Command Palette
Search for a command to run...
AgentSearchBench: A Benchmark for AI Agent Search in the Wild
AgentSearchBench: A Benchmark for AI Agent Search in the Wild
Bin Wu Arastun Mammadli Xiaoyu Zhang Emine Yilmaz
Abstract
The rapid growth of AI agent ecosystems is transforming how complex tasks are delegated and executed, creating a new challenge of identifying suitable agents for a given task. Unlike traditional tools, agent capabilities are often compositional and execution-dependent, making them difficult to assess from textual descriptions alone. However, existing research and benchmarks typically assume well-specified functionalities, controlled candidate pools, or only executable task queries, leaving realistic agent search scenarios insufficiently studied. We introduce AgentSearchBench, a large-scale benchmark for agent search in the wild, built from nearly 10,000 real-world agents across multiple providers. The benchmark formalizes agent search as retrieval and reranking problems under both executable task queries and high-level task descriptions, and evaluates relevance using execution-grounded performance signals. Experiments reveal a consistent gap between semantic similarity and actual agent performance, exposing the limitations of description-based retrieval and reranking methods. We further show that lightweight behavioral signals, including execution-aware probing, can substantially improve ranking quality, highlighting the importance of incorporating execution signals into agent discovery. Our code is available at https://github.com/Bingo-W/AgentSearchBench.
One-sentence Summary
To address the challenges of real-world AI agent discovery, the authors introduce AgentSearchBench, a large-scale benchmark comprising nearly 10,000 agents that formalizes search as a retrieval and reranking problem and evaluates relevance through execution-grounded performance signals rather than mere semantic similarity.
Key Contributions
- The paper introduces AgentSearchBench, a large-scale benchmark containing nearly 10,000 real-world agents from multiple providers to facilitate agent search in open ecosystems. This benchmark formalizes agent search as a retrieval and reranking problem that supports both high-level task descriptions and executable task queries.
- This work establishes a performance-grounded evaluation framework that uses execution outcomes rather than static textual similarity to determine agent relevance. Experiments demonstrate a significant gap between semantic similarity and actual agent performance, showing that description-based retrieval methods often fail to identify the most capable agents.
- The research demonstrates that incorporating lightweight behavioral signals, such as execution-aware probing and richer indexing, substantially improves ranking quality. These findings highlight the necessity of using execution signals to capture the compositional and execution-dependent capabilities of agents.
Introduction
As AI agent ecosystems expand, the ability to reliably identify and select suitable agents for complex tasks becomes critical for both end users and automated orchestration systems. Traditional tool retrieval methods often fail in this context because agent capabilities are compositional and execution-dependent, meaning textual descriptions alone are insufficient to predict actual performance. Prior research typically relies on controlled environments with well-defined interfaces or assumes that relevance can be determined through static semantic similarity. The authors address these limitations by introducing AgentSearchBench, a large-scale benchmark featuring nearly 10,000 real-world agents. They formalize agent search as a retrieval and reranking problem grounded in execution performance rather than mere textual matching, demonstrating that incorporating lightweight behavioral signals can significantly improve the discovery of high-performing agents.
Dataset
-
Dataset Composition and Sources: The authors constructed AgentSearchBench using a repository of nearly 10,000 real-world agents sourced from public platforms such as the GPT Store, Google Cloud Marketplace, and the AgentAI Platform. This collection includes 9,760 agents, of which 7,867 provide executable interfaces.
-
Key Subsets and Details:
- Task Queries: The benchmark contains 2,952 executable task queries, which can be single-agent or multi-agent tasks.
- Task Descriptions: There are 259 high-level task descriptions. Each description is associated with an average of 10 concrete task queries to ensure consistent capability evaluation.
- Multi-agent Queries: These are formed by composing subtasks from capability-aligned clusters. A composition is only retained if it semantically entails all constituent subtasks via natural language inference.
-
Processing and Filtering:
- Query Generation: Task queries are synthesized from agent documentation. To manage evaluation costs, the authors use a hybrid scoring function combining BM25, BGE, and ToolRet to retrieve a top-K candidate set of agents for each query.
- Filtering Rules: The authors filter out degenerate queries where either no agents succeed or all agents succeed.
- Relevance Annotation: Relevance is determined through execution-based evaluation using a 5-point LLM-as-judge. For retrieval tasks, scores are converted into binary labels. For multi-agent and high-level tasks, relevance is calculated as the average completion score across all associated subtasks.
- Misalignment Correction: To account for discrepancies between documentation and actual performance, agents that complete tasks without documented capability receive discounted relevance scores.
-
Data Usage: The authors use the execution results from 66,740 runs (evaluating the top-20 agents per query) to construct golden rankings. This enables the evaluation of agent search through both retrieval and fine-grained reranking tasks.
Method
The authors leverage a multi-stage framework to construct a benchmark for agent search, focusing on task-performance-based relevance and structured agent representation. The process begins with task query generation, where a sample of agents is used to generate initial task queries. These queries are then refined by adding contextual information and filtering out closed-book tasks to produce executable task queries. The framework proceeds to generate task descriptions by abstracting high-level objectives from clusters of semantically related queries, using LLMs to generate concise descriptions for each cluster. To associate executable queries with these descriptions, a rubric-based judge evaluates relevance across multiple aspects, selecting the top-2 queries per aspect to form a pool of candidate queries for each task description.
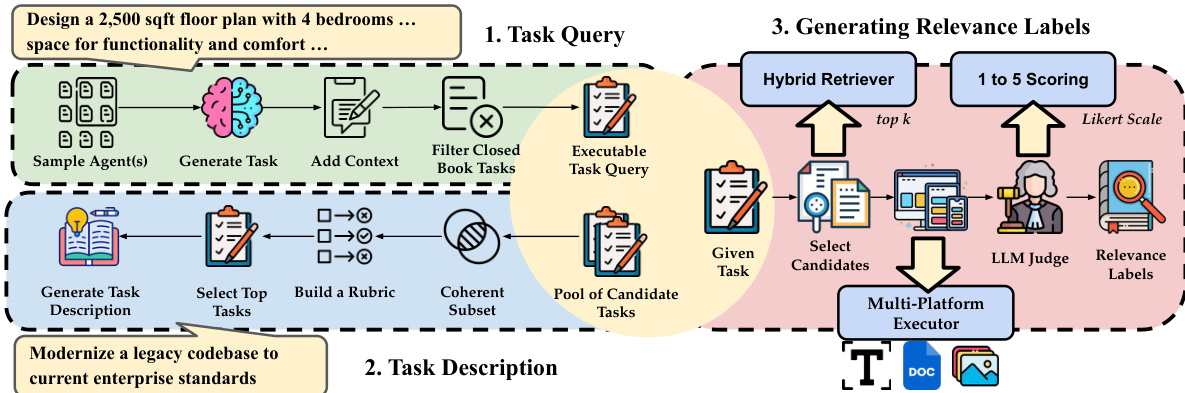
As shown in the figure below: the framework integrates a hybrid retriever that combines lexical, semantic, and tool-aware retrieval signals to select top-k agents for each task query. The retrieval function is defined as s(a,Tq)=αslex+βssem+γstool, where the components are min-max normalized and aggregated with learned weights summing to one. The retrieved agents are then evaluated by an LLM judge using a Likert-scale scoring system (1 to 5) to generate relevance labels, which reflect both task completion performance and documentation-performance alignment. This scoring incorporates the quality of the agent’s response, evaluated via an LLM-as-a-judge mechanism, to compute a task completion score y(a,Tq)=E(a,Tq). For a task description Td, the relevance is aggregated over its associated queries: y(a,Td)=∣Q(Td)∣1∑Tq∈Q(Td)y(a,Tq), ensuring that relevance measures consistent performance across multiple instances. The framework further includes a multi-platform executor to evaluate agents and validate results, ensuring robustness and reliability in the benchmark construction process.
Experiment
The evaluation examines agent retrieval and reranking performance using both executable task queries and high-level task descriptions to identify how well different model families capture agent capabilities. Results indicate that while tool-aware and dense models perform well on concrete queries, there is a significant semantic-performance gap when dealing with abstract descriptions due to a misalignment between documentation and actual execution. The study further demonstrates that incorporating behavioral signals, such as usage examples and execution-based probing, effectively improves ranking accuracy by providing evidence of an agent's true functional competence.
The authors compare different agent search benchmarks, highlighting that AgentSearchBench includes both executable and non-executable task types, while others focus primarily on executable tasks. The evaluation shows that benchmarks vary in the number of candidates and realism, with AgentSearchBench offering a broader scope that includes non-executable task types. AgentSearchBench includes both executable and non-executable task types, unlike other benchmarks that focus on executable tasks only. The number of candidates varies significantly across benchmarks, with AgentSearchBench having a larger candidate pool compared to others. Some benchmarks include realistic task types, while others do not, indicating differences in evaluation realism.

The authors evaluate agent search methods under executable task queries and high-level task descriptions, focusing on retrieval and reranking performance. Results show that tool-aware retrievers outperform others on task queries, while dense retrievers are more competitive on task descriptions, though all methods struggle with completeness, especially under abstract requirements. Reranking methods perform similarly on task queries but show improved performance with decoder-only and LLM-based approaches on task descriptions, though completeness remains limited. Tool-aware retrievers outperform dense and sparse baselines on task queries, while dense retrievers are more competitive on task descriptions. All methods exhibit low completeness, particularly under high-level task descriptions, indicating difficulty in identifying agents with comprehensive task-solving capability. Decoder-only and LLM-based rerankers perform more strongly on task descriptions, suggesting their generative capacity helps infer implicit requirements.

The authors evaluate reranking methods on task descriptions using execution-based relevance, comparing various model families including cross-encoders, tool-specific models, decoder-only models, and LLM-based approaches. Results show that while different methods achieve similar performance on concrete task queries, LLM-based rerankers perform more strongly on high-level task descriptions, though completeness remains limited across all methods. The evaluation highlights a persistent gap between model rankings and actual execution performance, indicating misalignment between agent documentation and real-world effectiveness. LLM-based rerankers outperform other methods on high-level task descriptions, suggesting their ability to infer implicit requirements. All methods show low completeness, indicating difficulty in identifying agents that fully satisfy complex task requirements. There is a significant gap between model rankings and golden execution-based rankings, reflecting a misalignment between documentation and actual agent performance.
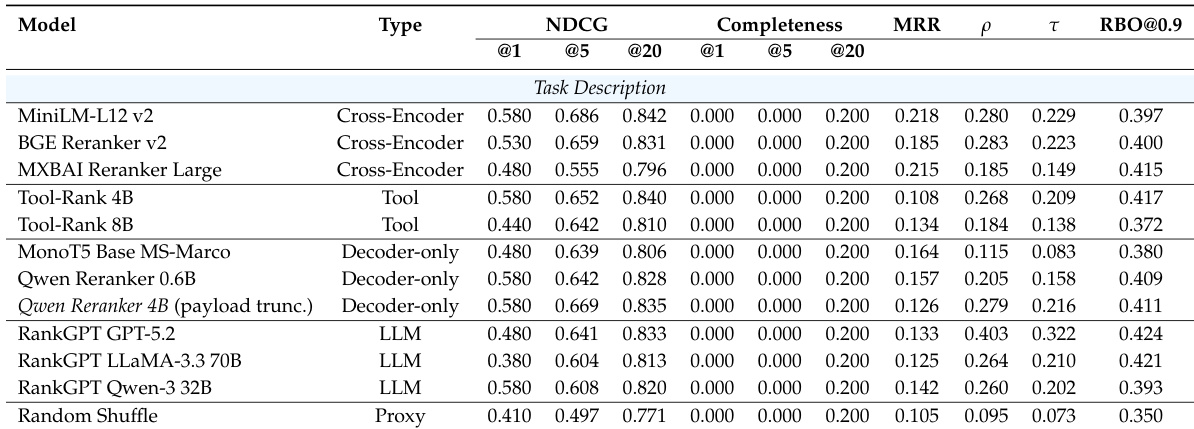
The authors evaluate agent retrieval and reranking methods under different task specifications, comparing performance across retrieval and reranking models. Results show that tool-aware and dense methods perform well on executable queries, while decoder-only and LLM-based rerankers show stronger performance on high-level task descriptions, though completeness remains limited across all methods. Tool-aware and dense retrieval models outperform other methods on executable task queries, while dense models become more competitive on high-level task descriptions. Decoder-only and LLM-based rerankers achieve stronger performance on high-level task descriptions, suggesting their ability to infer implicit requirements. Completeness remains low across all methods, indicating a persistent gap between agent documentation and actual execution performance.
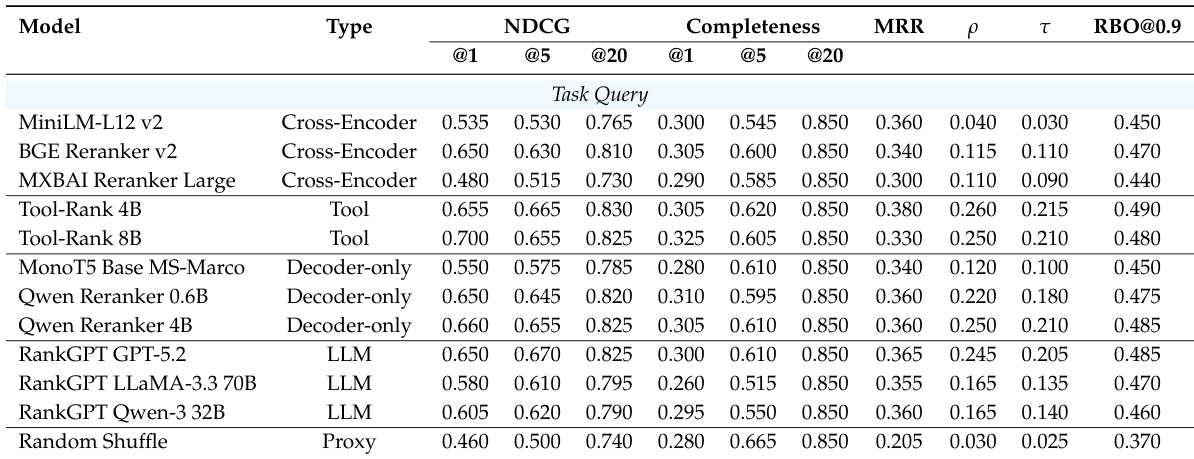
The authors evaluate retrieval models across two benchmarks, focusing on performance differences between executable task queries and high-level task descriptions. Results show that tool-aware and dense models perform well on task queries, while dense models are more competitive on task descriptions, though overall completeness remains low, indicating challenges in aligning documentation with execution effectiveness. Tool-aware and dense models outperform sparse methods on executable task queries, while dense models become more competitive on high-level task descriptions. Performance drops significantly when moving from executable queries to high-level descriptions, with low completeness across all methods. Decoder-only and LLM-based rerankers show stronger performance on task descriptions, suggesting better handling of implicit requirements.
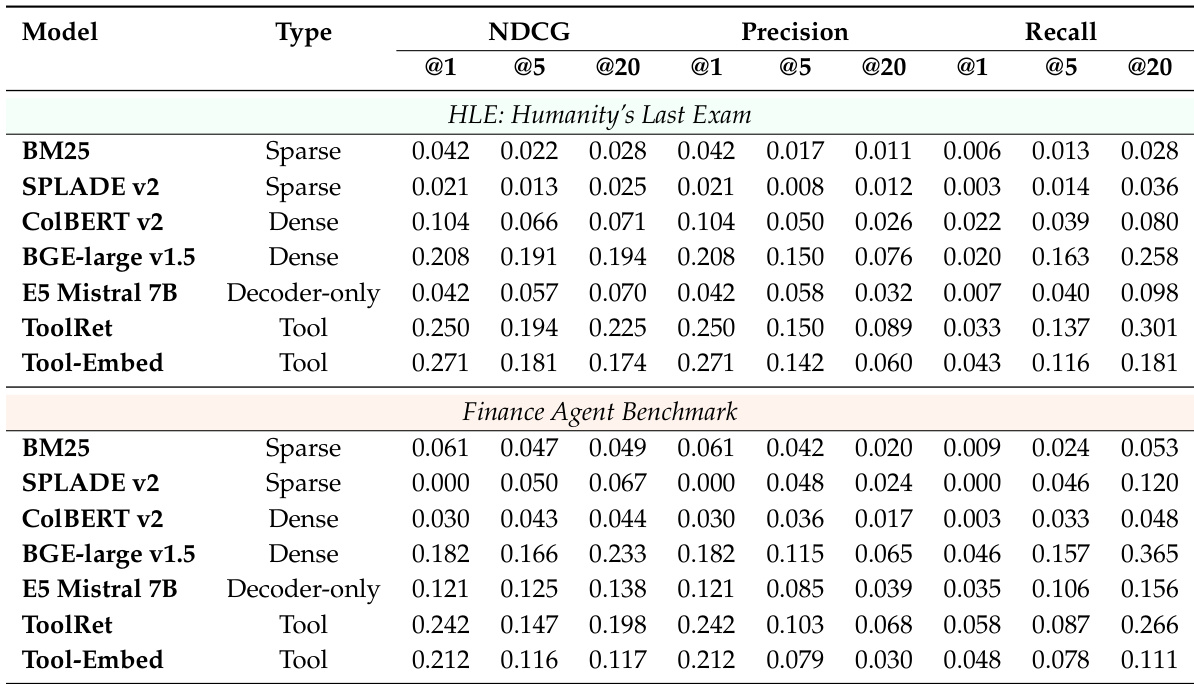
The authors evaluate agent search benchmarks and retrieval-reranking methods across a range of executable and high-level task specifications using the diverse AgentSearchBench. While tool-aware and dense retrievers excel at handling concrete task queries, LLM-based rerankers demonstrate a superior ability to infer implicit requirements within abstract task descriptions. Despite these varying strengths, all methods struggle with completeness and show a persistent misalignment between agent documentation and actual execution performance.