1.7B achieves the lowest word error rates on most singing benchmarks and outperforms all open-source models on long-form songs with music, while remaining competitive with top commercial systems. Qwen3-ASR-1.7B achieves best WER on M4Singer, MIR-1k-vocal, and Popcs singing benchmarks. It outperforms open-source models on full songs with background music, including English and Chinese sets. Commercial systems show variable performance, while Qwen3-ASR-1.7B maintains consistent accuracy across song types.

The authors evaluate Qwen3-ASR models across multiple multilingual benchmarks including MLS, CommonVoice, and MLC-SLM. Results show that Qwen3-ASR-1.7B consistently outperforms the smaller Qwen3-ASR-0.6B, and both models generally surpass Qwen3-ASR-Flash-128 in accuracy across most languages. The performance gap is especially notable in low-resource or challenging language subsets. Qwen3-ASR-1.7B achieves the lowest error rates across most languages in MLS and CommonVoice. Qwen3-ASR-0.6B outperforms Qwen3-ASR-Flash-128 in nearly all evaluated languages. Larger model size correlates with improved multilingual robustness, especially in MLC-SLM.

The authors evaluate Qwen3-ASR models in both offline and streaming modes across multiple benchmarks. Results show that streaming inference maintains strong accuracy, with only modest increases in error rates compared to offline mode. The larger 1.7B model consistently outperforms the 0.6B variant in both inference modes. Streaming mode incurs small accuracy drops versus offline across all benchmarks Qwen3-ASR-1.7B outperforms Qwen3-ASR-0.6B in both inference modes Models maintain strong performance on both English and Chinese benchmarks under streaming

The authors evaluate Qwen3-ForcedAligner-0.6B against competing forced-alignment methods using Accumulated Average Shift (AAS) on MFA-labeled and human-labeled test sets. Results show Qwen3-ForcedAligner-0.6B consistently achieves lower AAS values across languages and utterance lengths, indicating more accurate timestamp predictions. It also generalizes well to human-labeled data despite being trained on MFA pseudo-labels. Qwen3-ForcedAligner-0.6B outperforms baselines on both short and long utterances. It maintains low AAS on human-labeled test sets, showing strong real-world generalization. The model supports multiple languages and cross-lingual scenarios with a single model.

The authors evaluate Qwen3-ASR models on the Fleurs multilingual benchmark, reporting word error rates across 30 languages. Results show that Qwen3-ASR-1.7B consistently outperforms the smaller Qwen3-ASR-0.6B variant, and both models achieve lower error rates than the Qwen3-ASR-Flash-1208 baseline across most languages. The 1.7B model delivers the strongest overall performance, particularly on languages like Arabic, Czech, and Hindi. Qwen3-ASR-1.7B achieves the lowest WER in most languages compared to smaller variants Performance improves with model scale, with 1.7B consistently outperforming 0.6B Qwen3-ASR-Flash-1208 shows higher error rates than both main models across nearly all languages

Qwen3-ASR-1.7B excels in singing voice and full-song transcription with background music, achieving the lowest WER on M4Singer, MIR-1k-vocal, and Popcs benchmarks and outperforming all open-source models while remaining competitive with commercial systems. Across multilingual benchmarks including MLS, CommonVoice, MLC-SLM, and Fleurs, the 1.7B model consistently surpasses smaller variants and the Flash baseline, especially in low-resource languages, with performance scaling positively with model size. In streaming mode, Qwen3-ASR models maintain strong accuracy with only minor degradation versus offline inference, and the 1.7B variant outperforms 0.6B across both modes and languages. Qwen3-ForcedAligner-0.6B delivers superior timestamp accuracy across languages and utterance lengths, generalizing well to human-labeled data despite training on pseudo-labels, and supports cross-lingual alignment with a single model.