Command Palette
Search for a command to run...
MARS: Enabling Autoregressive Models Multi-Token Generation
MARS: Enabling Autoregressive Models Multi-Token Generation
Ziqi Jin Lei Wang Ziwei Luo Aixin Sun
Abstract
Autoregressive (AR) language models generate text one token at a time, even when consecutive tokens are highly predictable given earlier context. We introduce MARS (Mask AutoRegreSsion), a lightweight fine-tuning method that teaches an instruction-tuned AR model to predict multiple tokens per forward pass. MARS adds no architectural modifications, no extra parameters, and produces a single model that can still be called exactly like the original AR model with no performance degradation. Unlike speculative decoding, which maintains a separate draft model alongside the target, or multi-head approaches such as Medusa, which attach additional prediction heads, MARS requires only continued training on existing instruction data. When generating one token per forward pass, MARS matches or exceeds the AR baseline on six standard benchmarks. When allowed to accept multiple tokens per step, it maintains baseline-level accuracy while achieving 1.5-1.7x throughput. We further develop a block-level KV caching strategy for batch inference, achieving up to 1.71x wall-clock speedup over AR with KV cache on Qwen2.5-7B. Finally, MARS supports real-time speed adjustment via confidence thresholding: under high request load, the serving system can increase throughput on the fly without swapping models or restarting, providing a practical latency-quality knob for deployment.
One-sentence Summary
By utilizing a lightweight fine-tuning method that requires no architectural modifications or additional parameters, MARS enables instruction-tuned autoregressive models to perform multi-token generation through continued training, achieving up to 1.7x throughput and real-time speed adjustment via confidence thresholding.
Key Contributions
- The paper introduces MARS (Mask AutoRegreSsion), a lightweight fine-tuning method that enables instruction-tuned autoregressive models to predict multiple tokens per forward pass without adding extra parameters or architectural modifications.
- This method utilizes [MASK] tokens as explicit placeholders to train models to predict from incomplete context, achieving 1.5 to 1.7x throughput while maintaining baseline accuracy on six standard benchmarks.
- The work develops a block-level KV caching strategy and a confidence-based thresholding mechanism, which together enable up to 1.71x wall-clock speedup and real-time, on-the-fly throughput adjustments during deployment.
Introduction
Autoregressive language models generate text one token at a time, which results in uniform compute costs even when subsequent tokens are highly predictable. While methods like speculative decoding and multi-head architectures attempt to accelerate this process, they often introduce significant overhead by requiring separate draft models or additional architectural parameters and heads. The authors leverage a lightweight fine-tuning method called MARS (Mask AutoRegreSsion) to enable multi-token generation without any architectural modifications or extra parameters. By closing the design gaps between standard autoregressive models and block-masked prediction, MARS allows a single model to act as a strict superset of the original, offering a practical latency-quality knob that can achieve up to 1.71x throughput speedup during deployment.
Method
The authors leverage a dual-stream training framework to integrate multi-token prediction into an existing autoregressive (AR) model while preserving its core AR functionality. The method, named MARS, begins from a pre-trained AR supervised fine-tuning (SFT) checkpoint, ensuring the model has already learned the target data distribution. This allows the training process to focus exclusively on learning the masked prediction paradigm without disrupting the model's fundamental AR capabilities.
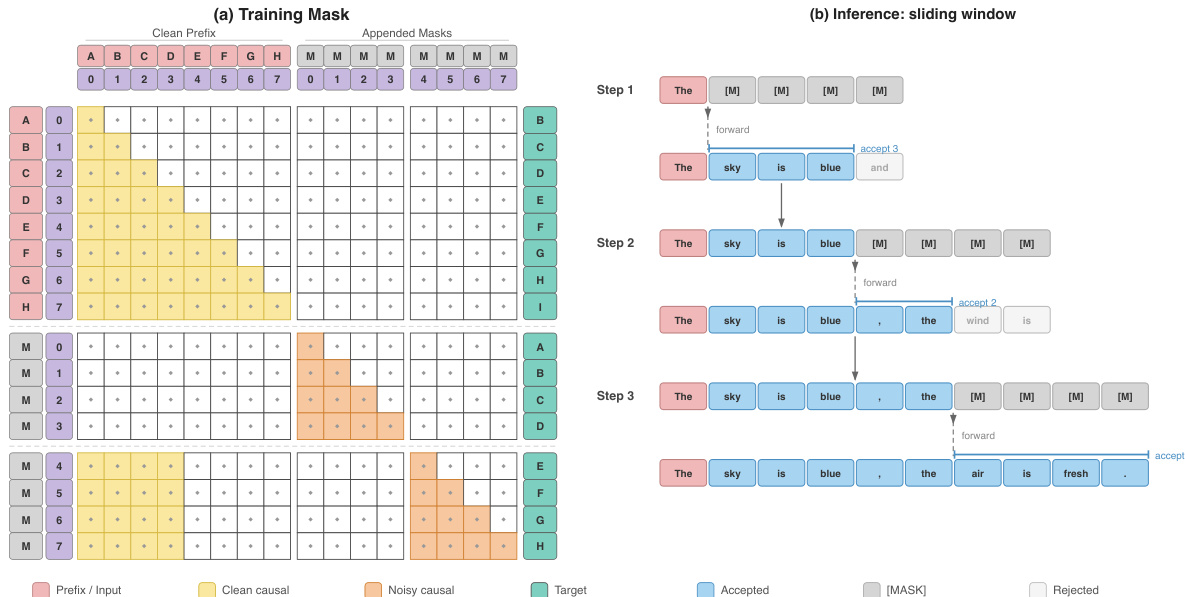
The training process involves running two copies of a sequence in parallel through the model: a clean stream and a noisy stream. The clean stream consists of the original, unmodified tokens and is used to train the model with standard AR next-token prediction. The noisy stream is constructed by dividing the sequence into blocks of size B and replacing all tokens within each block with [MASK] placeholders. The model processes a concatenated input z=[x;x~] of length 2L, where the first L positions are the clean stream and the last L are the noisy stream. A structured attention mask ensures that the model's attention pattern remains strictly causal, enforcing the correct visibility for each position. This design inherently closes the gaps related to attention pattern and logits alignment identified in prior block-masked approaches. The attention mask M is defined such that the clean causal case provides standard causal self-attention for the clean stream, the noisy intra-block causal case allows each noisy position to attend causally within its own block, and the cross-stream case enables each noisy block to see clean tokens from all preceding blocks, providing the necessary context for prediction. The training loss on the noisy stream is computed as the cross-entropy over the masked positions.
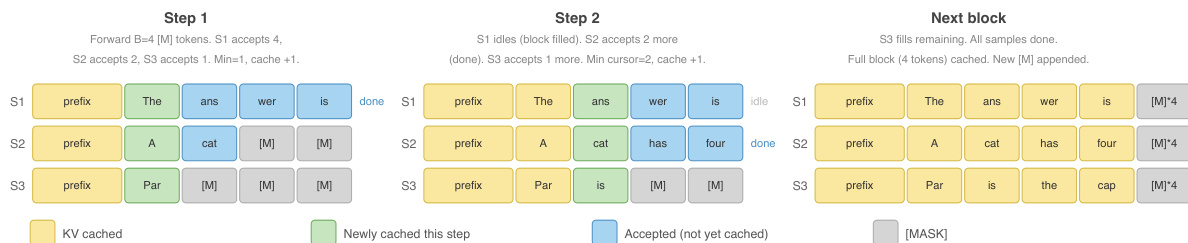
To preserve the model's AR competence, the training loss is augmented with a standard AR next-token prediction loss computed from the clean stream logits. This combined loss, L=Lmask+LAR, ensures that the model continuously practices standard AR prediction, counteracting the erosion of the AR signal that occurs as the block size increases. This mechanism decouples the AR signal from the block size, maintaining a high fraction of AR-equivalent signal even for large blocks. During inference, the model operates in a left-to-right sliding window fashion, closing the final gap related to generation order. At each step, B [MASK] tokens are appended to the current prefix, and the model runs a single forward pass to obtain logits for all B positions. Tokens are accepted consecutively from left to right while the maximum probability of the predicted token meets a confidence threshold τ. The accepted tokens are added to the prefix, and new [MASK] tokens are appended to maintain the window size. This process ensures the model degrades gracefully to standard AR decoding when confidence is low, while enabling high-throughput multi-token generation when confidence is high. The confidence threshold τ can be adjusted dynamically during serving to control the throughput-quality tradeoff.
Experiment
The experiments evaluate MARS across different model scales to validate that it preserves original autoregressive quality while enabling efficient multi-token generation. Results demonstrate that incorporating SFT loss prevents the signal decay typically seen with larger block sizes, allowing for a smooth and controllable speed-quality tradeoff via confidence thresholding. Furthermore, the implementation of a block-level KV cache ensures that these algorithmic improvements translate into significant wall-clock speedups during batch inference.
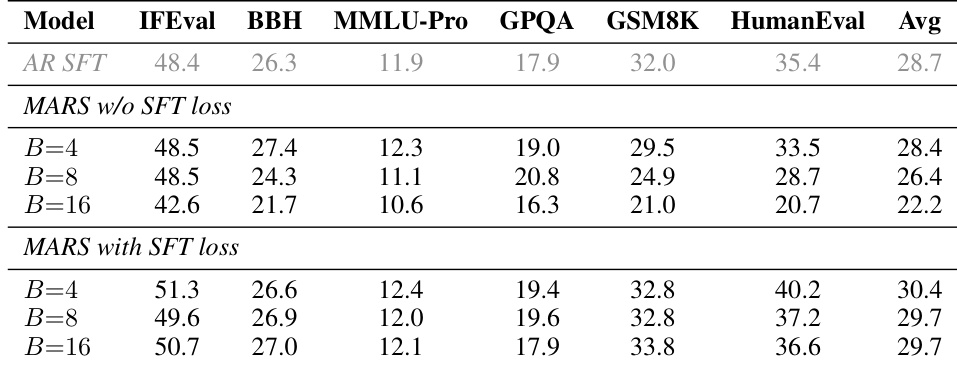
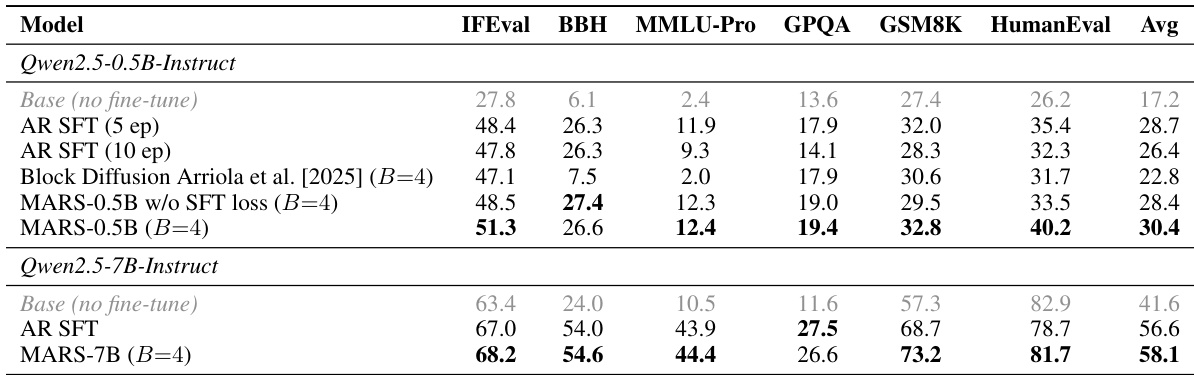
The authors evaluate MARS under one-token generation mode to assess its ability to preserve the quality of the original autoregressive (AR) model. Results show that MARS maintains or improves performance across multiple benchmarks compared to the AR SFT baseline, with significant gains observed on reasoning and coding tasks. The inclusion of the SFT loss is critical, as its absence leads to substantial performance degradation with larger block sizes. MARS maintains or improves performance over AR SFT on reasoning and coding tasks with one-token generation Without the SFT loss, larger block sizes cause significant quality degradation across benchmarks The SFT loss stabilizes performance across block sizes, ensuring consistent quality regardless of block size
The authors compare the training setup for MARS across two model scales, 0.5B and 7B, highlighting differences in hardware, block sizes, and the inclusion of the SFT loss. The evaluation uses greedy decoding with a maximum generation length of 256 tokens, and MARS is configured to generate one token per step at a threshold of 1.0. The 7B model uses NVIDIA H200 hardware and a block size of 4, while the 0.5B model uses 4, 8, and 16 block sizes. The SFT loss is included for the 0.5B model but excluded for the 7B model in the tested configurations. Both models use a learning rate of 5e-6 and are trained for 5 epochs per stage with a maximum sequence length of 512 for the 7B model and 48 for the 0.5B model.

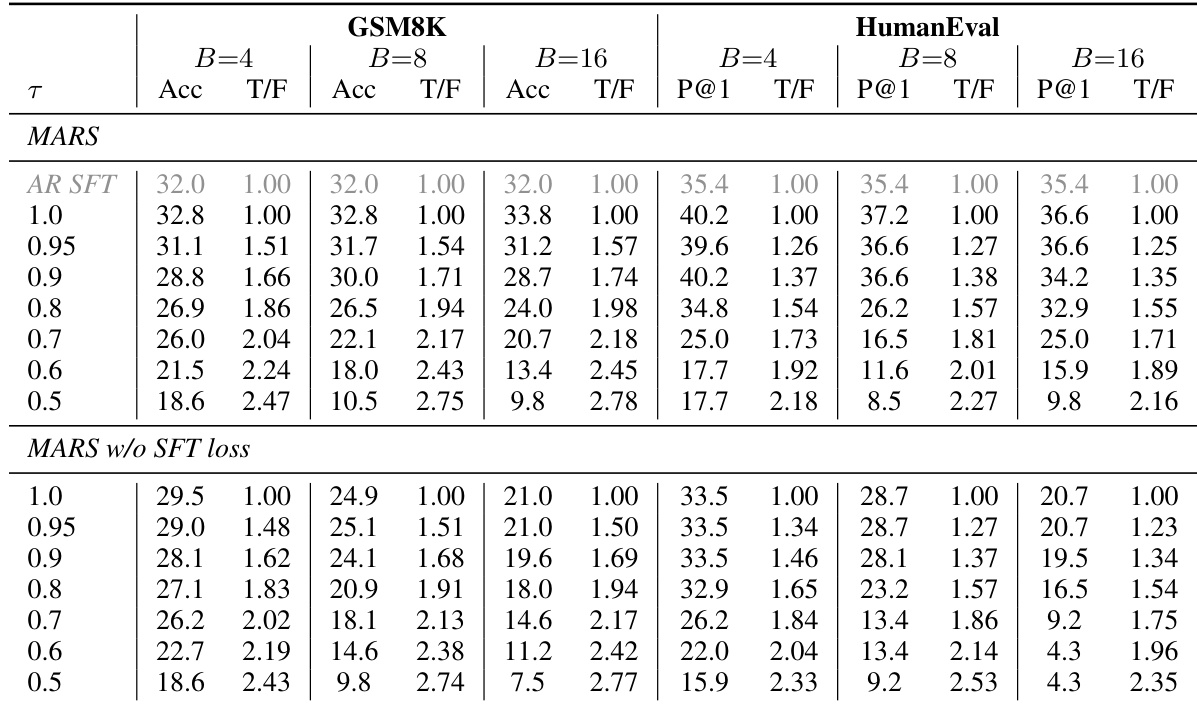
The the the table compares MARS performance with and without the SFT loss across different confidence thresholds and block sizes. Results show that MARS with the SFT loss maintains higher accuracy and smoother speed-quality tradeoffs compared to the variant without the SFT loss, especially as block size increases. The presence of the SFT loss stabilizes performance across varying generation speeds. MARS with the SFT loss achieves higher accuracy than without the SFT loss across all thresholds and block sizes. The accuracy drop with multi-token generation is small and predictable when using the SFT loss. Performance degrades significantly without the SFT loss as block size increases, indicating the loss's importance for stability.
The authors compare MARS with AR SFT and Block Diffusion models, showing that MARS maintains or improves upon the original AR model's performance across multiple benchmarks. The results indicate that MARS achieves higher accuracy than AR SFT and Block Diffusion in one-token generation mode, confirming that the additional masked-prediction training enhances quality without degrading performance. MARS achieves higher accuracy than AR SFT and Block Diffusion on multiple benchmarks in one-token mode. The gains from MARS come from the masked-prediction objective, not additional training compute. Block Diffusion performs poorly, indicating that not all block prediction formulations are compatible with AR pretraining.
The the the table compares different generation methods across four criteria: token masking, attention pattern, logits alignment, and generation order. MARS uses causal attention and left-to-right generation similar to AR, but with masked token prediction within blocks, while Block Diffusion uses bidirectional attention and confidence-based generation. MARS uses causal attention and left-to-right generation like AR, but with masked token prediction within blocks Block Diffusion uses bidirectional intra-block attention and confidence-based generation MARS maintains right-shifted logits alignment similar to AR, unlike Block Diffusion which varies

The authors evaluate MARS across different model scales and generation modes to assess its ability to preserve or enhance the quality of original autoregressive models. Results demonstrate that MARS maintains or improves performance on reasoning and coding tasks compared to standard autoregressive baselines and alternative block prediction methods. The inclusion of the SFT loss is found to be essential for stabilizing performance and preventing quality degradation as block sizes increase.