Command Palette
Search for a command to run...
CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
Xiangru Jian Shravan Nayak Kevin Qinghong Lin Aarash Feizi Kaixin Li Patrice Bechard Spandana Gella Sai Rajeswar
Abstract
Computer-use agents (CUAs) hold great promise for automating complex desktop workflows, yet progress toward general-purpose agents is bottlenecked by the scarcity of continuous, high-quality human demonstration videos. Recent work emphasizes that continuous video, not sparse screenshots, is the critical missing ingredient for scaling these agents. However, the largest existing open dataset, ScaleCUA, contains only 2 million screenshots, equating to less than 20 hours of video. To address this bottleneck, we introduce CUA-Suite, a large-scale ecosystem of expert video demonstrations and dense annotations for professional desktop computer-use agents. At its core is VideoCUA, which provides approximately 10,000 human-demonstrated tasks across 87 diverse applications with continuous 30 fps screen recordings, kinematic cursor traces, and multi-layerfed reasoning annotations, totaling approximately 55 hours and 6 million frames of expert video. Unlike sparse datasets that capture only final click coordinates, these continuous video streams preserve the full temporal dynamics of human interaction, forming a superset of information that can be losslessly transformed into the formats required by existing agent frameworks. CUA-Suite further provides two complementary resources: UI-Vision, a rigorous benchmark for evaluating grounding and planning capabilities in CUAs, and GroundCUA, a large-scale grounding dataset with 56K annotated screenshots and over 3.6 million UI element annotations. Preliminary evaluation reveals that current foundation action models struggle substantially with professional desktop applications (~60% task failure rate). Beyond evaluation, CUA-Suite's rich multimodal corpus supports emerging research directions including generalist screen parsing, continuous spatial control, video-based reward modeling, and visual world models. All data and models are publicly released.
One-sentence Summary
Researchers from ServiceNow, Mila, and other institutions introduce CUA-SUITE, a large-scale ecosystem featuring VIDEOCUA, which offers continuous 30 fps screen recordings and dense reasoning annotations to overcome the scarcity of high-quality human demonstrations for training general-purpose computer-use agents.
Key Contributions
- The paper introduces VIDEOCUA, a large-scale corpus of approximately 55 hours of continuous 30 fps expert video recordings covering 10,000 tasks across 87 desktop applications, enriched with kinematic cursor traces and multi-layered reasoning annotations to preserve full temporal dynamics.
- This work unifies continuous video demonstrations with pixel-precise UI grounding data from GROUNDCUA and a rigorous evaluation benchmark called UI-VISION into the CUA-SUITE ecosystem to provide dense, causal supervision for training and testing computer-use agents.
- All benchmarks, training data, and models associated with the CUA-SUITE framework are released as open-source resources to support emerging research directions such as generalist screen parsing, continuous spatial control, and visual world models.
Introduction
Computer-use agents aim to transform digital tools into active collaborators capable of navigating complex interfaces and executing workflows, yet current models remain brittle when handling professional desktop applications. Prior efforts to address this rely on automatically generated data that introduces noise or sparse screenshot-based datasets that lack the temporal continuity needed for learning smooth cursor movements and long-horizon planning. To overcome these limitations, the authors introduce CUA-SUITE, a comprehensive ecosystem that unifies 55 hours of high-fidelity expert video demonstrations with pixel-precise UI annotations and a rigorous evaluation benchmark. This resource provides dense, causal supervision across 87 applications, enabling the training of foundation action models that can master continuous spatial control and complex reasoning in real-world software environments.
Dataset
-
Dataset Composition and Sources
- The authors introduce CUA-SUITE, a unified ecosystem built from high-fidelity human demonstrations across 87 diverse open-source desktop applications.
- The suite comprises three complementary resources: VIDEOCUA for continuous video training, GROUNDCUA for fine-grained UI grounding, and UI-VISION for benchmarking visual perception and planning.
- Data collection involved approximately 70 professional annotators who designed and executed over 10,000 expert tasks ranging from simple actions to complex workflows.
-
Key Details for Each Subset
- VIDEOCUA: Contains approximately 55 hours of continuous 30 fps video (6 million frames) covering 10,000 tasks. It includes synchronized kinematic cursor traces and multi-layered reasoning annotations averaging 497 words per step.
- GROUNDCUA: A training corpus derived from the video data, featuring 56,000 annotated screenshots with over 3.6 million UI element annotations. It includes bounding boxes, textual labels, and functional categories for 50% of elements.
- UI-VISION: A benchmark dataset consisting of 450 high-quality task demonstrations designed to evaluate element grounding, layout grounding, and action prediction capabilities.
-
Data Usage and Processing
- The authors utilize VIDEOCUA as a high-quality expansion for training generalist Computer-Use Agents, ensuring compatibility with existing frameworks like OpenCUA and ScaleCUA.
- Multi-layered reasoning annotations are synthesized using Claude-Sonnet-4.5 to generate observation, thought chain, action description, and reflection layers for each trajectory step.
- GROUNDCUA supports a two-stage training recipe involving supervised fine-tuning (SFT) followed by reinforcement learning (RL) to train efficient vision-language models like GROUND-NEXT.
- UI-VISION serves as the primary evaluation metric to diagnose bottlenecks in visual grounding and planning, revealing that spatial reasoning remains a significant challenge for current models.
-
Cropping, Metadata, and Annotation Strategy
- Keyframes are extracted from continuous video streams specifically at moments immediately preceding state-changing user actions to capture the decision-making context.
- Annotators manually label every visible UI element in these keyframes with bounding boxes and provide textual labels or concise summaries for long text segments.
- OCR via PaddleOCR is applied to extract raw text for lengthy content like source code, supplementing manual summaries.
- The dataset preserves full temporal dynamics and intermediate cursor movements, allowing for lossless transformation into various agent training formats such as screenshot-action pairs or continuous kinematic traces.
Method
The authors present the CUA-Suite, a unified framework designed to facilitate the development of generalist computer-use agents through massive-scale software coverage and dense unified annotations. The architecture integrates a rigorous data creation pipeline with specialized modules for visual understanding and trajectory modeling.
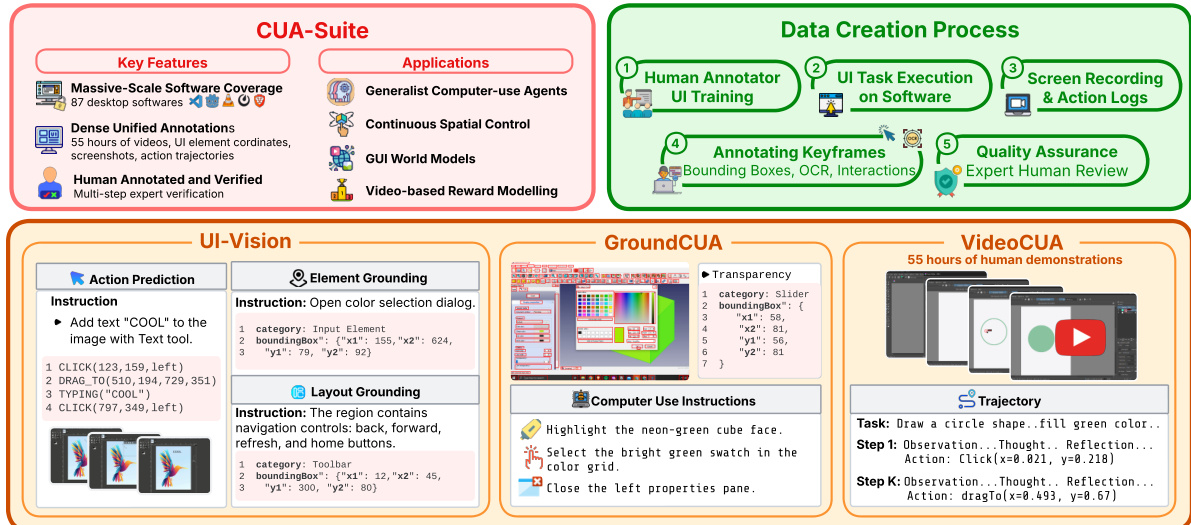
The data creation process is structured into five sequential stages. It initiates with Human Annotator UI Training to establish baseline proficiency, followed by UI Task Execution on target software. During execution, Screen Recording and Action Logs are captured. Annotators then process these logs by Annotating Keyframes with bounding boxes, OCR data, and interaction details. The pipeline concludes with Quality Assurance, where expert human review verifies the annotations.
The suite comprises three core components. UI-Vision handles Action Prediction, Element Grounding, and Layout Grounding, allowing agents to interpret interface elements and predict spatial coordinates. GroundCUA focuses on Computer Use Instructions, providing examples for tasks like highlighting specific UI regions or selecting color swatches. VideoCUA utilizes 55 hours of human demonstrations to model Trajectories, decomposing tasks into steps containing observations, thoughts, reflections, and actions.
To ensure robust evaluation and prevent information leakage regarding cursor positions, the authors employ specific preprocessing strategies. Keyframe Extraction is performed at the temporal midpoint between consecutive actions. For an action at with timestamp τt, the keyframe is captured at (τt−1+τt)/2. This ensures the cursor has not yet reached the target location, providing a fairer assessment of spatial grounding. Furthermore, the authors implement moveTo Handling by excluding moveTo steps from the evaluation and action history, as these are preparatory movements. For click actions that directly follow a moveTo, the keyframe from the moveTo step is used instead of the click step's keyframe to avoid revealing the target position.
Experiment
- Action prediction experiments on 256 tasks across 87 desktop applications validate that current foundation models struggle with complex, multi-panel interfaces, achieving modest accuracy even with model scaling from 7B to 32B parameters.
- Qualitative analysis reveals that models frequently fail to disambiguate visually similar elements in specialized creative tools and canvas-based applications, often resulting in cross-panel errors or incorrect UI region selection.
- Human evaluation confirms that while models generally identify the correct action intent, they lack precision in spatial grounding, leading to a significant gap between action correctness and coordinate accuracy.
- Application-level analysis demonstrates that performance is highly dependent on interface design, with web-like layouts yielding higher success rates compared to dense, non-standard toolbars found in professional software.
- Detailed trajectory case studies in Krita and GIMP illustrate that agents can successfully execute multi-step workflows involving tool selection, shape creation, and effect application, though they remain prone to coordinate misalignment and redundant actions during complex interactions.