Command Palette
Search for a command to run...
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
Abstract
Recent progress in reasoning models has substantially advanced long-horizon mathematical and scientific problem solving, with several systems now reaching gold-medal-level performance on International Mathematical Olympiad (IMO) and International Physics Olympiad (IPhO) problems. In this paper, we introduce a simple and unified recipe for converting a post-trained reasoning backbone into a rigorous olympiad-level solver. The recipe first uses a reverse-perplexity curriculum for SFT to instill rigorous proof-search and self-checking behaviors, then scales these behaviors through a two-stage RL pipeline that progresses from RL with verifiable rewards to more delicate proof-level RL, and finally boosts solving performance with test-time scaling. Applying this recipe, we train a 30B-A3B backbone with SFT on around 340K sub-8K-token trajectories followed by 200 RL steps. The resulting model, SU-01, supports stable reasoning on difficult problems with trajectories exceeding 100K tokens, while achieving gold-medal-level performance on mathematical and physical olympiad competitions, including IMO 2025/USAMO 2026 and IPhO 2024/2025. It also demonstrates strong generalization of scientific reasoning to domains beyond mathematics and physics.
One-sentence Summary
The authors introduce SU-01, a 30B-A3B reasoning model trained via a unified scaling recipe that combines reverse-perplexity supervised fine-tuning, a two-stage reinforcement learning pipeline, and test-time scaling to instill rigorous proof-search and self-checking behaviors, ultimately achieving gold-medal-level performance on International Mathematical and Physics Olympiads while demonstrating strong generalization to domains beyond mathematics and physics.
Key Contributions
- Introduces a unified training recipe that converts a post-trained reasoning backbone into an olympiad-level solver by applying a reverse-perplexity curriculum for supervised fine-tuning and a two-stage reinforcement learning pipeline that scales capabilities from verifiable rewards to proof-level optimization.
- Presents SU-01, a 30B-A3B model trained on approximately 340K sub-8K-token trajectories with 200 reinforcement learning steps, which sustains stable reasoning on complex problems with trajectories exceeding 100K tokens.
- Achieves gold-medal-level performance on mathematical and physical competitions including IMO 2025, USAMO 2026, and IPhO 2024/2025 while demonstrating strong scientific reasoning generalization to domains beyond mathematics and physics.
Introduction
The authors tackle the demand for rigorous, gold-medal-level reasoning on International Mathematical and Physics Olympiad problems, where models must generate complete proofs and maintain coherence over extremely long horizons. Prior approaches often depend on complex neuro-symbolic systems, massive model scales, or disjointed training strategies that limit accessibility and generalization. The authors leverage a streamlined and unified post-training recipe to convert a compact 30B-A3B backbone into SU-01, achieving gold-medal performance through a sequence of targeted interventions. This method employs a reverse-perplexity curriculum during supervised fine-tuning to instill proof-search and self-checking behaviors, followed by a two-stage reinforcement learning pipeline that advances from coarse verifiable rewards to refined proof-level rewards, and concludes with test-time scaling via self-verification. The resulting model sustains stable reasoning trajectories beyond 100K tokens and exhibits strong transfer capabilities to scientific domains outside its primary training distribution.
Dataset
-
Dataset composition and sources: The authors curate a broad mixture of mathematical, scientific, coding, and instruction-following data. Mathematical prompts originate from Evan Chen’s olympiad materials, the Shuzhimi Forum, Art of Problem Solving, online competition training books, and DeepMath problems rated at least level six. Scientific reasoning draws from NaturalReasoning, while instruction-following and coding data come from Nemotron-Instruction-Following-Chat-v1, Eurus-2-RL-Data, and OpenCodeReasoning-2. The reinforcement learning pool additionally incorporates OPC, a human-evaluated corpus of advanced mathematical proofs.
-
Key details for each subset: The supervised fine-tuning dataset contains 338,000 filtered trajectories organized into a direct-generation group (math, STEM, code, and instruction-following) and a self-improvement group (self-verification and self-refinement). For the mathematical subset, the authors generate additional verification and refinement traces to teach the model how to validate proofs and fix logical flaws. The reinforcement learning dataset comprises 25,254 prompts split into 8,967 verifiable examples and 16,287 non-verifiable examples tailored for proof-oriented or open-ended reasoning.
-
How the paper uses the data: The authors train the supervised fine-tuning model on both direct solutions and self-correction behaviors to build rigorous reasoning capabilities. The reinforcement learning pool is divided into verifiable and non-verifiable splits to guide distinct optimization objectives. The verifiable set supports answer-checkable optimization, while the non-verifiable set trains the model using softer judgment signals like generative rewards for complex proofs.
-
Processing and cropping strategy: Before training, the team removes contaminated problems from both pools and deduplicates the remaining prompts. They use DeepSeek-V3.2-Speciale to generate reasoning trajectories for the SFT data, then discard noisy outputs. To keep the supervised signal focused and prevent training instability, the authors crop or remove any trajectory exceeding 8,192 tokens. For the reinforcement learning pool, they apply rejection sampling to filter out examples that are too easy or too difficult for the current policy, and they remove poorly formatted or unreliable prompts.
Method
The SU-01 model employs a modular training pipeline designed to transform a broadly capable post-trained language model into a high-performing system for rigorous mathematical and scientific reasoning. The overall framework proceeds through four distinct stages: Supervised Fine-Tuning (SFT), Coarse Reinforcement Learning (RL), Refined Reinforcement Learning (RL), and Test-Time Scaling (TTS). Each stage addresses a specific aspect of reasoning capability, building upon the previous one to achieve expert-level performance on olympiad-level problems.
The first stage, SFT, aims to instill a disciplined proof-search pattern in the model. It starts from a post-trained model, P1-30B-A3B, which already exhibits strong scientific reasoning but lacks a structured approach to long-form proofs. The SFT process uses a mixture of long-form solutions, self-verification, and self-refinement trajectories from diverse sources, including mathematics, science, coding, and instruction-following. The training data is ordered by reverse perplexity, meaning examples that are most mismatched with the initial model's policy are presented first. This curriculum helps the model adapt to the new reasoning style while preserving its existing capabilities, preventing the degradation often seen in long-CoT training.
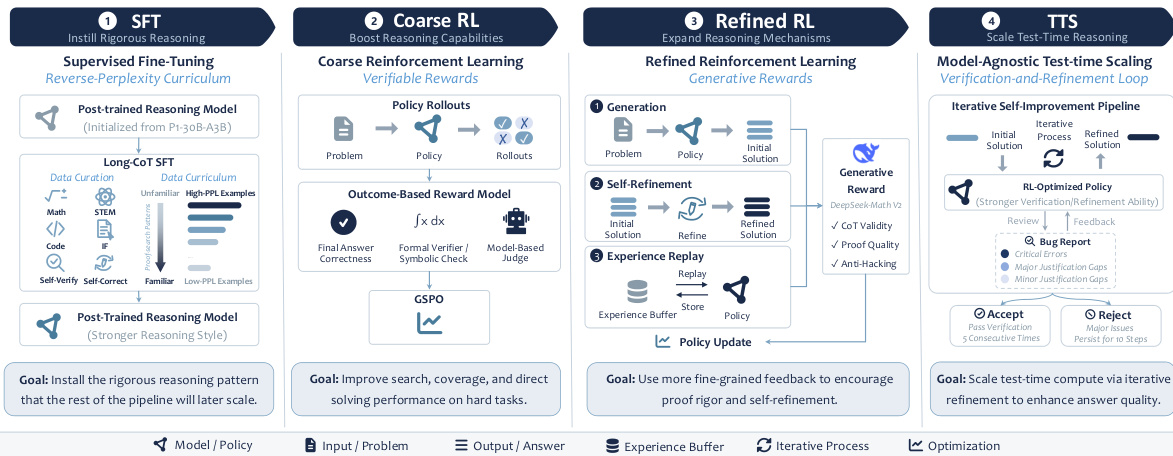
The second stage, Coarse RL, scales the model's reasoning behavior by improving its ability to find correct answers on hard problems. This stage uses verifiable prompts and efficient outcome checking to provide reliable binary rewards, following the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm. The policy is updated using Group Sequence Policy Optimization (GSPO), which operates at the complete-response level, making it well-suited for outcome-reward training. The reward system is layered: it first applies canonicalized text matching, then a rule-based mathematical expression evaluator (Math-Verify), and finally a generative model (gpt-oss-120b) for unresolved cases, ensuring a conservative and high-precision reward signal.
The third stage, Refined RL, specializes the policy towards producing complete, auditable proofs. It shifts the optimization target from mere answer correctness to proof quality. This is achieved by using a generative reward model (DeepSeekMath-V2) that scores the full reasoning path. To encourage self-refinement, the pipeline includes a self-refinement mechanism where failed solutions are converted into prompts to critique and repair the argument. Additionally, an experience replay buffer stores rare successful proof trajectories, ensuring the policy can learn from high-value examples even when they are infrequent. The replay mechanism is targeted, using a controlled ratio and selecting the lowest-entropy trajectory to ensure stability and safety.
The final stage, TTS, leverages test-time compute to elevate the model's performance. It applies a self-verification and refinement loop, where the model generates an initial solution, checks it for logical errors and gaps, and iteratively refines it based on a structured bug report. This process allows the model to sustain coherent reasoning over long trajectories (beyond 100K tokens) and effectively allocate additional inference compute to the most challenging problems, scaling its solving capability beyond what is achievable in a single pass.
Experiment
The evaluation framework assesses the model across answer-verifiable tasks, non-verifiable proof-oriented challenges, and official olympiad competitions to validate whether the training pipeline successfully shifts reasoning from superficial answer recovery to rigorous, self-correcting proof construction. These experiments demonstrate that staged post-training progressively builds proof reliability and enables robust cross-domain STEM transfer despite being trained exclusively on mathematics and physics signals. Qualitative analysis further reveals that test-time scaling effectively allocates inference compute toward verification and iterative refinement, allowing the model to repair complex arguments and achieve top-tier competition performance. Ultimately, the results confirm that a streamlined, unified training recipe can elicit human-level olympiad reasoning from a compact architecture without relying on massive compute or multi-domain supervision.
The authors present an analysis of a model's reasoning progression across different training stages, focusing on its ability to generate rigorous proofs and recover correct answers. The model shows significant improvement in handling non-verifiable proof tasks, particularly on advanced problems, as training progresses. Results indicate that the model's performance on complex reasoning tasks benefits from both self-verification and refinement mechanisms, with gains concentrated on harder problems that require full proof construction. The model's ability to generate rigorous proofs improves substantially on advanced non-verifiable tasks during training. Self-verification and refinement mechanisms are particularly effective in enhancing performance on complex proof-oriented problems. The model demonstrates strong transfer to untrained domains, indicating general scientific reasoning capabilities beyond its training signals.

The authors analyze the progression of model performance across training stages, showing improvements in both verifiable and non-verifiable reasoning tasks. The model demonstrates strong gains in proof-oriented benchmarks, particularly on advanced problems, as the training shifts from initial supervised fine-tuning to reinforcement learning with refined rewards and test-time scaling. These results indicate that the training recipe enhances rigorous reasoning and self-correction capabilities, with the final model achieving top-level performance on competition-style problems. The model's performance on non-verifiable proof tasks improves significantly with each training stage, especially on advanced problems. Test-time scaling substantially boosts the model's ability to produce correct proofs, particularly on basic and advanced proof benchmarks. The training pipeline effectively transitions the model from answer recovery to rigorous proof construction and self-refinement.
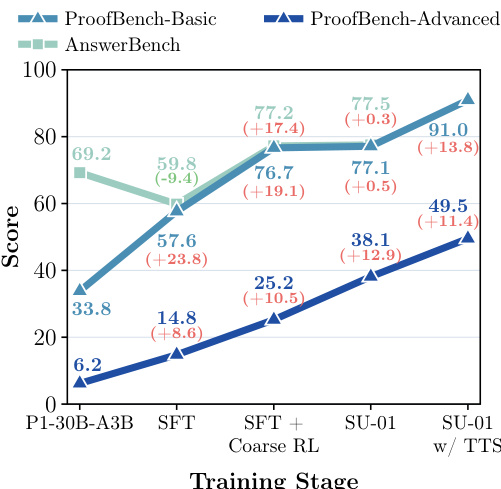
The authors evaluate the model's performance on non-verifiable reasoning tasks, particularly focusing on proof-oriented benchmarks. Results show that the model achieves strong results on proof-based evaluations, with significant improvements after test-time scaling. The model's performance is competitive among similar-sized models, and its reasoning behavior demonstrates transferability across domains despite training primarily on mathematical and physical signals. The model achieves strong performance on non-verifiable proof benchmarks, with test-time scaling significantly improving its results. The model shows transferable reasoning capabilities to untrained scientific domains, including chemistry and biology, despite training only on math and physics. The model's reasoning behavior improves through staged training, with refinement and self-verification playing a key role in enhancing proof quality.
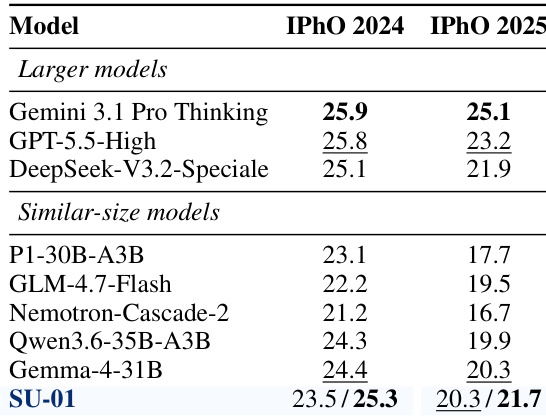
The authors evaluate the performance of SU-01 on physics olympiad problems, comparing it against larger and similar-sized models. Results show that SU-01 achieves strong scores on both IPhO 2024 and 2025, surpassing gold medal thresholds in both years, and outperforms other models of similar size. The model's performance improves significantly with test-time scaling, indicating effective self-refinement capabilities. SU-01 exceeds gold medal thresholds on both IPhO 2024 and 2025, demonstrating strong olympiad-level reasoning. SU-01 outperforms other models of similar size on both IPhO 2024 and 2025, highlighting its efficiency and capability. Test-time scaling significantly boosts SU-01's performance, indicating robust self-refinement behavior.
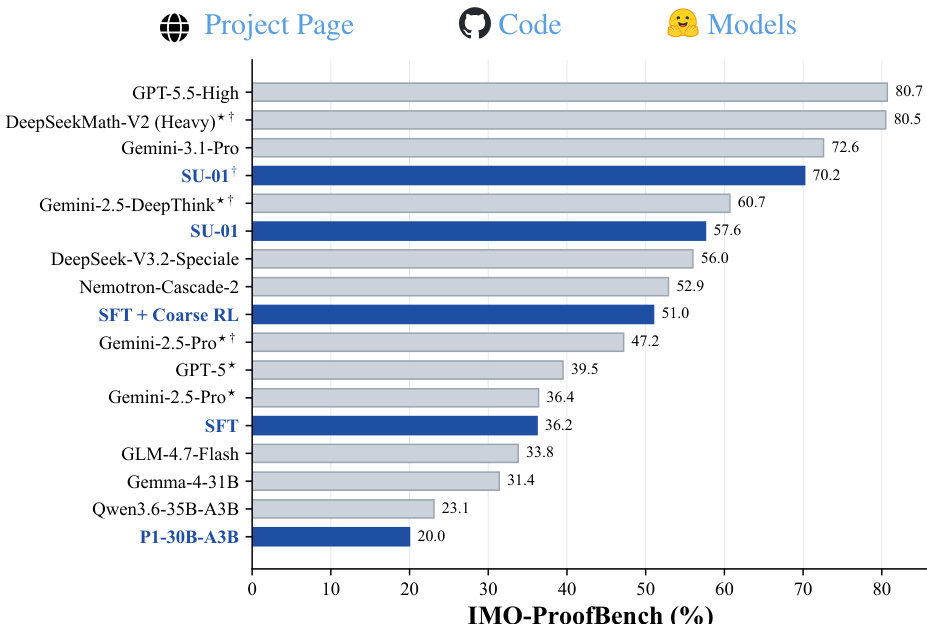
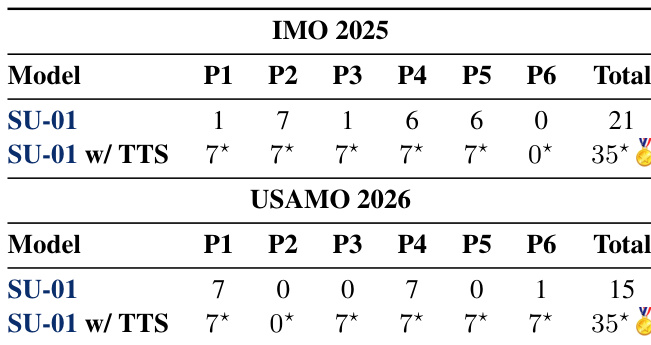
The authors present experimental results on mathematical olympiad problems, showing that their model achieves top-level performance on both IMO 2025 and USAMO 2026, reaching the gold medal threshold in both competitions. The results demonstrate that test-time scaling significantly improves performance, enabling the model to solve difficult problems that it cannot resolve in a single pass. The model shows strong reasoning ability, particularly in translating problems into formal frameworks, but still exhibits failure modes on certain complex problems. The model achieves gold-medal-level scores on both IMO 2025 and USAMO 2026, meeting or exceeding the official gold medal thresholds. Test-time scaling enables the model to solve problems it fails to solve in a single pass, significantly improving its overall performance. The model demonstrates strong reasoning capabilities, especially in formalizing problems using mathematical frameworks, but still has limitations on certain complex problem types.
The experiments evaluate the model across staged training phases and diverse benchmarks, including mathematical and physics olympiad problems, non-verifiable proof tasks, and untrained scientific domains. These evaluations validate that a progressive training pipeline combined with test-time scaling and self-refinement mechanisms substantially enhances rigorous proof construction and self-correction capabilities. The model consistently achieves gold-medal-level performance on major competitions and demonstrates strong cross-domain transfer, though it still encounters limitations on certain highly complex reasoning tasks.