Command Palette
Search for a command to run...
On-the-fly Repulsion in the Contextual Space for Rich Diversity in Diffusion Transformers
On-the-fly Repulsion in the Contextual Space for Rich Diversity in Diffusion Transformers
Omer Dahary Benaya Koren Daniel Garibi Daniel Cohen-Or
Abstract
Modern Text-to-Image (T2I) diffusion models have achieved remarkable semantic alignment, yet they often suffer from a significant lack of variety, converging on a narrow set of visual solutions for any given prompt. This typicality bias presents a challenge for creative applications that require a wide range of generative outcomes. We identify a fundamental trade-off in current approaches to diversity: modifying model inputs requires costly optimization to incorporate feedback from the generative path. In contrast, acting on spatially-committed intermediate latents tends to disrupt the forming visual structure, leading to artifacts. In this work, we propose to apply repulsion in the Contextual Space as a novel framework for achieving rich diversity in Diffusion Transformers. By intervening in the multimodal attention channels, we apply on-the-fly repulsion during the transformer's forward pass, injecting the intervention between blocks where text conditioning is enriched with emergent image structure. This allows for redirecting the guidance trajectory after it is structurally informed but before the composition is fixed. Our results demonstrate that repulsion in the Contextual Space produces significantly richer diversity without sacrificing visual fidelity or semantic adherence. Furthermore, our method is uniquely efficient, imposing a small computational overhead while remaining effective even in modern "Turbo" and distilled models where traditional trajectory-based interventions typically fail.
One-sentence Summary
Researchers from Tel Aviv University and Snap Research propose Contextual Space repulsion, a framework that injects on-the-fly diversity into Diffusion Transformers by intervening in multimodal attention channels. This technique overcomes typicality bias in models like Flux-dev by steering generative intent before visual commitment, delivering rich variety with minimal computational overhead.
Key Contributions
- The paper introduces a Contextual Space repulsion framework that applies on-the-fly intervention within the multimodal attention channels of Diffusion Transformers to steer generative intent after structural information emerges but before composition is fixed.
- This method injects repulsion between transformer blocks where text conditioning is enriched with emergent image structure, allowing the model to explore diverse paths while preserving samples within the learned data manifold to avoid visual artifacts.
- Experiments on the COCO benchmark across multiple DiT architectures demonstrate that the approach produces significantly richer diversity without sacrificing visual fidelity or semantic adherence, even in efficient "Turbo" and distilled models where traditional interventions fail.
Introduction
Modern Text-to-Image diffusion models excel at semantic alignment but often suffer from typicality bias, converging on a narrow set of visual solutions that limits their utility for creative applications. Prior attempts to restore diversity face a critical trade-off: upstream methods that modify inputs require costly optimization to incorporate structural feedback, while downstream interventions on image latents often disrupt the formed visual structure and introduce artifacts. The authors leverage the Contextual Space within Diffusion Transformers to apply on-the-fly repulsion during the forward pass, intervening in multimodal attention channels where text conditioning is enriched with emergent image structure. This approach redirects the guidance trajectory after the model is structurally informed but before the composition is fixed, achieving rich diversity with minimal computational overhead while preserving visual fidelity and semantic adherence.
Method
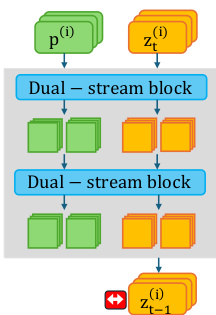
The authors leverage the inherent structure of Multimodal Diffusion Transformers (DiTs) to introduce a novel intervention strategy for generative diversity. Unlike U-Net architectures that rely on static text embeddings, DiTs facilitate a bidirectional exchange between text features fT and image features fI within Multimodal Attention (MM-Attention) blocks. As shown in the framework diagram, the standard processing flow involves dual-stream blocks where text prompts p(i) and noisy latents zt(i) are processed to generate the next state zt−1(i).
The core difficulty with existing methods lies in the timing and location of the repulsion. Upstream methods act on uninformed noise, while downstream methods act on a rigid latent manifold. The authors identify the Contextual Space, formed by the enriched text tokens f^T(l) after MM-Attention, as an effective environment for diversity interventions because it is structurally informed yet conceptually flexible.
To achieve this, the authors adopt a particle guidance framework that treats a batch of samples as interacting particles. However, unlike prior work that applies guidance to the image latents zt, as illustrated in the figure below where repulsion is applied to the output latent, the proposed method applies repulsive forces directly to the Contextual Space tokens f^T.
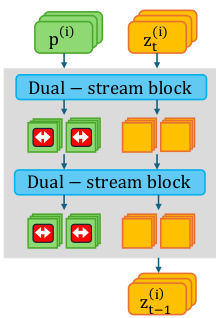
By enforcing distance between batch samples in this space, the model's high-level planning is steered before it commits to a specific visual mode. As shown in the figure below, the intervention is applied within the transformer blocks, indicated by the red arrows on the contextual stream, allowing for the manipulation of generative intent without requiring backpropagation through the model layers.
The updated state of the contextual tokens for a sample i after each iteration is given by:
f^T,i(l)′=f^T,i(l)+Mη∇f^T,i(l)Ldiv({f^T,j(l)}j=1B)where η is the overall repulsion scale and Ldiv is a diversity loss defined over the batch. To maintain diversity throughout the trajectory, this repulsion is applied across all transformer MM-blocks, specifically restricted to the first few timesteps where guidance signals are strongest.
For the diversity objective, the authors utilize the Vendi Score, which provides a principled way to measure the effective number of distinct samples in a batch. This is computed by analyzing the eigenvalues of a similarity matrix constructed from flattened contextual vectors. The Contextual Space encodes global semantic intent shared across the batch, making diversity objectives based on batch-level similarity more appropriate. As shown in the figure below, this approach allows for diverse interpolations and extrapolations while maintaining semantic alignment in the Contextual Space, preventing the semantic collapse typically induced by standard guidance.

Experiment
- Interpolation and extrapolation experiments in the Contextual Space versus VAE Latent Space demonstrate that the Contextual Space enables smooth semantic transitions and maintains high visual fidelity, whereas the Latent Space suffers from structural blurring and artifacts due to spatial misalignment.
- Qualitative evaluations across Flux-dev, SD3.5-Turbo, and SD3.5-Large architectures show that the proposed method generates diverse compositions and styles without the visual artifacts common in downstream latent interventions or the semantic drift seen in some upstream baselines.
- Quantitative analysis reveals a superior trade-off between semantic diversity and image quality, with the method achieving higher human preference and prompt alignment scores while incurring significantly lower computational overhead than optimization-based approaches.
- Ablation studies confirm that intervening in the Contextual Space is more effective than in image token spaces, as it allows for varied global compositions without the spatial rigidity that leads to local texture artifacts.
- Integration tests on image editing models validate that the approach generalizes beyond text-to-image generation, producing diverse yet coherent edits while preserving the original image integrity.