Command Palette
Search for a command to run...
World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
Abstract
Recent video foundation models demonstrate impressive visual synthesis but frequently suffer from geometric inconsistencies. While existing methods attempt to inject 3D priors via architectural modifications, they often incur high computational costs and limit scalability. We propose World-R1, a framework that aligns video generation with 3D constraints through reinforcement learning. To facilitate this alignment, we introduce a specialized pure text dataset tailored for world simulation. Utilizing Flow-GRPO, we optimize the model using feedback from pre-trained 3D foundation models and vision-language models to enforce structural coherence without altering the underlying architecture. We further employ a periodic decoupled training strategy to balance rigid geometric consistency with dynamic scene fluidity. Extensive evaluations reveal that our approach significantly enhances 3D consistency while preserving the original visual quality of the foundation model, effectively bridging the gap between video generation and scalable world simulation.
One-sentence Summary
World-R1 is a reinforcement learning framework that aligns text-to-video generation with 3D constraints by optimizing a specialized pure-text dataset through Flow-GRPO, leveraging feedback from pre-trained 3D foundation and vision-language models alongside a periodic decoupled training strategy to enforce structural coherence, with extensive evaluations confirming that the method significantly enhances 3D consistency while preserving the foundation model's original visual quality for scalable world simulation.
Key Contributions
- World-R1 introduces a reinforcement learning framework that aligns video generation with 3D constraints without architectural modifications or computationally expensive inference-time constraints. Utilizing Flow-GRPO, the framework optimizes the generator through discriminative feedback, enabling the model to internalize spatial awareness and geometric consistency directly through post-training.
- A specialized pure text dataset featuring multi-class and multi-level camera control is constructed to facilitate post-training alignment. This dataset supports a comprehensive reward system that integrates pre-trained 3D foundation models and vision-language models, while a periodic decoupled training strategy balances rigid geometric consistency with dynamic scene fluidity.
- Extensive evaluations demonstrate that the framework significantly enhances three-dimensional reconstruction consistency while preserving the original visual fidelity of the base foundation model, effectively bridging the gap between video generation and scalable world simulation.
Introduction
Video foundation models are rapidly evolving into world simulators, a capability essential for autonomous systems, robotics, and immersive media. Despite their visual fidelity, these models operate primarily in two dimensions and frequently produce geometric hallucinations or temporal inconsistencies during complex camera movements. Prior attempts to fix this by embedding 3D priors into model architectures or applying inference-time constraints often demand prohibitive computational resources, restrict scalability, and compromise generative diversity. The authors address these challenges with World-R1, a reinforcement learning framework that aligns video generation with 3D geometric laws without altering the underlying architecture. The authors leverage a curated pure text dataset, a dual reward system powered by pre-trained 3D foundation models and vision-language models, and Flow-GRPO optimization to effectively instill spatial coherence and dynamic fluidity while preserving the original model’s high visual quality.
Dataset
Dataset Composition and Sources
- The authors introduce a proprietary "Pure Text Dataset" containing approximately 3,000 unique entries designed to decouple 3D geometric constraint learning from biases inherent in open-domain video distributions.
- The dataset is entirely synthetic and generated using the Gemini-3 model, which leverages advanced instruction-following capabilities to produce high-quality scene descriptions without reliance on noisy text-video alignment.
- The corpus is systematically organized by visual domains and control complexity to cover a wide spectrum of physical properties, ranging from implicit motion to complex composite trajectories.
Subset Details
- Natural Landscapes: Focuses on large-scale rigid geometry and fluid dynamics, subdivided into landforms, water features, and weather variations.
- Urban and Architectural: Emphasizes perspective correctness and vanishing points, covering outdoor environments and indoor spaces such as warehouses, hallways, and lobbies.
- Micro and Still Life: Targets small-scale objects and macro observation to evaluate depth-of-field handling and texture fidelity.
- Fantasy and Surrealism: Introduces non-Euclidean geometries and physics-defying structures to challenge the model's generalization capabilities.
- Artistic Styles: Incorporates stylized renderings like watercolor, cyberpunk illustration, and Van Gogh style to ensure aesthetic diversity is maintained alongside 3D constraints.
- Dynamic Data Subset: A specialized collection focusing on high-entropy scenes and deformable objects, including waterfalls, transforming robots, and breaking glass, to mitigate the suppression of non-rigid dynamics during 3D alignment.
Usage and Processing
- The authors utilize the dataset for training world simulation capabilities, enabling the model to learn physics-compliant generation across varying degrees of difficulty and control complexity.
- A fixed evaluation set of 30 complex prompts is curated separately from the training data to stress-test world modeling performance across diverse scenarios.
- The generation pipeline employs a hierarchical prompt engineering strategy where the LLM acts as an expert cinematographer, enforcing constraints for physical plausibility and logical camera-scene matching.
Metadata and Structure
- Each entry is formatted as JSON output containing four key fields: the descriptive prompt, the selected camera logic, the visual domain category, and the layout type.
- The metadata classifies camera movements into three topological categories: Intra-scene exploration, Inter-scene transition, and Static observation.
- The action space is defined by a comprehensive taxonomy of primitives including push_in, pull_out, orbit, pan, and composite sequences such as pull_left.
Method
The framework of World-R1 integrates a pre-trained video foundation model with reinforcement learning to enhance geometric consistency and world-modeling capabilities without requiring explicit 3D architectures or specialized training data. The overall process begins with a text prompt, which is used to generate a camera trajectory through a prompt-driven motion synthesis mechanism. This trajectory is embedded into the initial noise via a discrete noise transport procedure, effectively conditioning the video generation process on the desired camera motion in an implicit, parameter-free manner. The conditioned noise is then fed into the Video Foundation Model (Wan 2.1), which generates candidate video clips. These clips are processed through a 3D foundation model to reconstruct a 3D Gaussian Splatting (3DGS) representation and estimate the resulting camera trajectory. The generated video is evaluated using a composite reward system that combines a 3D-aware reward and a general quality reward. The 3D-aware reward assesses geometric integrity, rendering fidelity, and trajectory alignment by comparing the reconstructed 3DGS representation and estimated camera motion against the input prompt and generated video. The general reward evaluates visual quality and aesthetic appeal using a precomputed score across the video frames. The total reward is computed by aggregating these components, and the policy is optimized using Flow-GRPO-Fast, a reinforcement learning algorithm that leverages stochastic sampling and a clipped surrogate objective with a KL-divergence constraint to ensure stable and efficient training.
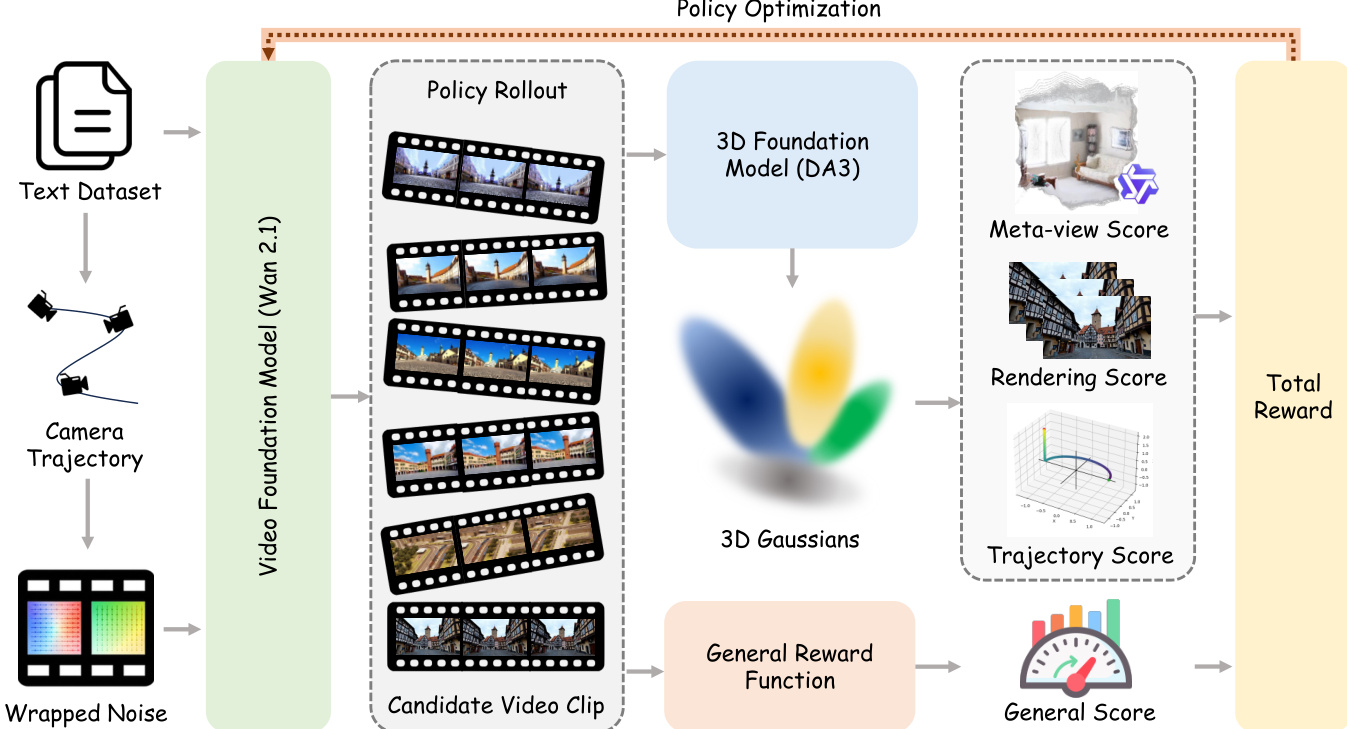
Experiment
The evaluation framework benchmarks World-R1 against leading video foundation models and specialized camera-control methods using reconstruction-based geometric analysis, multi-view consistency scoring, and blind subjective user studies. Comparative and user studies validate that the reinforcement learning alignment strategy significantly enhances three-dimensional consistency and camera trajectory adherence while preserving high aesthetic quality and fluid non-rigid dynamics. Ablation experiments further confirm that specific reward components and dynamic training strategies are essential for balancing strict geometric constraints with natural motion generation. Ultimately, qualitative visualizations and comprehensive analyses demonstrate that the model maintains strict object permanence and structural stability, successfully bridging creative video generation with robust physical reasoning.
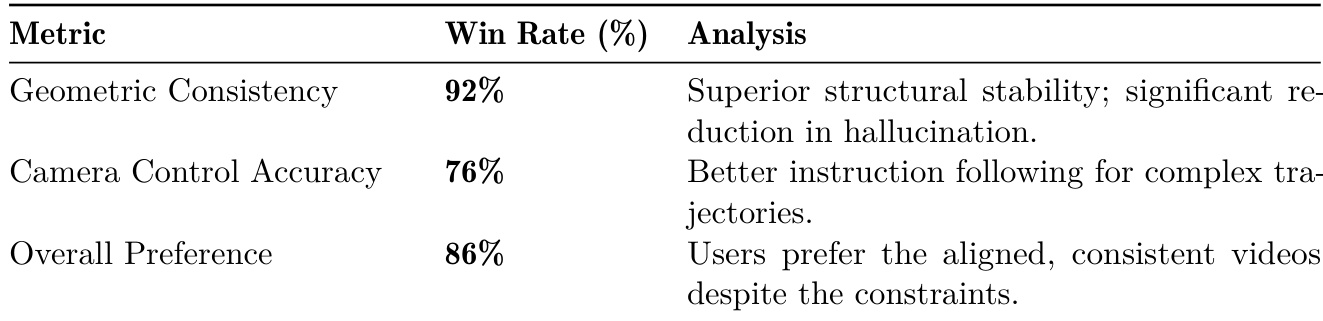
The authors conducted a user study to evaluate the performance of World-R1 against baseline models, focusing on geometric consistency, camera control accuracy, and overall visual quality. Results show that World-R1 significantly outperforms the baseline in maintaining structural stability and following complex camera instructions, while also receiving strong preference from users despite the added constraints. The model demonstrates robustness in preserving 3D consistency and generating high-quality videos, even when subject to strict geometric constraints. World-R1 achieves a 92% win rate in geometric consistency, indicating strong structural stability and reduced hallucinations. The model demonstrates a 76% win rate in camera control accuracy, showing better adherence to complex camera trajectories. Users prefer World-R1 in 86% of cases, highlighting its ability to balance geometric consistency with overall visual quality.
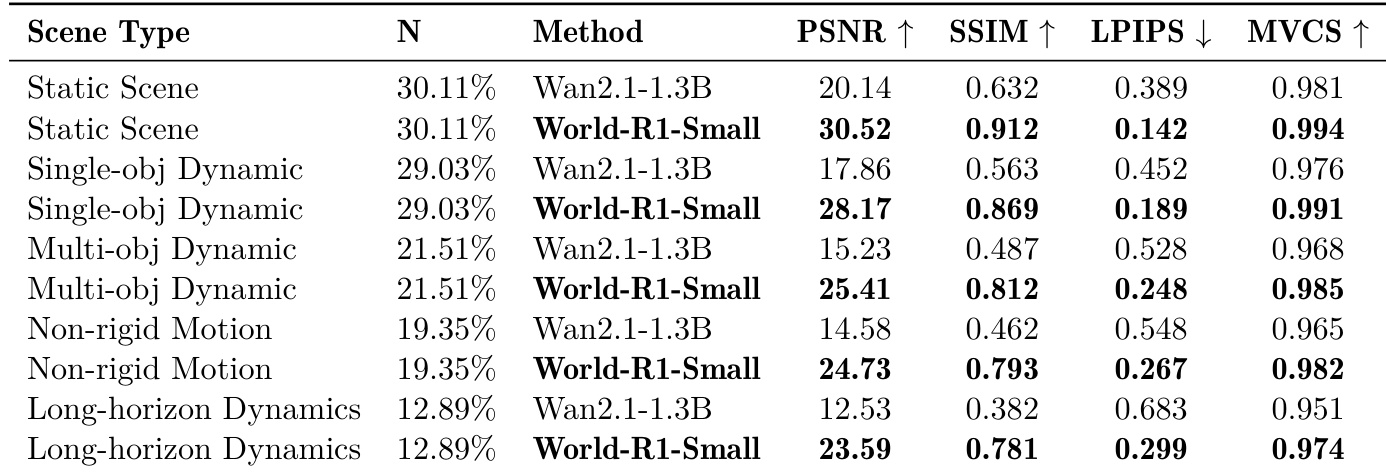
The authors evaluate the performance of World-R1-Small across various scene types, comparing it to a baseline model. Results show that World-R1-Small consistently outperforms the baseline in terms of 3D consistency metrics such as PSNR, SSIM, and MVCS, particularly in complex dynamic scenes. The improvements are most pronounced in non-rigid and long-horizon dynamics, where the model maintains structural integrity while preserving motion fidelity. World-R1-Small achieves higher 3D consistency across all scene types compared to the baseline model. The model demonstrates significant improvements in PSNR and SSIM, especially in non-rigid and long-horizon dynamic scenes. World-R1-Small maintains strong multi-view consistency, indicating robust 3D reconstruction and scene stability.
The authors evaluate the multi-view consistency of their model variants against baseline video generation models using a reconstruction-independent metric. Results show that their proposed models achieve higher multi-view consistency scores, with the larger variant performing the best. This indicates that the models produce videos with stronger cross-view agreement and improved geometric stability. World-R1 models achieve higher multi-view consistency than baseline models. The larger variant of World-R1 shows the highest multi-view consistency score. The results indicate improved geometric stability and cross-view agreement in generated videos.

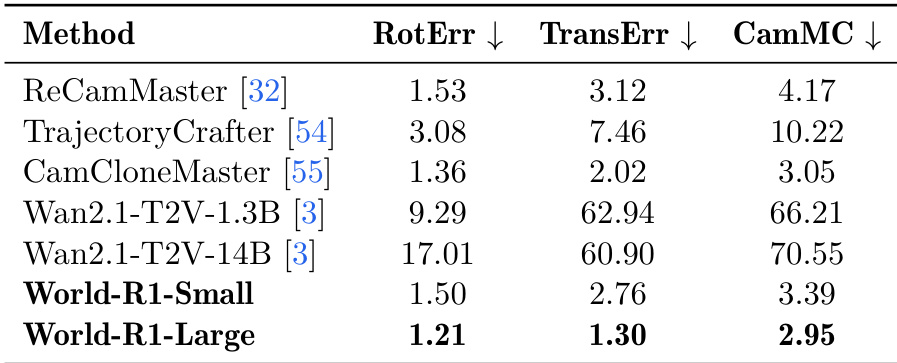
The authors evaluate camera-control accuracy using metrics such as rotation error, translation error, and camera motion consistency, comparing their models against existing methods. World-R1-Large achieves the lowest error values across all metrics, demonstrating superior adherence to specified camera trajectories. World-R1-Small also performs competitively, particularly excelling in translation and camera motion consistency, while the baseline Wan2.1 models show significantly higher errors, indicating weaker control over camera motion. World-R1-Large achieves the best performance in camera-control accuracy, with the lowest rotation, translation, and camera motion consistency errors. World-R1-Small demonstrates strong camera-control performance, particularly in translation and camera motion consistency, outperforming the Wan2.1 baselines. The Wan2.1 models exhibit substantially higher errors, indicating poor alignment with requested camera motions compared to World-R1 and specialized control methods.
The authors evaluate World-R1-Small against several state-of-the-art video generation models, including CogVideoX and Wan2.1, using a comprehensive set of metrics that assess both general video quality and 3D consistency. Results show that World-R1-Small achieves superior performance in aesthetic quality, imaging quality, and subject consistency, outperforming the base model and other control methods. The model demonstrates strong alignment with camera trajectories and maintains geometric coherence, as evidenced by its high scores across multiple evaluation criteria. World-R1-Small surpasses the base model and other control methods in aesthetic quality, imaging quality, and subject consistency. The model achieves high scores in motion smoothness and background consistency, indicating robust camera control and structural stability. World-R1-Small demonstrates strong performance across various metrics, confirming its ability to generate videos with high geometric fidelity and visual quality.
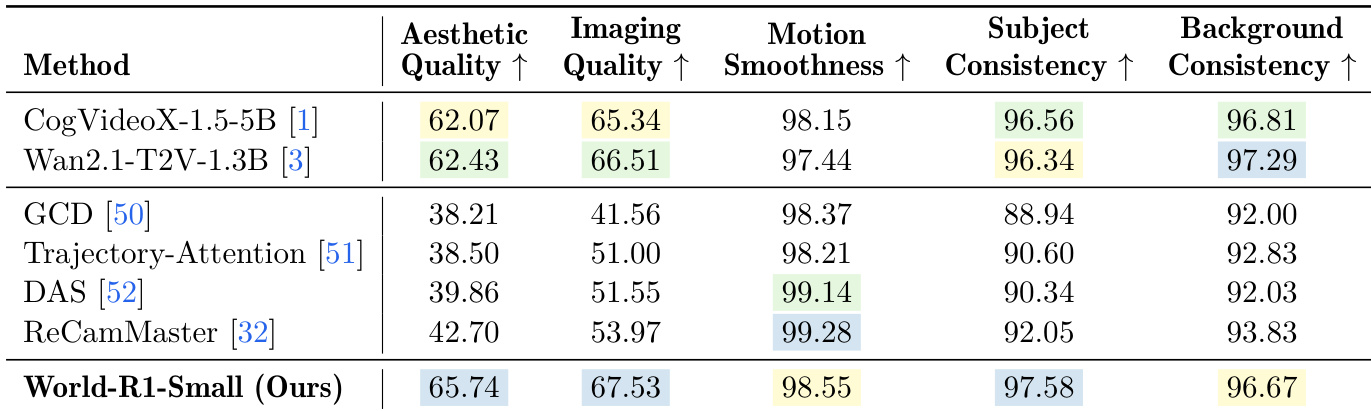
The experiments evaluate World-R1 and its variants against established baselines through user studies, multi-view consistency tests, and camera-control assessments across diverse scene types. These evaluations validate the model's capacity to maintain robust three-dimensional structural integrity, achieve precise adherence to complex camera trajectories, and preserve cross-view geometric stability even in challenging dynamic environments. Qualitative feedback and comprehensive quality assessments consistently demonstrate that the framework significantly outperforms existing methods in visual fidelity, motion smoothness, and overall user preference. Ultimately, the findings confirm that the proposed approach effectively balances strict geometric constraints with high-quality video generation without compromising aesthetic or structural coherence.