Command Palette
Search for a command to run...
When Numbers Speak: Aligning Textual Numerals and Visual Instances in Text-to-Video Diffusion Models
When Numbers Speak: Aligning Textual Numerals and Visual Instances in Text-to-Video Diffusion Models
Zhengyang Sun Yu Chen Xin Zhou Xiaofan Li Xiwu Chen Dingkang Liang Xiang Bai
Abstract
Text-to-video diffusion models have enabled open-ended video synthesis, but often struggle with generating the correct number of objects specified in a prompt. We introduce NUMINA , a training-free identify-then-guide framework for improved numerical alignment. NUMINA identifies prompt-layout inconsistencies by selecting discriminative self- and cross-attention heads to derive a countable latent layout. It then refines this layout conservatively and modulates cross-attention to guide regeneration. On the introduced CountBench, NUMINA improves counting accuracy by up to 7.4% on Wan2.1-1.3B, and by 4.9% and 5.5% on 5B and 14B models, respectively. Furthermore, CLIP alignment is improved while maintaining temporal consistency. These results demonstrate that structural guidance complements seed search and prompt enhancement, offering a practical path toward count-accurate text-to-video diffusion. The code is available at https://github.com/H-EmbodVis/NUMINA.
One-sentence Summary
To improve numerical alignment in text-to-video diffusion models, the authors propose NUMINA, a training-free identify-then-guide framework that derives countable latent layouts from discriminative attention heads and modulates cross-attention for guided regeneration, increasing counting accuracy on CountBench by up to 7.4% for Wan2.1-1.3B and by up to 5.5% for 5B and 14B models while improving CLIP alignment and maintaining temporal consistency.
Key Contributions
- The paper introduces NUMINA, a training-free identify-then-guide framework designed to improve numerical alignment in text-to-video diffusion models.
- The method derives a countable latent layout by selecting discriminative self-and cross-attention heads to identify prompt-layout inconsistencies, which is then refined and used to modulate cross-attention during regeneration.
- Experiments on the new CountBench dataset demonstrate that the framework improves counting accuracy by up to 7.4% on the Wan2.1-1.3B model and across larger 5B and 14B models while enhancing CLIP alignment and maintaining temporal consistency.
Introduction
Text-to-video (T2V) diffusion models are essential for high-quality video synthesis in entertainment and education, but they frequently fail to generate the exact number of objects specified in a text prompt. Current models struggle with this numerical alignment due to weak semantic grounding of numeral tokens and insufficient instance separability within compressed spatiotemporal latent spaces. While retraining models could potentially address these issues, the computational cost and the need for massive, precisely annotated datasets make it impractical. The authors leverage a training-free framework called NUMINA that employs an identify-then-guide paradigm to correct these inconsistencies during the denoising process. By selecting discriminative attention heads to derive a countable latent layout and using that layout to guide regeneration, NUMINA improves counting accuracy across various model scales while maintaining temporal coherence and visual fidelity.
Method
The authors present NUMINA, a training-free framework for numerically aligned video generation that operates through a two-phase pipeline, following an identify-then-guide paradigm. As shown in the figure below, the overall framework begins with a text prompt containing numerals and a sampled noise vector, which are used to generate an initial video. The first phase, numerical misalignment identification, analyzes the attention mechanisms of the DiT model to extract an explicit layout signal that reflects the countable structure of the scene. This layout is then used in the second phase, numerically aligned video generation, to guide the re-synthesis process and correct count discrepancies.
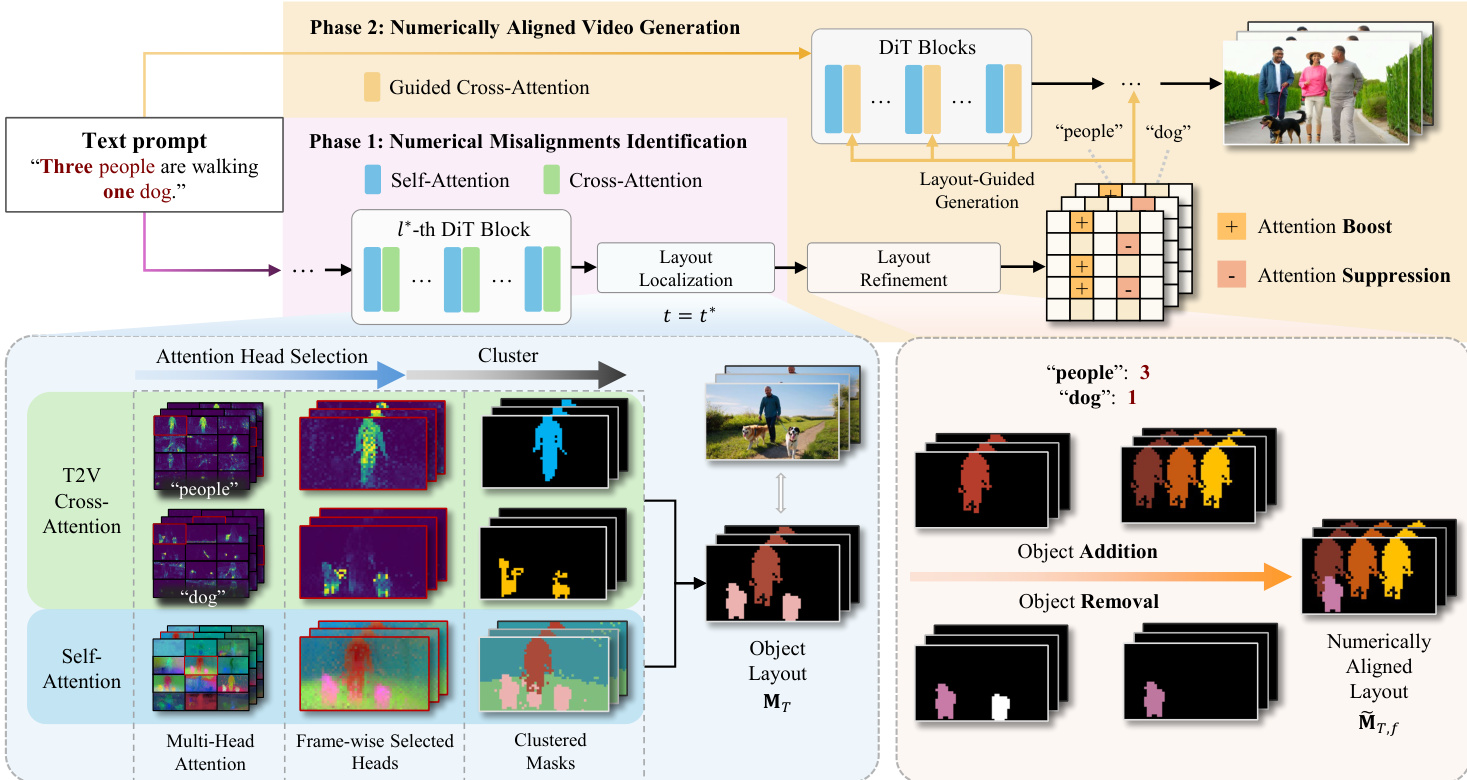
In the first phase, the method identifies count discrepancies by analyzing the DiT's attention mechanisms. This involves selecting the most instance-discriminative self-attention head and the most text-concentrated cross-attention head, and then fusing their maps to obtain an instance-level layout that is explicitly countable. The self-attention maps are processed to measure instance separability using three complementary scores: foreground-background separation, structural richness, and edge clarity. These scores are combined into a discriminability score, and the head with the highest score is selected to provide a layout with the highest instance separability. For each target noun token in the prompt, the cross-attention map is analyzed to identify the head with the highest peak activation, which indicates the model's alignment with a specific visual region. These selected self- and cross-attention maps are then fused to construct a countable foreground layout for each target noun.
The countable layout is constructed by generating spatial proposals from the self-attention map through clustering, and processing the cross-attention map by suppressing low activations and applying density-based clustering to form a focus mask. The proposals are filtered based on their semantic overlap with the focus mask, and regions with sufficient overlap are retained as valid instances. The final layout is a 2D semantic map where each pixel belonging to a valid region is assigned the corresponding class label, resulting in a map containing disjoint foreground regions that ideally correspond to individual object instances.
In the second phase, the identified layout is used to correct count errors during generation. This is achieved through a conservative two-step approach: layout refinement and layout-guided generation. The layout refinement process adjusts the per-frame layout map to match the target count parsed from the prompt. For object removal, the smallest region of the target category is erased to minimize visual impact. For object addition, a new instance is inserted using a layout template. If existing instances are present, the smallest existing region is copied as the template; otherwise, a circle is used. The template is placed at an optimal location by minimizing a heuristic cost that balances overlap with the existing layout, proximity to the spatial center, and temporal stability across frames. The resulting refined layout preserves the original spatial organization while correcting count errors.
Finally, the refined layout guides the regeneration process through a training-free modulation of the cross-attention. This is achieved by modifying either the pre-softmax attention scores or the bias term, scaled by a monotonically decreasing intensity function that applies stronger guidance early in the denoising process. For object removal, attention suppression is performed by setting the bias term to a large negative constant in regions corresponding to the category token, effectively suppressing unwanted instance generation. For object addition, attention is boosted in the new area. If the instance is templated from a manual circle, the bias term is set to a scalar coefficient. If templated from an existing reference region, the pre-softmax scores are overwritten with the mean score from the reference region, transferring the pre-trained attention properties to the new location. This process ensures stable control superposition and preserves overall visual fidelity.
Experiment
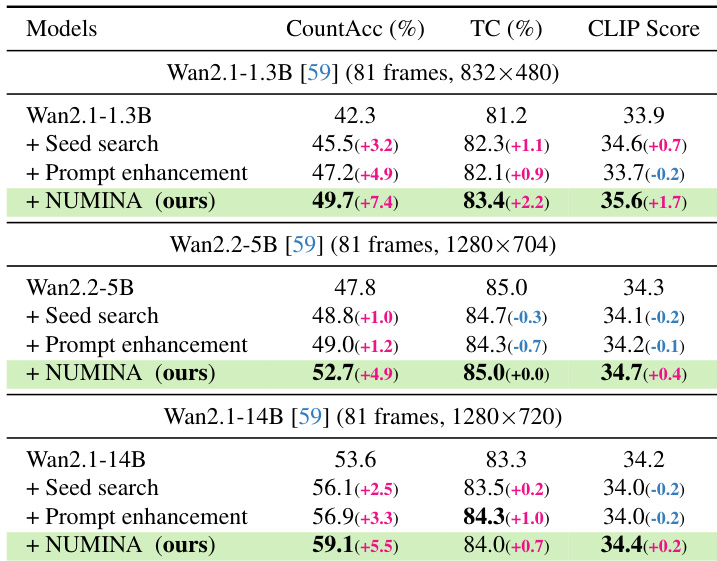
The researchers evaluated NUMINA using CountBench, a new benchmark designed to test numerical fidelity in complex text-to-video scenarios, across various model scales and architectures including Wan and CogVideoX. The experiments demonstrate that NUMINA significantly improves counting accuracy and semantic alignment while maintaining temporal consistency and high visual quality. The results show that the method is highly scalable, effective in high-count scenarios, and provides a more efficient and reliable alternative to traditional trial-and-error strategies like seed search.
The authors evaluate NUMINA against baseline models and existing strategies on text-to-video generation tasks. Results show that NUMINA consistently improves counting accuracy across different model scales while maintaining or enhancing temporal consistency and semantic alignment. The method outperforms seed search and prompt enhancement, especially in complex scenarios with higher object counts. NUMINA significantly improves counting accuracy compared to baseline models and existing strategies. The method maintains or improves temporal consistency and semantic alignment across all tested models. NUMINA enables smaller models to surpass the performance of larger baseline models in counting accuracy.
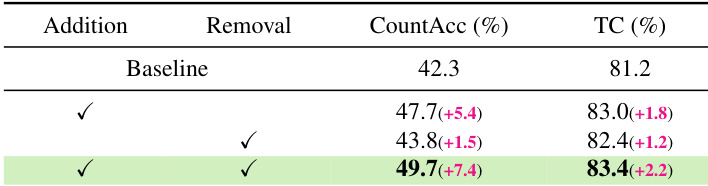
The authors evaluate NUMINA's impact on counting accuracy and temporal consistency by comparing baseline results with those from adding object addition and removal operations. Results show that both operations improve counting accuracy, with the combination achieving the highest performance while also enhancing temporal consistency. Adding object addition significantly improves counting accuracy over the baseline Combining addition and removal operations yields the highest counting accuracy and temporal consistency The method maintains or improves temporal consistency while enhancing numerical alignment
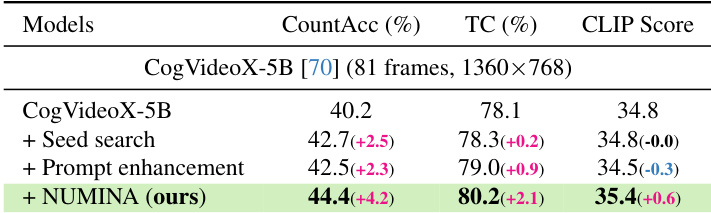
The authors evaluate NUMINA on CogVideoX-5B, showing significant improvements in counting accuracy, temporal consistency, and CLIP score compared to baseline methods. Results demonstrate that NUMINA enhances numerical alignment while maintaining or improving generation quality. NUMINA substantially improves counting accuracy over baseline and enhancement strategies The method boosts temporal consistency and CLIP score, indicating better video quality and alignment NUMINA achieves higher performance with a single generation pass, avoiding the need for seed search or prompt enhancement
The authors introduce NUMINA, a training-free method that enhances numerical alignment in text-to-video generation. Results show that NUMINA significantly improves counting accuracy across various models while maintaining or improving temporal consistency and semantic quality. NUMINA substantially boosts counting accuracy compared to baseline models and existing strategies The method improves temporal consistency and semantic alignment without degrading video quality Combining NUMINA with other enhancement techniques achieves the highest performance
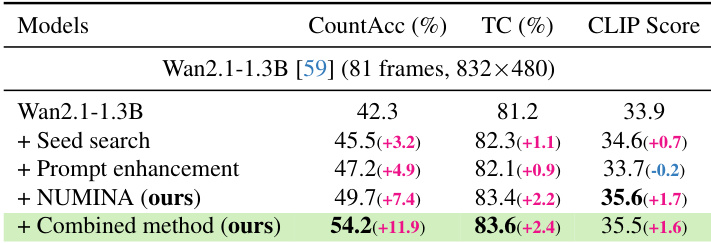
The authors analyze the impact of different hyperparameter values on counting accuracy. Results show that various settings yield similar performance, with only minor variations in accuracy, indicating the method's stability across a range of configurations. Different hyperparameter settings produce comparable counting accuracy with only slight variations. The method demonstrates robustness to changes in hyperparameter values, showing stable performance. Variations in hyperparameter values have minimal impact on overall counting accuracy.
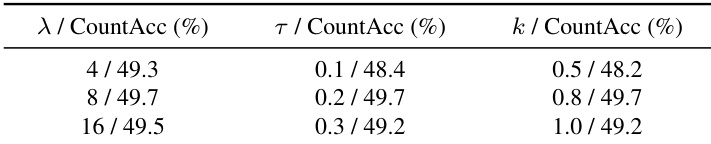
NUMINA is evaluated against baseline models and existing enhancement strategies to validate its effectiveness in improving numerical alignment during text-to-video generation. The results demonstrate that the method consistently enhances counting accuracy and temporal consistency across various model scales and complex scenarios. Furthermore, the approach proves to be highly robust and stable, maintaining high performance even with variations in hyperparameter configurations.