Command Palette
Search for a command to run...
GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents
GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents
Mingyu Ouyang Siyuan Hu Kevin Qinghong Lin Hwee Tou Ng Mike Zheng Shou
Abstract
Towards an embodied generalist for real-world interaction, Multimodal Large Language Model (MLLM) agents still suffer from challenging latency, sparse feedback, and irreversible mistakes. Video games offer an ideal testbed with rich visual observations and closed-loop interaction, demanding fine-grained perception, long-horizon planning, and precise control. However, systematically evaluating these capabilities is currently hindered by heterogeneous action interfaces and heuristic verification. To this end, we introduce GameWorld, a benchmark designed for standardized and verifiable evaluation of MLLMs as generalist game agents in browser environments. Two game agent interfaces are studied: (i) computer-use agents that directly emit keyboard and mouse controls, and (ii) generalist multimodal agents that act in a semantic action space via deterministic Semantic Action Parsing. GameWorld contains 34 diverse games and 170 tasks, each paired with state-verifiable metrics for outcome-based evaluation. The results across 18 model-interface pairs suggest that even the best performing agent is far from achieving human capabilities on video games. Extensive experiments of repeated full-benchmark reruns demonstrate the robustness of the benchmark, while further studies on real-time interaction, context-memory sensitivity, and action validity expose more challenges ahead for game agents. Together, by offering a standardized, verifiable, and reproducible evaluation framework, GameWorld lays a robust foundation for advancing research on multimodal game agents and beyond. The project page is at https://gameworld-bench.github.io.
One-sentence Summary
To address the challenges of evaluating multimodal large language model agents, the authors introduce GameWorld, a standardized benchmark for browser-based video games that utilizes state-verifiable metrics to evaluate both computer-use agents and generalist agents using semantic action parsing across 34 diverse games and 170 tasks.
Key Contributions
- The paper introduces GameWorld, a benchmark designed for the standardized and verifiable evaluation of Multimodal Large Language Model agents within browser-based video game environments.
- This work implements two distinct agent interfaces consisting of computer-use agents that utilize direct keyboard and mouse controls and generalist multimodal agents that operate through deterministic Semantic Action Parsing.
- Extensive experiments across 34 diverse games and 170 tasks demonstrate that current top-performing agents still fall significantly short of human capabilities, while further analyses reveal critical challenges in real-time interaction and context-memory sensitivity.
Introduction
Video games serve as a critical testbed for evaluating multimodal large language model (MLLM) agents because they require a complex blend of visual perception, long-horizon planning, and precise control. However, existing benchmarks often struggle with heterogeneous action interfaces and rely on heuristic or VLM-based scoring methods that introduce noise and make results difficult to verify. The authors introduce GameWorld, a standardized benchmark comprising 34 diverse browser-based games and 170 tasks designed for verifiable evaluation. By utilizing a browser-based sandbox that decouples inference latency from gameplay and employing state-verifiable metrics via a serialized game API, the authors provide a reproducible framework to evaluate both low-level computer-use agents and high-level semantic generalist agents.
Dataset
-
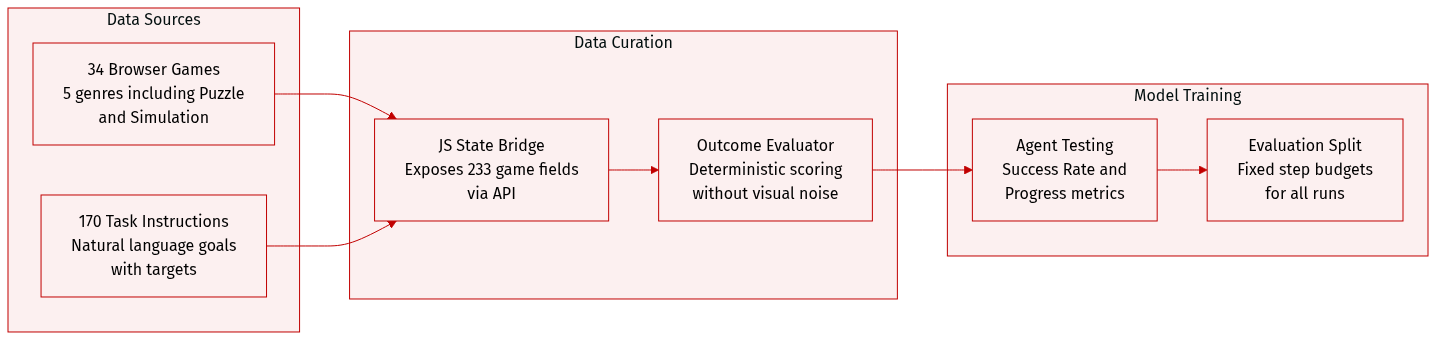
Dataset Composition and Sources: The authors introduce GameWorld, a benchmark consisting of 34 browser-based games across five distinct genres: Runner, Arcade, Platformer, Puzzle, and Simulation. The collection includes a diverse range of interaction structures, from sparse board-state reasoning in games like 2048 and Minesweeper to continuous real-time control in titles like Pac-Man and Temple Run 2, as well as open-ended simulations like a Minecraft clone.
-
Key Details for Subsets: The dataset contains 170 task instructions. Each task pairs a natural-language instruction with a quantitative target and a verifiable evaluator. The games are categorized by genre to test specific capabilities:
- Runner and Arcade: Focus on high-frequency reactive control and multi-entity tracking.
- Platformers: Require precise, physics-aware spatial navigation.
- Puzzles: Test logical reasoning and long-horizon planning.
- Simulations: Involve open-ended resource management and 3D spatial reasoning.
-
Data Processing and Metadata Construction: To ensure noise-free and reproducible evaluation, the authors implemented an outcome-based, state-verifiable system. Instead of relying on visual heuristics or VLM-as-judge pipelines, they injected a structured JavaScript bridge into each game to expose a serialized gameAPI state. This includes 233 manually designed, task-relevant state fields (such as score, coordinates, lives, and checkpoints) that allow for deterministic measurement of task success and progress.
-
Evaluation and Usage: The benchmark is designed to evaluate both Computer-Use Agents and Generalist Multimodal Agents through a shared executable action space. Agents operate within a fixed step budget and are evaluated using two primary metrics:
- Success Rate (SR): A binary metric indicating if the agent met the task target.
- Progress (PG): A normalized measure [0,1] representing how far the agent advanced toward the objective, providing partial credit for incomplete runs. To prevent early mistakes from zeroing out a run, the environment preserves the best progress reached even if a terminal failure occurs, allowing the agent to continue within the remaining step budget.
Method
The framework for evaluating game agents is structured around two primary interfaces—Computer-Use Agents (CUs) and Generalist Multimodal Agents—each designed to operate within a unified control space of atomic human-computer interaction events. The architecture enables a standardized evaluation across diverse models by normalizing outputs into a shared set of executable actions such as mouse_move, key_down, and scroll. As shown in the figure below, the system distinguishes between these two interfaces: CUs directly emit low-level keyboard and mouse controls, while Generalist Agents operate in a semantic space and rely on deterministic Semantic Action Parsing to map high-level intentions to low-level commands. This shared protocol ensures a consistent runtime contract across models, allowing for interface-aware analysis of benchmark robustness and action validity.
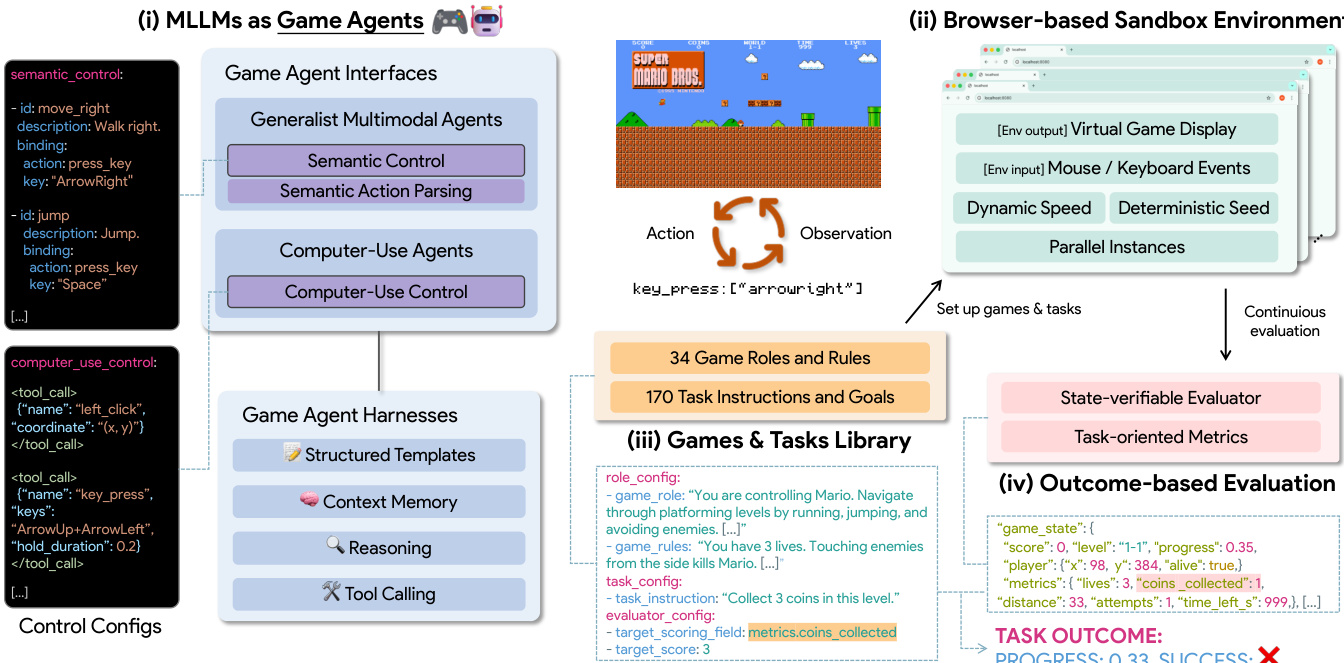
Computer-Use Agents are constrained to emit exact coordinates and key sequences derived from visual observations, enforcing a one-action-per-step policy to maintain evaluation consistency. These agents are highly sensitive to inference latency due to their direct interaction with the game environment. In contrast, Generalist Agents, while capable of semantic planning, lack the precision to generate fine-grained control sequences. To bridge this gap, the framework introduces Semantic Action Parsing, which maps semantic actions to deterministic low-level commands under the same unified runtime contract. This process removes parser-side stochasticity and supports interpretable, interface-conditioned comparisons. Both agent types are wrapped in a shared agent harness that standardizes components such as structured prompts, context memory, and model-specific tool interfaces, enabling coherent long-horizon gameplay.
The agent harness employs a fixed prompt template with four components: #Game Rules, #Role and Controls, #Task Instruction, and #Output Format. This structure ensures minimal variance across models and games, with only game-specific rules, role descriptions, and task objectives varying per configuration. Context memory is maintained as a rolling history of recent interaction rounds, storing sequences of user_prompt, screenshot, reasoning, and action. This history is prepended to the current observation, providing the agent with short-horizon trajectory context to avoid repeating failed actions and maintain consistency. The system also registers game-specific semantic actions and computer-use primitives as callable tools, using each model provider’s native function-calling interface to preserve agentic capabilities while maintaining a uniform harness-level protocol.
The benchmark loop is coordinated by a Runtime Coordinator, which manages an Agent object for each model, including its agent ID, model type, and role-specific controls. Each interaction round begins with capturing a screenshot of the current game environment, followed by model inference, parsing the raw output into an executable action payload, and executing it in the browser. The system then captures a verifiable game-state snapshot and evaluates task progress using a state-verifiable evaluator. The evaluator combines four stop or reset signals: terminal status, step budget exhaustion, target score achievement, and task-specific end-field rules. If continue_on_fail is enabled, the system resets the task upon a terminal failure and continues under the same step budget, facilitating robust evaluation.
The execution chain normalizes all actions into a unified runtime schema before they reach Playwright. For low-level actions, this includes mouse actions like click and scroll, keyboard actions like press_key, and timing actions like wait. The normalized actions are then translated into Playwright primitives, ensuring compatibility with the browser environment. Action legality is role-aware and strictly enforced by the role definition, with invalid tool calls or disallowed actions logged and ignored. For Generalist Agents, the semantic control payload is resolved through a registry-built semantic-control map with case-insensitive and alias-aware lookup, ensuring that all actions enter the same low-level execution chain as computer-use agents. This unified approach supports a comprehensive assessment of both state-of-the-art proprietary and open-source models under consistent evaluation conditions.
Experiment
The GameWorld benchmark evaluates 18 model-interface pairs across 34 browser-based games using both paused and real-time execution modes to decouple decision quality from inference latency. Through a capability-aligned curriculum and robustness testing, the experiments reveal that while current agents can achieve meaningful partial progress, they struggle with reliable task completion, long-horizon planning, and precise timing grounding. Results indicate that agents remain significantly below human-level performance, particularly in open-ended simulations and real-time environments where reasoning speed and action timing are tightly coupled.
The experiment evaluates the stability of Qwen models across repeated benchmark runs, showing consistent performance metrics. Results indicate low variance in overall progress across multiple repetitions, suggesting reliable and reproducible outcomes. Performance remains stable across repeated evaluations with low standard deviation in progress metrics. Both Computer-Use and Generalist interfaces show consistent results under repeated testing. The benchmark demonstrates reproducibility, with minimal variation in outcomes across runs.

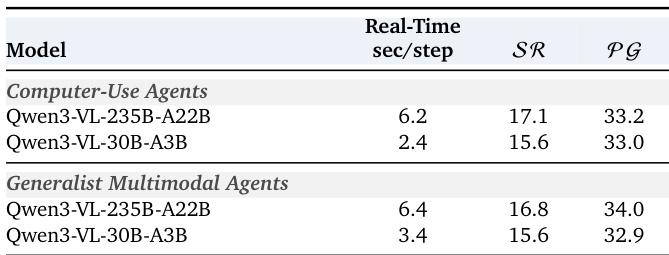
The the the table compares the real-time performance of two models across computer-use and generalist multimodal agent interfaces, showing their response times and task success and progress metrics. Results indicate that faster inference times correlate with higher success rates and progress in both agent types. Faster models achieve higher success and progress rates in real-time evaluation. Generalist agents show slightly better performance than computer-use agents across both metrics. Response time differences between models are consistent with their performance gaps in success and progress.
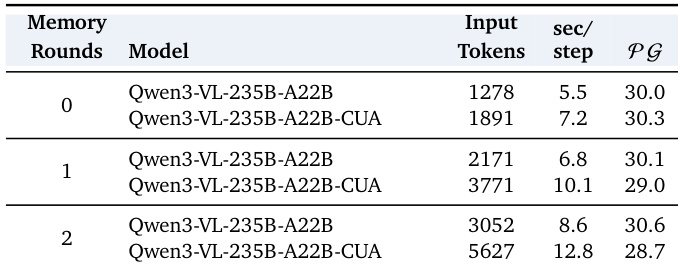
The the the table presents the impact of increasing memory rounds on model performance, input tokens, and inference speed for two interface types. As memory rounds increase, both input tokens and inference time per step grow, while performance shows divergent trends between the two interfaces, with one improving slightly and the other declining. Increasing memory rounds leads to higher input tokens and longer inference times per step. Performance trends differ between interfaces, with one showing a slight improvement and the other a decline as memory increases. The results indicate that memory has a selective benefit and is not uniformly helpful for all interfaces.
The the the table compares GameWorld with existing interactive benchmarks, highlighting differences in game count, task count, model count, and key features such as vision-centricity, configuration, and state verification. GameWorld stands out with a large number of games and tasks, support for both vision-centric and configuration-based tasks, and state-verifiable evaluation, making it suitable for scalable and outcome-based evaluation of game agents. GameWorld features a larger number of games and tasks compared to other benchmarks. GameWorld supports both vision-centric and configuration-based tasks with state-verifiable evaluation. GameWorld includes a broader range of model counts and interactive features compared to other benchmarks.
The the the table presents the estimated cost of evaluating various models across the benchmark, including input and output tokens per step and total cost. The costs vary significantly across models, with some proprietary models being substantially more expensive than open-source alternatives. Costs vary widely across models, with proprietary models generally more expensive than open-source ones. Input tokens per step are significantly higher for generalist interfaces compared to computer-use interfaces. Total evaluation cost across all listed models is substantial, indicating high computational resource requirements.
These experiments evaluate the stability, real-time efficiency, and scalability of Qwen models across various agent interfaces and memory configurations. The results demonstrate that the models provide highly reproducible performance, with faster inference speeds correlating to higher success rates and memory benefits varying by interface type. Furthermore, the GameWorld benchmark offers a more comprehensive and verifiable evaluation framework than existing methods, though the high token requirements across interfaces result in significant computational costs.