Command Palette
Search for a command to run...
Internalized Reasoning for Long-Context Visual Document Understanding
Internalized Reasoning for Long-Context Visual Document Understanding
Austin Veselka
Abstract
Visual long-document understanding is critical for enterprise, legal, and scientific applications, yet the best performing open recipes have not explored reasoning, a capability which has driven leaps in math and code performance. We introduce a synthetic data pipeline for reasoning in long-document understanding that generates thinking traces by scoring each page for question relevance, extracting textual evidence and ordering it from most to least relevant. We apply SFT to the resulting traces within tags, gated by a control token, and the resulting reasoning capability is internalized via low-strength model merging. We study Qwen3 VL 32B and Mistral Small 3.1 24B. With Qwen3 VL, we achieve 58.3 on MMLongBenchDoc, surpassing the 7x larger Qwen3 VL 235B A22B (57.0). With Mistral, we show that synthetic reasoning outperforms distillation from the Thinking version's traces by 3.8 points on MMLBD-C, and internalized reasoning exhibits 12.4x fewer mean output tokens compared to explicit reasoning. We release our pipeline for reproducibility and further exploration.
One-sentence Summary
Addressing critical enterprise, legal, and scientific applications, the authors introduce a synthetic data pipeline for internalized reasoning in long-context visual document understanding that generates ordered thinking traces for supervised fine-tuning and low-strength model merging, enabling Qwen3 VL 32B to achieve 58.3 on MMLongBenchDoc, surpassing the 7x larger Qwen3 VL 235B A22B (57.0), and allowing Mistral Small 3.1 24B to outperform distillation from the Thinking version's traces by 3.8 points on MMLBD-C while exhibiting 12.4x fewer mean output tokens than explicit reasoning.
Key Contributions
- The paper introduces a synthetic data pipeline for long-document reasoning that generates thinking traces by scoring page relevance and ordering textual evidence. This approach extends recursive answer generation to train reasoning models specifically for long-document visual question answering tasks.
- Reasoning capability is internalized through supervised fine-tuning on gated traces and low-strength model merging, allowing for causal on/off control via a token. This method achieves internalization without architectural modifications while operating at a 24B to 32B parameter scale.
- Experiments demonstrate that the model reaches 58.3 on MMLongBenchDoc with Qwen3 VL, surpassing a 7x larger variant, while internalized reasoning reduces mean output tokens by 12.4 times. The pipeline is released for reproducibility and further exploration of synthetic reasoning.
Introduction
Long-context visual language models enable complex operations over documents in critical domains like law and finance, yet current systems fail to leverage reasoning effectively due to a lack of high-signal rewards in question-answering tasks. While frontier models show equivalent performance regardless of thinking modes, prior implicit reasoning work remains confined to smaller scales or simpler tasks without confirming active inference benefits. The authors address this gap by introducing a synthetic data pipeline that generates structured reasoning traces through page-level evidence extraction and relevance scoring. They train large vision language models and utilize low-strength model merging to internalize these capabilities, proving that implicit reasoning functions as an active inference-time skill rather than a training artifact.
Dataset
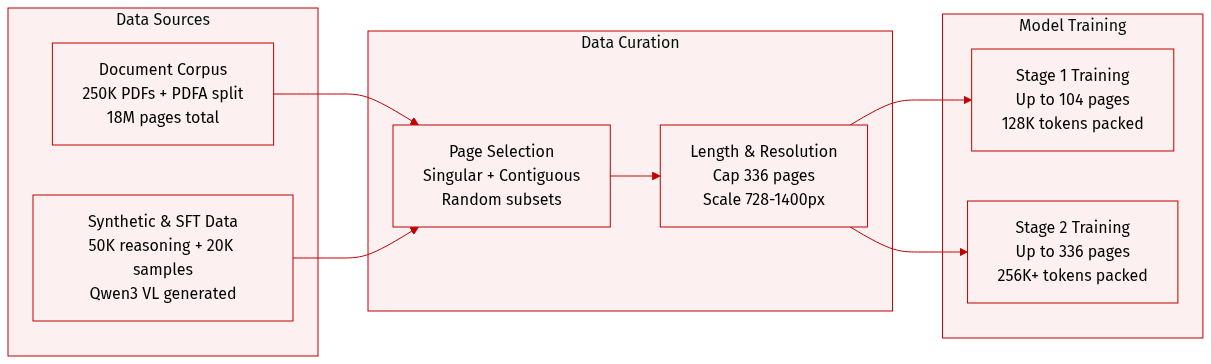
Dataset Composition and Sources
- The authors build a document corpus from 250K PDFs and the PDFA English split, covering 2M PDFs and 18M pages.
- They augment this with 50K synthetic reasoning examples and 20K external SFT samples from the Luth and Smoltalk2 datasets.
Subset Details and Statistics
- Primary corpus documents average 34 pages while PDFA documents average 8.6 pages, with all documents capped at 336 pages.
- The combined dataset averages 57.9 pages per example with a median of 16.0 pages.
- Synthetic QA pairs utilize Qwen3 VL 32B Instruct for extraction and Qwen3 VL 235B A22B for answer generation.
- Content includes singular pages, contiguous page subsets, and random page subsets.
Training Usage and Mixture
- Training proceeds in two stages targeting examples up to 104 pages and 336 pages respectively.
- The team employs sequence packing without truncation and normalizes loss by assistant token counts.
- Context limits reach 336K tokens for Mistral and 256K tokens for Qwen3 VL during the long stage.
Processing and Resolution Strategies
- Document resolution scales dynamically from 728 to 1400 pixels when full documents do not fit the context.
- CPT vectors merge with instruct models at strengths of 0.25 for Qwen3 VL and 0.5 for Mistral.
- External SFT samples follow normalized distribution mixes from referenced tables.
Method
The authors leverage a synthetic data pipeline designed to generate structured reasoning traces for long-document understanding. The complete procedure is illustrated in the framework diagram below.
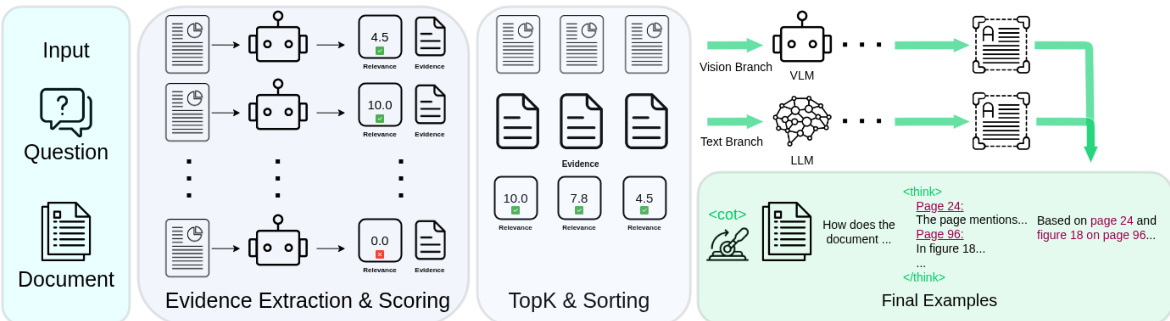
The pipeline processes a document consisting of N page images and a question Q through two distinct stages. In the first stage, evidence extraction and scoring, an extractor VLM processes each page independently alongside the question. For every page, the model extracts a natural-language evidence snippet containing relevant content or visual descriptions and assigns a relevance score on a [0, 10] scale. To guide the extraction, pages belonging to the question's source set are explicitly identified, ensuring they receive scores between [6.0, 10.0]. After processing all pages, pairs falling below a relevance threshold are discarded, and the remaining pairs are ranked by relevance to retain the top-K entries.
The second stage involves answer generation through two parallel branches to ensure comprehensive coverage of information. The visual branch utilizes a teacher VLM that receives the top-ranked page images and the question to generate an answer directly from the visual content. Conversely, the text branch employs a teacher LLM that receives only the extracted evidence snippets and the question, generating an answer without access to page images. This dual-branch approach enforces a dependency between the reasoning trace and the answer in the text branch while grounding answers in full visual content in the visual branch.
Training examples are constructed in a unified format regardless of the generation branch. Each page and evidence snippet is prefixed with its 1-indexed position to facilitate source association. A <cot> control token gates the reasoning trace within the system prompt. In 95% of training examples, the <cot> token is provided, and the assistant response begins with a <think> block containing the ordered evidence snippets, followed by the final answer. The remaining 5% of examples exclude the control token and reasoning trace to allow for mode switching at inference time.
To internalize this reasoning capability, the authors employ model merging defined as θmerged=θbase+α⋅(θSFT−θbase). By using a low merge strength (α=0.25), the resulting model retains the performance benefits of the reasoning traces without generating explicit thinking tokens during inference, effectively compressing the synthetic reasoning process into the model weights.
Experiment
The study evaluates a synthetic reasoning pipeline across long-document benchmarks such as MMLBD and MMLongBenchDoc to validate its effectiveness in visual question answering tasks. Experiments demonstrate that this approach allows smaller models to achieve state-of-the-art performance by internalizing reasoning capabilities that function as a controllable inference-time feature rather than relying on explicit thinking tokens. Furthermore, ablation analyses confirm that specific trace design improvements and control token gating are critical for outperforming standard thinking traces and non-reasoning baselines.
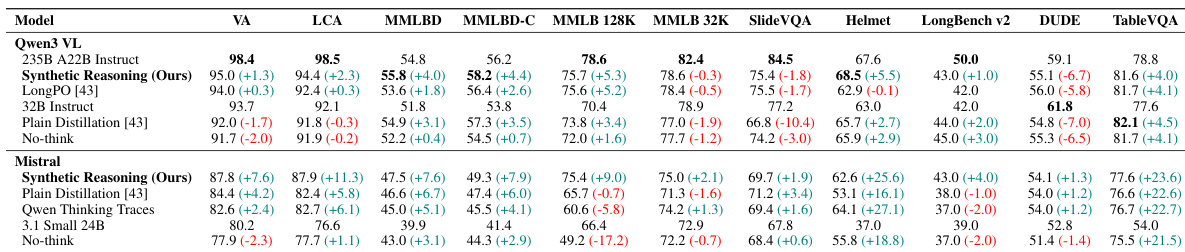
The authors present a synthetic reasoning pipeline that achieves state-of-the-art results on long-document VQA benchmarks, allowing smaller models to outperform significantly larger counterparts. The method demonstrates strong generalization across model families, consistently outperforming baselines such as plain distillation and LongPO. The proposed method achieves the highest VA and LCA scores for both Qwen and Mistral model families. Smaller models utilizing this pipeline surpass larger models on primary long-document benchmarks. The approach outperforms baselines trained on thinking traces from larger models.
The authors detail the training configuration for their synthetic reasoning pipeline across two stages, utilizing H100 hardware with increasing parallelism and batch sizes. The setup compares the computational demands and throughput for Qwen and Mistral model families, showing distinct differences in training duration and token processing capacity. Results indicate that the Mistral configuration achieved higher token throughput per batch while requiring significantly less training time than the Qwen configuration. Training was conducted in two stages with increased parallelism and token capacity in the second phase. The Mistral model family required less total training time compared to the Qwen family. Mistral configurations processed a larger volume of tokens per batch during the second training stage.

The the the table compares evaluation results across different experimental runs, revealing significant performance variations relative to a baseline. One run consistently outperforms the baseline with positive gains in visual answering and long-context understanding, while another run shows a general decline in scores across most tasks. One experimental run achieves positive improvements in visual answering and long-context benchmarks compared to the baseline. A separate run demonstrates a notable drop in performance, particularly in tasks involving longer context lengths. The results highlight that model performance is highly sensitive to the specific run configuration, with significant variance in visual and document understanding scores.

The authors compare the performance of Text and Visual answer branches across a suite of benchmarks to determine the optimal source for synthetic reasoning. The results indicate that the Text branch generally outperforms the Visual branch on document understanding tasks, while the Visual branch shows advantages on specific long-context benchmarks. The Text branch achieves higher scores than the Visual branch on VA, LCA, MMLBD, and MMLBD-C metrics. The Visual branch outperforms the Text branch notably on the MMLB 128K benchmark. On benchmarks such as SlideVQA, Helmet, and TableVQA, the performance gap between the two branches is negligible.

The authors evaluate two versions of a synthetic reasoning pipeline, demonstrating that the V2 checkpoint significantly outperforms the V1 baseline across a wide range of benchmarks. This improvement is driven by a trace redesign that fixes inference looping issues and better emphasizes page relevance. While the V2 model achieves higher scores on most tasks including visual question answering and long-context understanding, performance varies slightly on specific datasets like Helmet. The V2 checkpoint shows consistent improvements over V1 across visual question answering and long-document benchmarks. The redesign of the reasoning trace in V2 addresses previous failure modes like infinite looping. Performance gains are observed in most categories, although a slight decline is seen in the Helmet benchmark.

The authors evaluate a synthetic reasoning pipeline that enables smaller models to surpass larger counterparts on long-document VQA benchmarks across diverse model families. Comparative experiments reveal that training efficiency varies by configuration, yet the Text branch generally outperforms the Visual branch on document understanding tasks. Additionally, the V2 pipeline iteration demonstrates significant improvements over V1 by resolving inference issues, confirming the method's strong generalization and superiority over existing baselines.