Command Palette
Search for a command to run...
Qwen3.5-Omni Technical Report
Qwen3.5-Omni Technical Report
Qwen Team
Abstract
In this work, we present Qwen3.5-Omni, the latest advancement in the Qwen-Omni model family. Representing a significant evolution over its predecessor, Qwen3.5-Omni scales to hundreds of billions of parameters and supports a 256k context length. By leveraging a massive dataset comprising heterogeneous text-vision pairs and over 100 million hours of audio-visual content, the model demonstrates robust omni-modality capabilities. Qwen3.5-Omni-plus achieves SOTA results across 215 audio and audio-visual understanding, reasoning, and interaction subtasks and benchmarks, surpassing Gemini-3.1 Pro in key audio tasks and matching it in comprehensive audio-visual understanding. Architecturally, Qwen3.5-Omni employs a Hybrid Attention Mixture-of-Experts (MoE) framework for both Thinker and Talker, enabling efficient long-sequence inference. The model facilitates sophisticated interaction, supporting over 10 hours of audio understanding and 400 seconds of 720P video (at 1 FPS). To address the inherent instability and unnaturalness in streaming speech synthesis, often caused by encoding efficiency discrepancies between text and speech tokenizers, we introduce ARIA. ARIA dynamically aligns text and speech units, significantly enhancing the stability and prosody of conversational speech with minimal latency impact. Furthermore, Qwen3.5-Omni expands linguistic boundaries, supporting multilingual understanding and speech generation across 10 languages with human-like emotional nuance. Finally, Qwen3.5-Omni exhibits superior audio-visual grounding capabilities, generating script-level structured captions with precise temporal synchronization and automated scene segmentation. Remarkably, we observed the emergence of a new capability in omnimodal models: directly performing coding based on audio-visual instructions, which we call Audio-Visual Vibe Coding.
One-sentence Summary
The Qwen Team presents Qwen3.5-Omni, a large-scale omni-modality model utilizing a Hybrid Attention Mixture-of-Experts framework to support a 256k context length and efficient long-sequence inference, while incorporating Adaptive Rate Interleave Alignment (ARIA) to achieve state-of-the-art results across 215 audio and audio-visual benchmarks and provide stable, natural conversational speech synthesis.
Key Contributions
- The paper introduces Qwen3.5-Omni, a unified end-to-end model that utilizes a Hybrid Attention Mixture-of-Experts (MoE) framework for both its Thinker and Talker components to enable efficient long-sequence inference. This architecture supports a 256k context length, allowing the model to process over 10 hours of audio and 400 seconds of 720P video.
- This work presents ARIA (Adaptive Rate Interleave Alignment), a technique that dynamically aligns text and speech units during streaming decoding to improve the stability and prosody of conversational speech. This method addresses encoding efficiency discrepancies between tokenizers to achieve more natural speech synthesis with minimal latency.
- The research demonstrates advanced omnimodal capabilities including controllable audio-visual captioning, real-time interaction through turn-taking intent recognition, and native agentic behavior like audio-visual code generation. Experiments show that Qwen3.5-Omni-Plus achieves state-of-the-art results across 215 audio and audio-visual benchmarks, surpassing Gemini-3.1 Pro in several key audio tasks.
Introduction
As human interaction is inherently omnimodal, there is a growing need for AI systems that can seamlessly integrate visual, auditory, and linguistic information to act as autonomous agents. While existing models have made strides in individual modalities, they often rely on passive perception-response paradigms and struggle with real-time interaction, scalable agentic behavior, and the inherent instability of streaming speech synthesis. The authors address these challenges by introducing Qwen3.5-Omni, a fully omnimodal model that unifies understanding, reasoning, generation, and action. They leverage a Hybrid Attention Mixture-of-Experts (MoE) architecture and a novel technique called Adaptive Rate Interleave Alignment (ARIA) to ensure stable, natural speech synthesis and efficient long-sequence inference. Beyond achieving state-of-the-art performance in audio-visual tasks, the model demonstrates emergent agentic capabilities such as autonomous tool use and Audio-Visual Vibe Coding, where it generates executable code directly from multi-modal instructions.
Dataset
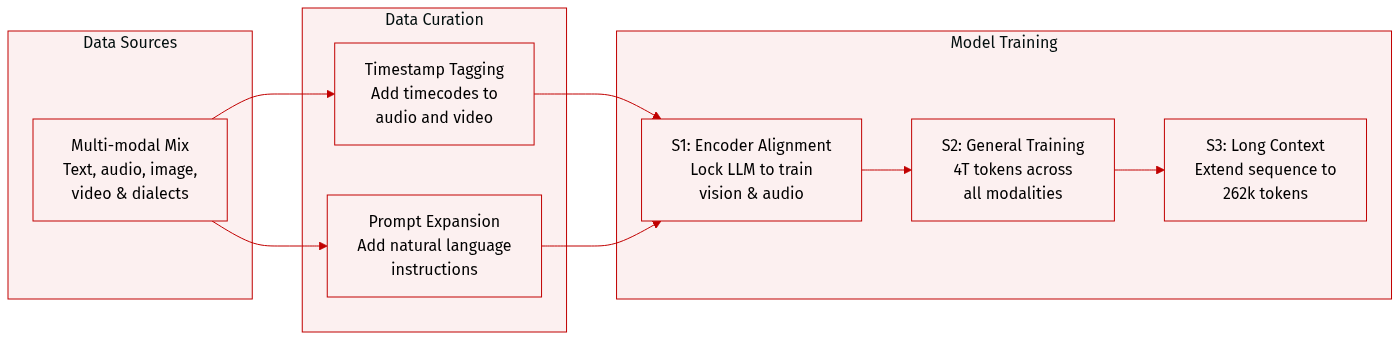
The authors utilize a diverse, multi-modal dataset to train Qwen3.5-Omni, covering multiple languages, dialects, and various data modalities including text, image-text, video-text, audio-text, video-audio, and video-audio-text.
-
Dataset Composition and Stages: The pre-training is divided into three distinct stages:
- Encoder Alignment Stage (S1): The authors focus on training the vision and audio encoders while keeping the LLM parameters locked. This stage utilizes a vast corpus of audio-text and image-text pairs to align the encoders with the LLM.
- General Stage (S2): The model is trained on a large-scale dataset totaling approximately 4 trillion tokens. The modality distribution is 0.92 trillion text tokens, 1.99 trillion audio tokens, 0.95 trillion image tokens, 0.14 trillion video tokens, and 0.29 trillion video-audio tokens. This stage uses a sequence length of 32,768.
- Long Context Stage (S3): To improve long-sequence understanding, the authors increase the maximum sequence length to 262,144 and raise the proportion of long audio and long video data.
-
Data Processing and Temporal Awareness:
- To improve temporal perception without the high cost of uniform sampling across different frame rates, the authors implement a timestamping strategy.
- For video or video-audio inputs, a timestamp represented as a formatted text string in seconds is prepended to each temporal patch.
- For audio sequences, timestamps are inserted at random intervals to ensure better alignment across different modalities.
- The authors also incorporate a wide range of natural language prompts to improve generalization and instruction-following capabilities.
Method
The Qwen3.5-Omni system employs a Thinker-Talker architecture designed for ultra-low-latency, end-to-end multimodal interaction. As shown in the framework diagram, the model is structured into two primary components: the Thinker and the Talker. The Thinker is responsible for multimodal understanding and text generation, while the Talker generates streaming speech tokens conditioned on the high-level representations produced by the Thinker. This separation enables efficient, real-time speech synthesis with minimal delay.
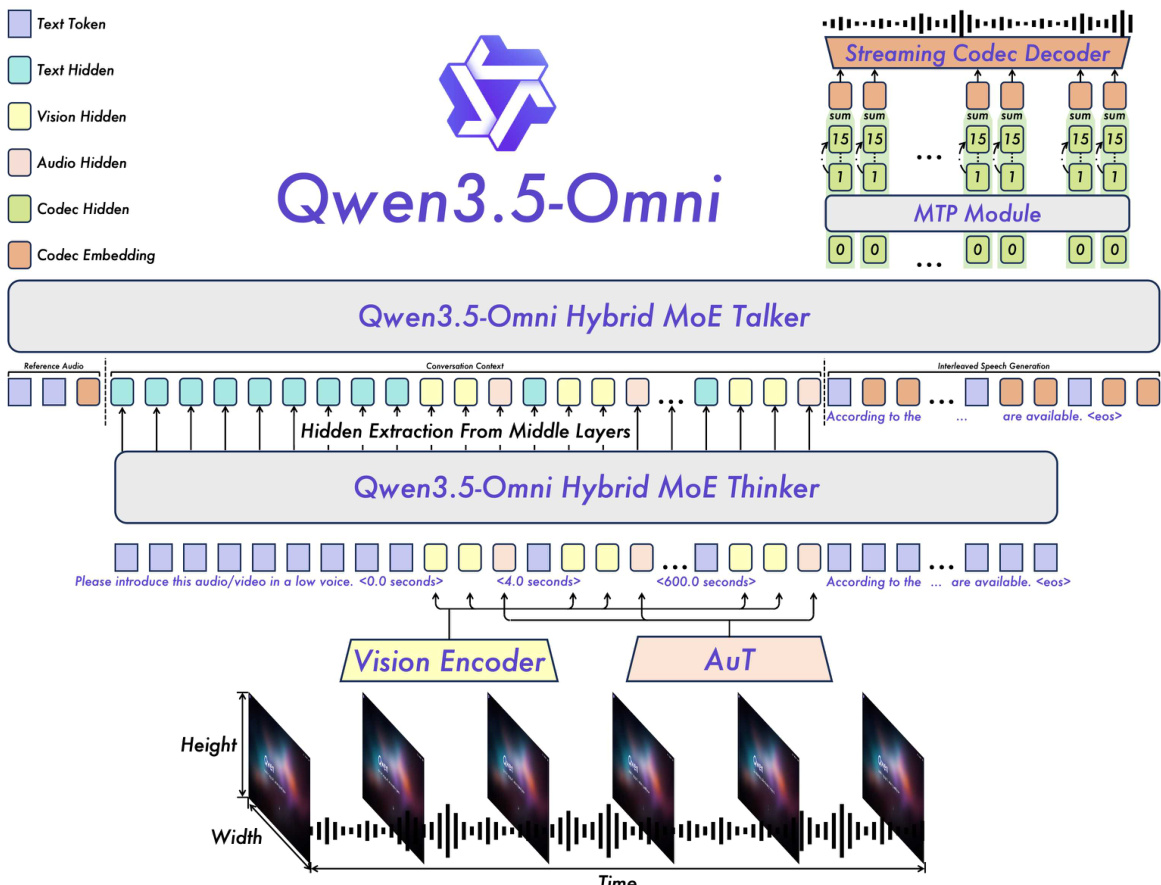
The overall backbone of the model utilizes a Hybrid Mixture-of-Experts (MoE) design, which enhances scalability and efficiency by dynamically allocating computational resources across different modalities and tasks. The Thinker processes multimodal inputs, including text, audio, and video, through a unified representation framework. Text inputs are tokenized using the Qwen3.5 tokenizer, which employs byte-level byte-pair encoding with a 250k vocabulary size. Audio signals are processed via the AuT encoder, which converts raw waveforms into 128-channel mel-spectrograms at a 16 kHz sampling rate. Video inputs are handled by a vision encoder that processes both images and videos, with frames sampled at a dynamic rate to maintain alignment with the audio stream.
To preserve temporal coherence, especially in long audio-video contexts, the model incorporates explicit timestamps into the input sequence. For audio, temporal IDs are assigned every 160 ms, while video frames are assigned monotonically increasing temporal IDs adjusted to a consistent 160 ms resolution. This approach, combined with the use of TM-RoPE for temporal awareness, enables the model to effectively model long-range temporal dependencies. Positional encoding is made contiguous across modalities, with each subsequent modality starting from one plus the maximum position ID of the previous modality, ensuring seamless integration of diverse inputs.
The Talker component is responsible for generating streaming speech. It operates directly on the RVQ tokens produced by the Qwen3.5-Omni-Audio-Tokenizer and employs a multi-token prediction (MTP) module to model residual codebooks, enabling fine-grained control over acoustic details. The MTP module outputs the necessary codebooks for each frame, which are then processed by a Code2Wav renderer to incrementally synthesize the corresponding waveform. This design allows for frame-by-frame streaming generation, achieving ultra-low-latency speech synthesis.
To support real-time interaction, Qwen3.5-Omni adopts both chunk-wise streaming input processing in the Thinker and a streaming Talker design. The Talker is conditioned on the rich contextual information provided by the Thinker, including historical text tokens, multimodal representations, and the current turn's text, enabling dynamic modulation of acoustic attributes such as prosody, loudness, and emotion. ARIA (Adaptive Rate Interleave Alignment) is introduced to dynamically align text and speech units before interleaving, mitigating issues caused by mismatched tokenization rates between text and speech.
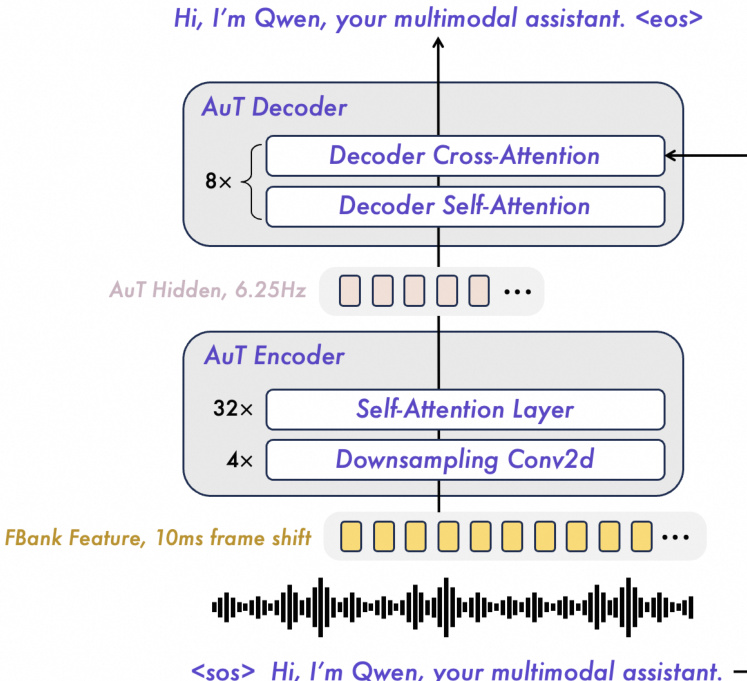
The AuT encoder, as shown in the figure, is a transformer-based audio encoder trained from scratch on 40 million hours of audio-text pairs. It downsamples filter bank features using four Conv2D blocks and processes them through self-attention layers to obtain audio tokens at a 6.25 Hz rate. The encoder is trained with a dynamic attention window size mechanism to balance performance across real-time prefill caching and offline audio understanding tasks. This design enables the model to handle extended inputs, supporting up to 256k tokens, 10 hours of audio, or 400 seconds of 720P video at 1 FPS.
The training process for the Thinker involves a three-stage strategy. Stage 1, Specialist Distillation, uses domain-specialized teacher models to establish a strong foundation for omnimodal capabilities. Stage 2, On-Policy Distillation, aligns the model's audio-conditioned outputs with its text-conditioned behavior to reduce the quality gap between responses to audio and text queries. Stage 3, Interaction-Aligned Reinforcement Learning, optimizes the model for real-world interactive use by addressing issues such as language code-switching and persona inconsistency through multi-turn interaction trajectories and user experience-based reward signals.
The Talker is trained through a four-stage pipeline. The General Stage pre-trains the model on over 20 million hours of multilingual speech data with multimodal context. The Long-Context Stage performs data quality stratification and continual pre-training to improve naturalness and handle long inputs. The Reinforcement Learning Stage uses Direct Preference Optimization (DPO) and rule-based rewards to align model behavior with human preferences. The Speaker Fine-tuning Stage enables voice cloning and enhances the naturalness, expressiveness, and controllability of speech outputs.
Experiment
The evaluation assesses the Qwen3.5-Omni models across multimodal understanding, speech generation, and streaming efficiency. The results demonstrate that the models achieve textual performance comparable to text-only baselines while significantly outperforming competitors in audio comprehension, video understanding, and audiovisual tasks. Furthermore, the model exhibits state-of-the-art capabilities in zero-shot, multilingual, and cross-lingual speech generation, maintaining high content fidelity and speaker similarity. Architectural optimizations also ensure stable latency and high throughput, making the system well-suited for low-latency, high-concurrency streaming interactions.
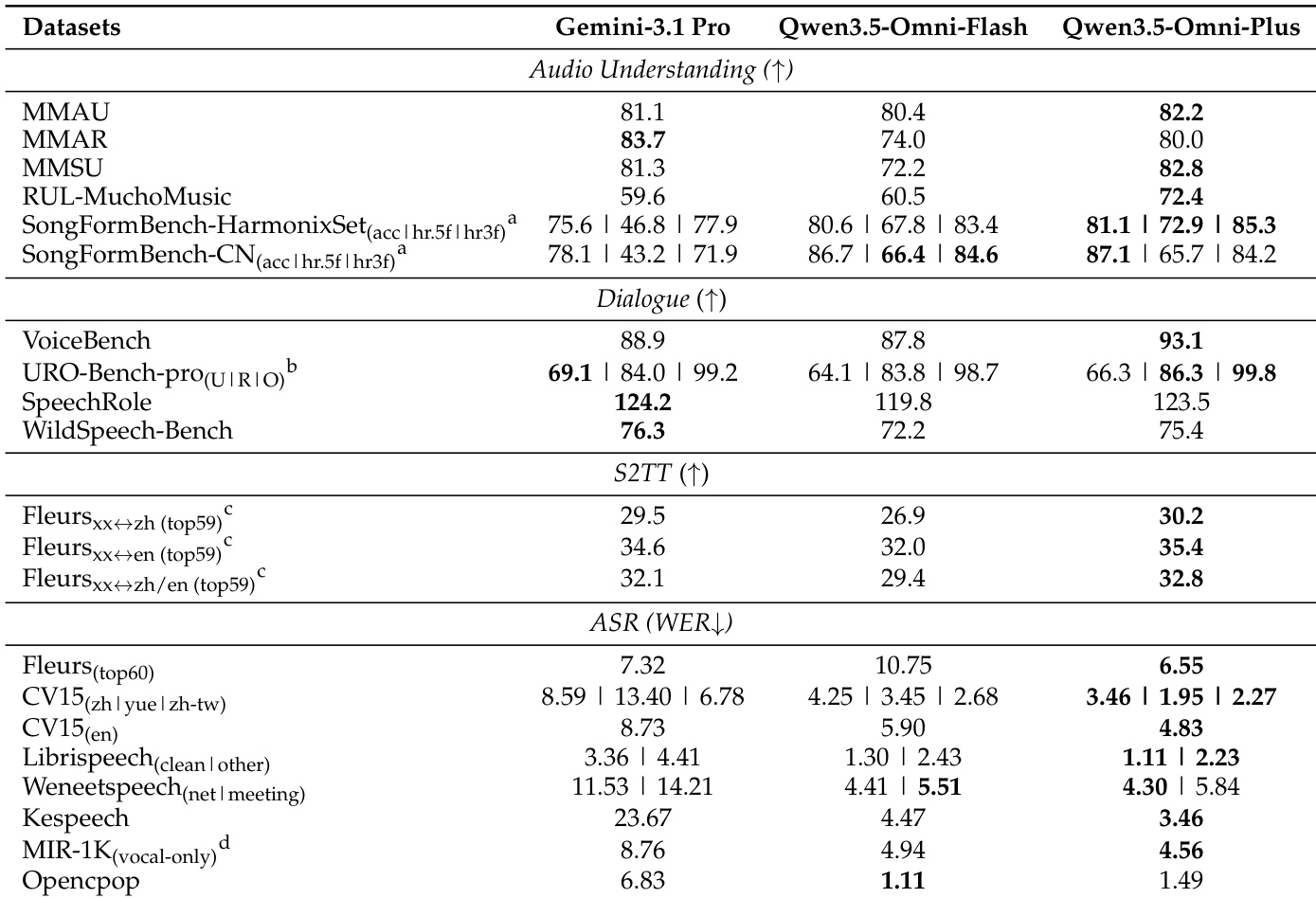
The authors compare Qwen3.5-Omni-Flash and Qwen3.5-Omni-Plus with Gemini-3.1 Pro on audio-to-text tasks, evaluating audio understanding, dialogue, translation, and speech recognition. Results show that Qwen3.5-Omni achieves superior or comparable performance across most benchmarks, particularly in audio understanding and speech recognition, while outperforming Gemini-3.1 Pro in speech-to-text translation. Qwen3.5-Omni outperforms Gemini-3.1 Pro on multiple audio understanding and speech recognition benchmarks. Qwen3.5-Omni achieves competitive results in end-to-end speech dialogue tasks compared to Gemini-3.1 Pro. Qwen3.5-Omni demonstrates strong performance in speech-to-text translation across various language pairs.
The authors evaluate zero-shot speech generation on the SEED benchmark, comparing Qwen3.5-Omni-Plus against several state-of-the-art models. Results show that Qwen3.5-Omni-Plus achieves strong content consistency, with performance comparable to leading systems and notable improvements in naturalness after optimization. Qwen3.5-Omni-Plus achieves competitive content consistency on the SEED benchmark compared to state-of-the-art models. The model demonstrates improved generation stability and naturalness after RLHF optimization. Qwen3.5-Omni-Plus shows strong performance in zero-shot speech generation, with low error rates across multiple evaluation metrics.
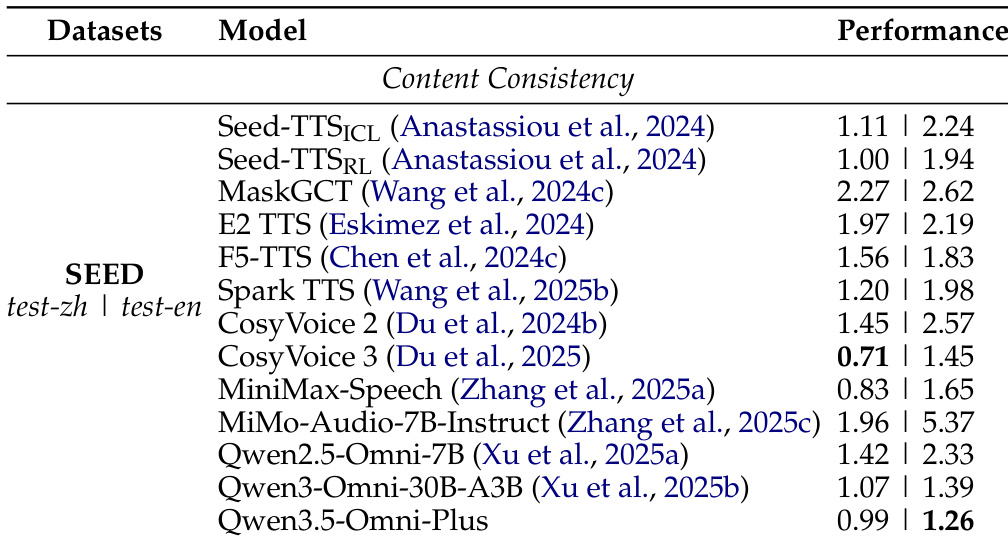
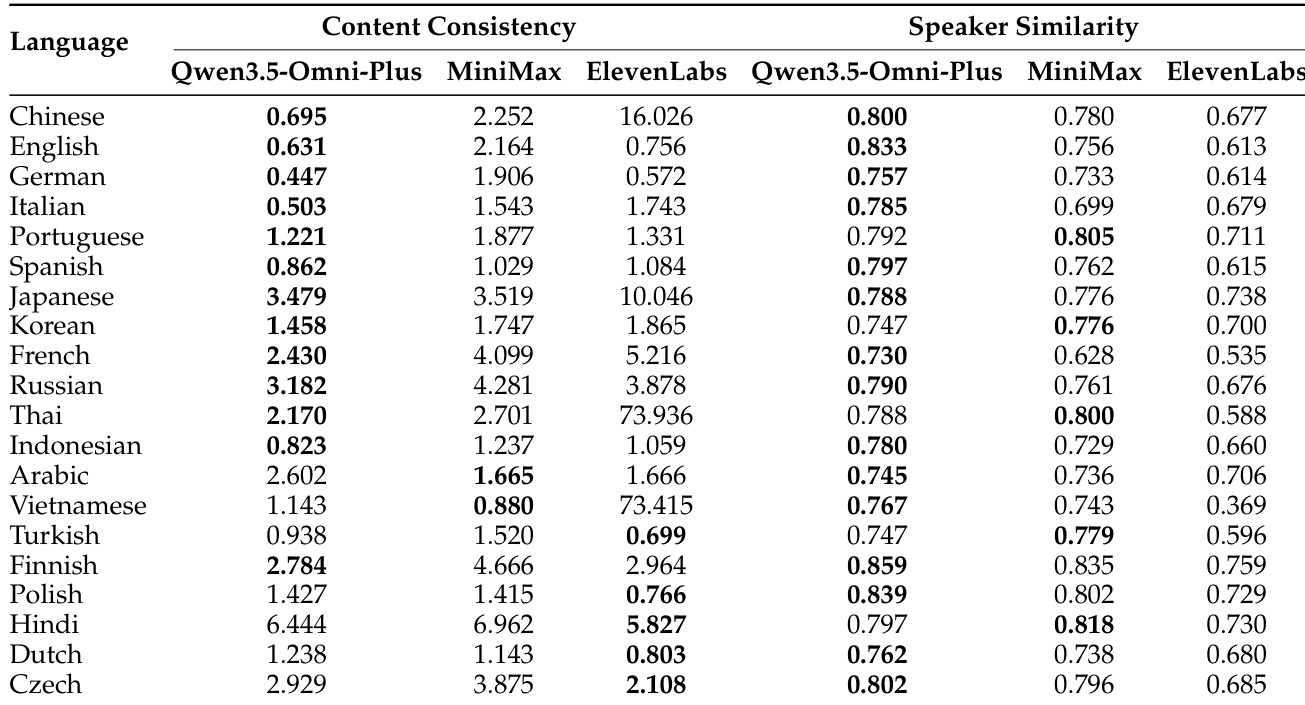
The the the table compares multilingual speech generation performance between Qwen3.5-Omni-Plus and other systems across various languages, measuring content consistency and speaker similarity. Results show that Qwen3.5-Omni-Plus achieves competitive content consistency and superior speaker similarity in most languages, particularly excelling in Japanese and Korean. Qwen3.5-Omni-Plus achieves the lowest word error rate in 22 out of 29 languages, indicating strong content consistency. Qwen3.5-Omni-Plus outperforms other systems in speaker similarity, especially in Japanese and Korean. The model maintains high performance across diverse languages, demonstrating robust multilingual generalization.
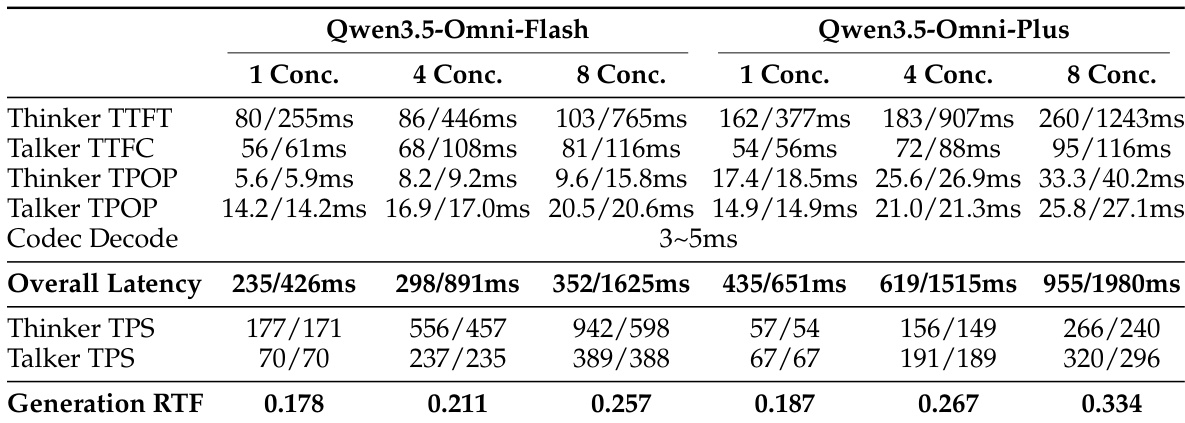
The the the table presents latency and throughput metrics for Qwen3.5-Omni-Flash and Qwen3.5-Omni-Plus under varying concurrency levels, showing stable performance as concurrency increases. Results indicate that both models maintain low latency and consistent generation throughput, with the larger variant demonstrating higher absolute values but similar scaling behavior. Latency remains stable as concurrency increases for both model variants. Both models show consistent generation throughput across different concurrency levels. Qwen3.5-Omni-Plus exhibits higher absolute latency and throughput values than Qwen3.5-Omni-Flash.
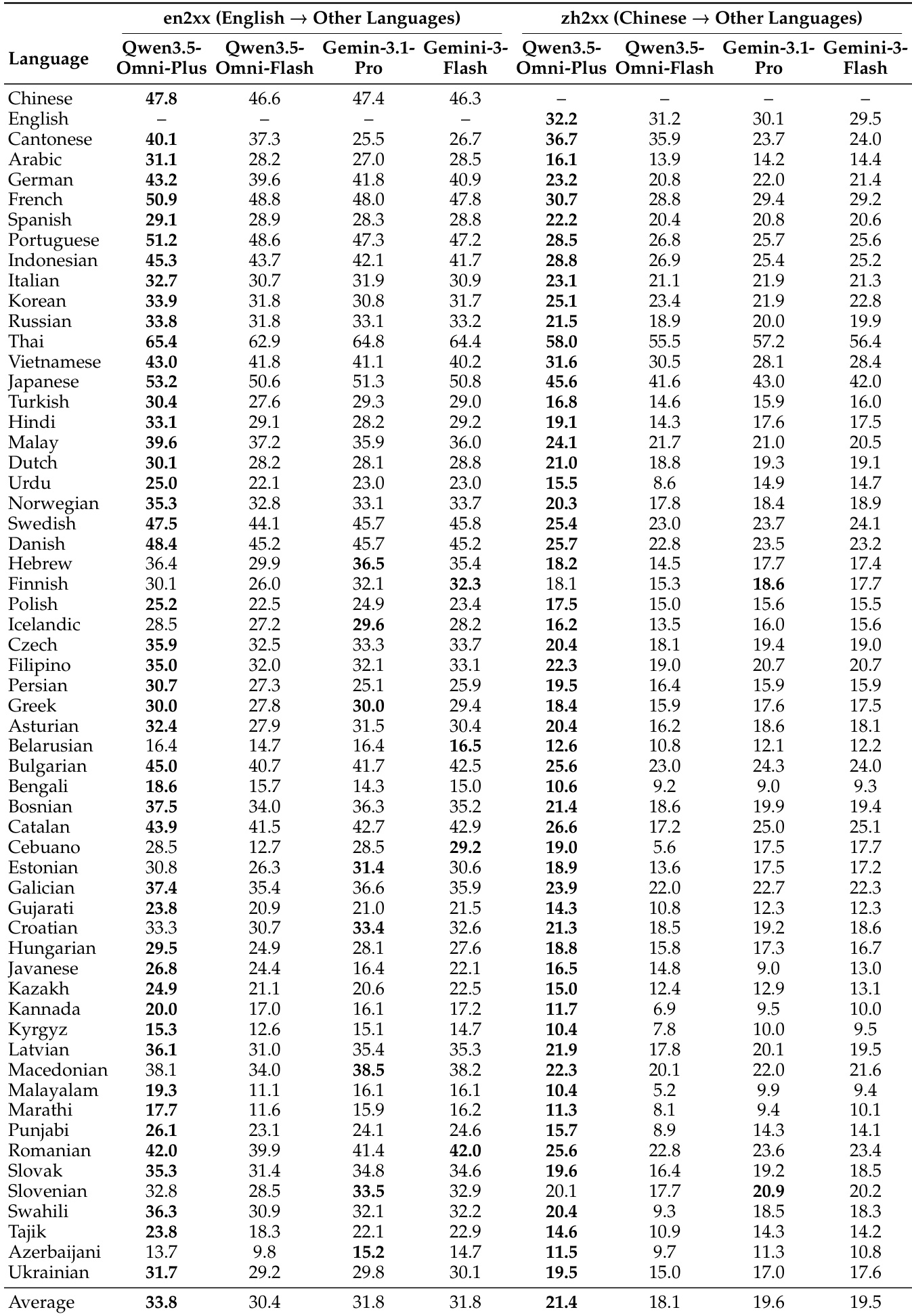
The the the table compares the performance of Qwen3.5-Omni variants with Gemini-3.1-Pro in multilingual speech generation across various languages. Results show that Qwen3.5-Omni-Plus and Qwen3.5-Omni-Flash achieve competitive or superior performance in most languages, particularly in content consistency and speaker similarity metrics. Qwen3.5-Omni variants outperform Gemini-3.1-Pro in most languages for both English and Chinese to other languages translation tasks. Qwen3.5-Omni-Plus achieves the highest scores in several languages, indicating strong multilingual speech generation capabilities. Qwen3.5-Omni-Flash demonstrates competitive performance, especially in languages where it matches or exceeds Gemini-3.1-Pro's results.
The authors evaluate the Qwen3.5-Omni series through comparative benchmarks against state-of-the-art models like Gemini-3.1 Pro, focusing on audio-to-text understanding, zero-shot speech generation, and multilingual capabilities. The results demonstrate that the Qwen models achieve superior or competitive performance in speech recognition, translation, and speaker similarity, particularly excelling in multilingual generalization and content consistency. Additionally, the models maintain stable latency and throughput under varying concurrency levels, confirming their efficiency for practical deployment.