Command Palette
Search for a command to run...
DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
Jaewon Min Jaeeun Lee Yeji Choi Paul Hyunbin Cho Jin Hyeon Kim Tae-Young Lee Jongsik Ahn Hwayeong Lee Seonghyun Park Seungryong Kim
Abstract
Optical flow models trained on high-quality data often degrade severely when confronted with real-world corruptions such as blur, noise, and compression artifacts. To overcome this limitation, we formulate Degradation-Aware Optical Flow, a new task targeting accurate dense correspondence estimation from real-world corrupted videos. Our key insight is that the intermediate representations of image restoration diffusion models are inherently corruption-aware but lack temporal awareness. To address this limitation, we lift the model to attend across adjacent frames via full spatio-temporal attention, and empirically demonstrate that the resulting features exhibit zero-shot correspondence capabilities. Based on this finding, we present DA-Flow, a hybrid architecture that fuses these diffusion features with convolutional features within an iterative refinement framework. DA-Flow substantially outperforms existing optical flow methods under severe degradation across multiple benchmarks.
One-sentence Summary
Researchers from KAIST AI and Hanwha Systems introduce DA-Flow, a hybrid optical flow model that lifts pretrained image restoration Diffusion features with full spatio-temporal attention to achieve robust dense correspondence estimation under severe real-world corruptions where existing methods fail.
Key Contributions
- The paper formulates Degradation-Aware Optical Flow as a new task designed to estimate accurate dense correspondences from severely corrupted videos rather than focusing solely on robustness.
- A pretrained image restoration Diffusion model is lifted to handle multiple frames by injecting inter-frame attention, creating features that encode geometric correspondence even under severe corruption.
- DA-Flow is introduced as a hybrid architecture that fuses these diffusion features with convolutional features within an iterative refinement framework, demonstrating superior performance on degraded benchmarks where existing methods fail.
Introduction
Optical flow estimation is critical for video analysis, yet existing models trained on clean data fail significantly when faced with real-world corruptions like blur, noise, and compression artifacts. Prior attempts to address this often rely on synthetic data augmentation or video diffusion backbones that entangle temporal information too early, which destroys the independent spatial structure required for precise pixel-level matching. The authors leverage intermediate features from pretrained image restoration Diffusion models, which naturally encode degradation patterns and geometric structure, and lift them to handle video by injecting cross-frame attention. They introduce DA-Flow, a hybrid architecture that fuses these degradation-aware diffusion features with standard convolutional features to achieve robust optical flow estimation under severe corruption where previous methods fail.
Method
The proposed method addresses Degradation-Aware Optical Flow by leveraging a pretrained DiT-based image restoration model. The authors first lift this image-level model to the video domain to enable temporal reasoning. In the original MM-DiT architecture, the temporal dimension is folded into the batch axis, causing the model to process each frame independently. To overcome this limitation, the authors reshape the modality streams to concatenate spatial tokens across all frames, transforming Fm∈R(BF)×T×C to F~m∈RB×(FT)×C. This modification allows for full spatio-temporal attention, where tokens can attend to all spatial locations across the entire video sequence.
As shown in the figure below:
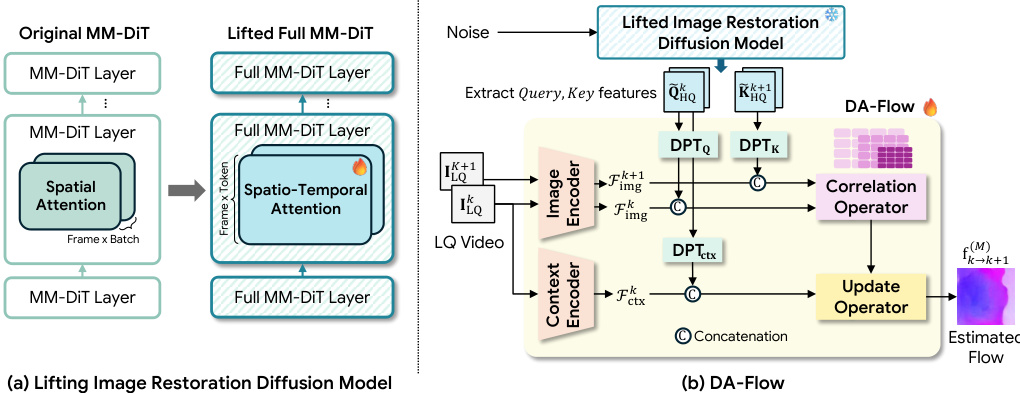
Building upon this lifted architecture, the authors introduce DA-Flow, a degradation-aware optical flow model. The pipeline retains the correlation and iterative update operators from RAFT but replaces the standard feature encoder with a hybrid system. The overall pipeline can be formulated as Mθ=U∘C∘(Up(Dϕ),E). This system combines features from the lifted diffusion model with a conventional CNN encoder. Since the diffusion features operate on a coarse grid, DPT-based heads are employed to upsample them to a resolution compatible with the CNN features. Specifically, separate heads generate query, key, and context features from the diffusion model. These upsampled features are concatenated with the CNN features to form hybrid representations. The correlation operator then constructs a cost volume from the query and key features, while the context features condition the iterative update operator to refine the flow estimate. The model is trained using a multi-scale flow loss with pseudo ground-truth labels derived from high-quality frame pairs, defined as Lflow=∑i=1MγM−ifk→k+1(i)−fk→k+1∗1.
Experiment
- Diffusion feature analysis validates that query and key features from full spatio-temporal attention layers in a finetuned lifted model exhibit superior zero-shot geometric correspondence compared to untrained baselines, with stable performance across denoising timesteps.
- Quantitative evaluations on Sintel, Spring, and TartanAir benchmarks demonstrate that DA-Flow outperforms existing methods in handling degraded inputs, achieving lower endpoint errors and significantly reduced outlier rates.
- Qualitative results confirm that the proposed method recovers sharp and coherent flow fields under severe corruption, whereas baseline approaches produce noisy artifacts around motion boundaries and fine structures.
- Ablation studies verify that the performance gains stem from the lifted diffusion features rather than simple fine-tuning of conventional networks, and that combining diffusion features with a CNN encoder and DPT-based upsampling is essential for optimal accuracy.
- Application tests in video restoration show that the accurate flow estimates enable effective temporal alignment, reducing flickering and improving structural stability across consecutive frames.