Command Palette
Search for a command to run...
Demystifing Video Reasoning
Demystifing Video Reasoning
Abstract
Recent advances in video generation have revealed an unexpected phenomenon: diffusion-based video models exhibit non-trivial reasoning capabilities. Prior work attributes this to a Chain-of-Frames (CoF) mechanism, where reasoning is assumed to unfold sequentially across video frames. In this work, we challenge this assumption and uncover a fundamentally different mechanism. We show that reasoning in video models instead primarily emerges along the diffusion denoising steps. Through qualitative analysis and targeted probing experiments, we find that models explore multiple candidate solutions in early denoising steps and progressively converge to a final answer, a process we term Chain-of-Steps (CoS). Beyond this core mechanism, we identify several emergent reasoning behaviors critical to model performance: (1) working memory, enabling persistent reference; (2) self-correction and enhancement, allowing recovery from incorrect intermediate solutions; and (3) perception before action, where early steps establish semantic grounding and later steps perform structured manipulation. During a diffusion step, we further uncover self-evolved functional specialization within Diffusion Transformers, where early layers encode dense perceptual structure, middle layers execute reasoning, and later layers consolidate latent representations. Motivated by these insights, we present a simple training-free strategy as a proof-of-concept, demonstrating how reasoning can be improved by ensembling latent trajectories from identical models with different random seeds. Overall, our work provides a systematic understanding of how reasoning emerges in video generation models, offering a foundation to guide future research in better exploiting the inherent reasoning dynamics of video models as a new substrate for intelligence.
One-sentence Summary
Researchers from SenseTime Research and Nanyang Technological University propose that video reasoning emerges via a Chain-of-Steps mechanism during diffusion denoising rather than across frames. This discovery reveals emergent behaviors like self-correction and enables a training-free strategy to enhance reasoning by ensembling latent trajectories.
Key Contributions
- The paper introduces the Chain-of-Steps (CoS) mechanism, demonstrating that reasoning in diffusion-based video models unfolds along denoising steps rather than across frames, where models explore multiple candidate solutions early and progressively converge to a final answer.
- This work identifies three emergent reasoning behaviors critical to performance: working memory for persistent reference, self-correction capabilities to recover from intermediate errors, and a perception-before-action dynamic where early steps establish semantic grounding before later steps perform manipulation.
- A training-free inference strategy is presented that improves reasoning by ensembling latent trajectories from identical models with different random seeds, with experiments showing this approach retains diverse reasoning paths and increases the likelihood of converging to correct solutions.
Introduction
Diffusion-based video models have recently demonstrated unexpected reasoning capabilities in spatiotemporally consistent environments, offering a new substrate for machine intelligence beyond static images and text. Prior research incorrectly attributed this ability to a Chain-of-Frames mechanism where reasoning unfolds sequentially across video frames, leaving the true internal dynamics largely unexplored. The authors challenge this assumption by revealing that reasoning primarily emerges along the diffusion denoising steps, a process they term Chain-of-Steps. They identify critical emergent behaviors such as working memory, self-correction, and functional layer specialization within the model architecture. Leveraging these insights, the team introduces a simple training-free strategy that ensembles latent trajectories from multiple model runs to improve reasoning performance by preserving diverse candidate solutions during generation.
Method
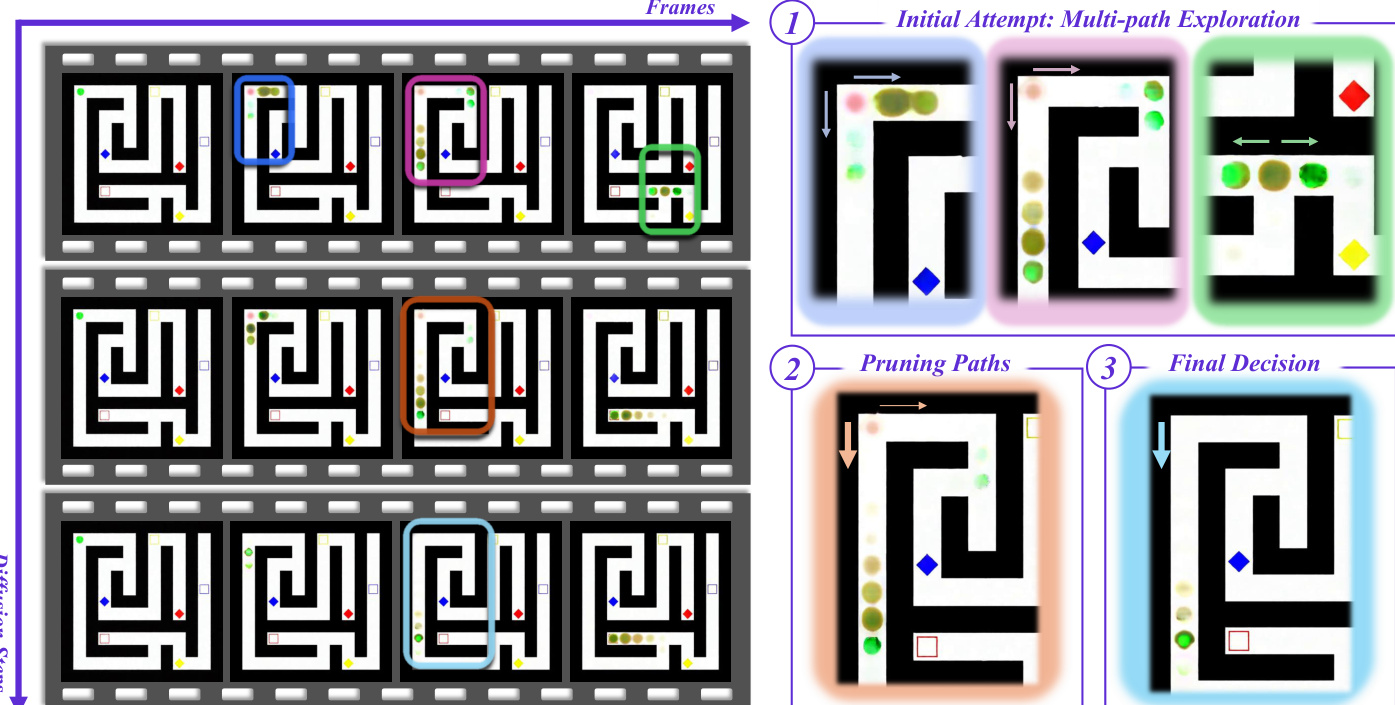
The proposed framework is built upon VBVR-Wan2.2, a video reasoning model finetuned from the Wan2.2-I2V-A14B architecture using flow matching. The core mechanism treats the diffusion denoising process as a primary axis for reasoning. The model learns a velocity field vθ(xs,s,c) conditioned on a prompt c, guiding the latent xs along a continuous transport path defined by xs=(1−s)x0+sx1, where x0 is the clean latent and x1 is noise. By estimating the clean latent at each step via x^0=xs−σs⋅vθ(xs,s,c), the system visualizes the evolution of semantic decisions. This analysis reveals that early diffusion steps function as a high-level heuristic search where the model populates the latent workspace with multiple hypotheses, while later steps prune suboptimal trajectories to converge on a solution.
Refer to the framework diagram for a visualization of this multi-path exploration and subsequent pruning in a maze-solving task.
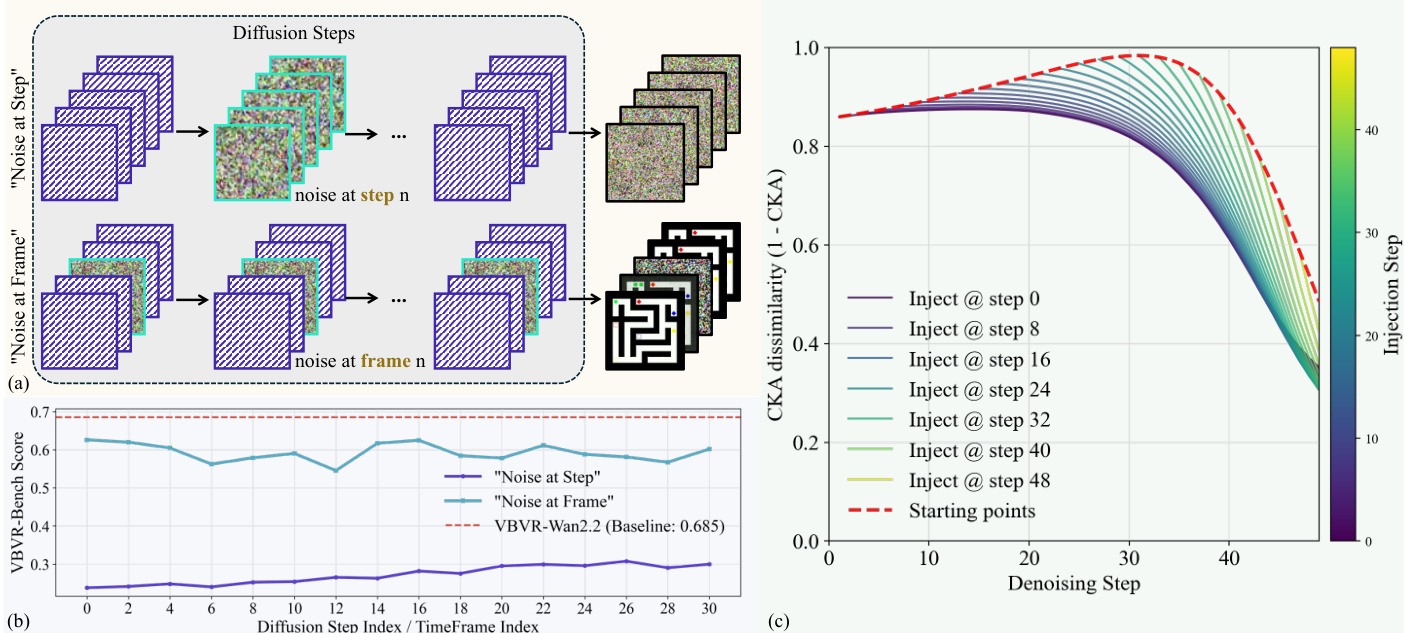
The study further analyzes the impact of noise injection strategies on the reasoning trajectory, comparing noise at specific diffusion steps versus frames.
Two distinct modes of step-wise reasoning are identified: Multi-path Exploration, where parallel possibilities are spawned, and Superposition-based Exploration, where patterns are completed through overlapping states.
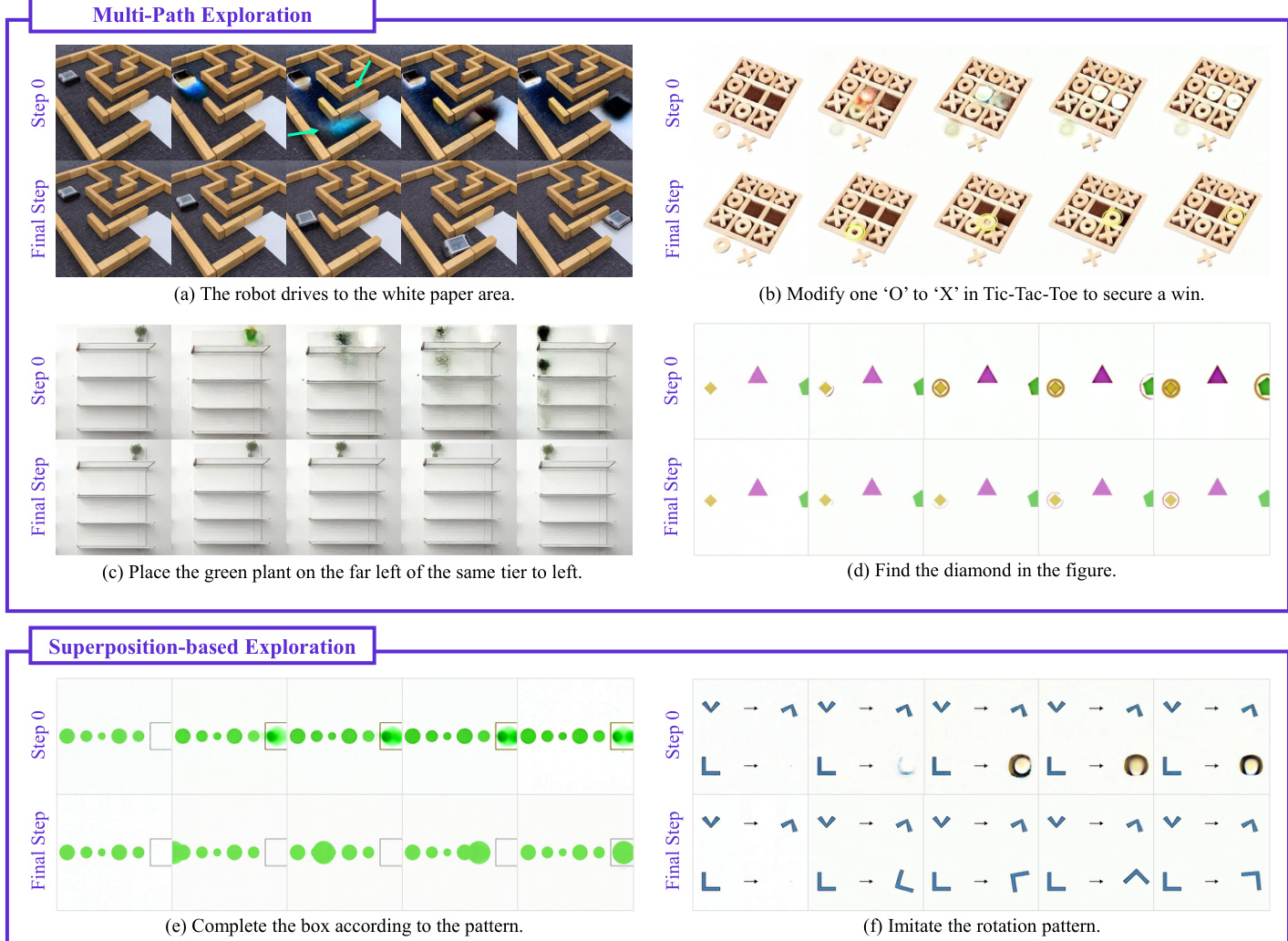
The architecture exhibits emergent reasoning behaviors critical for complex tasks, including working memory to retain essential information and self-correction to refine intermediate hypotheses.

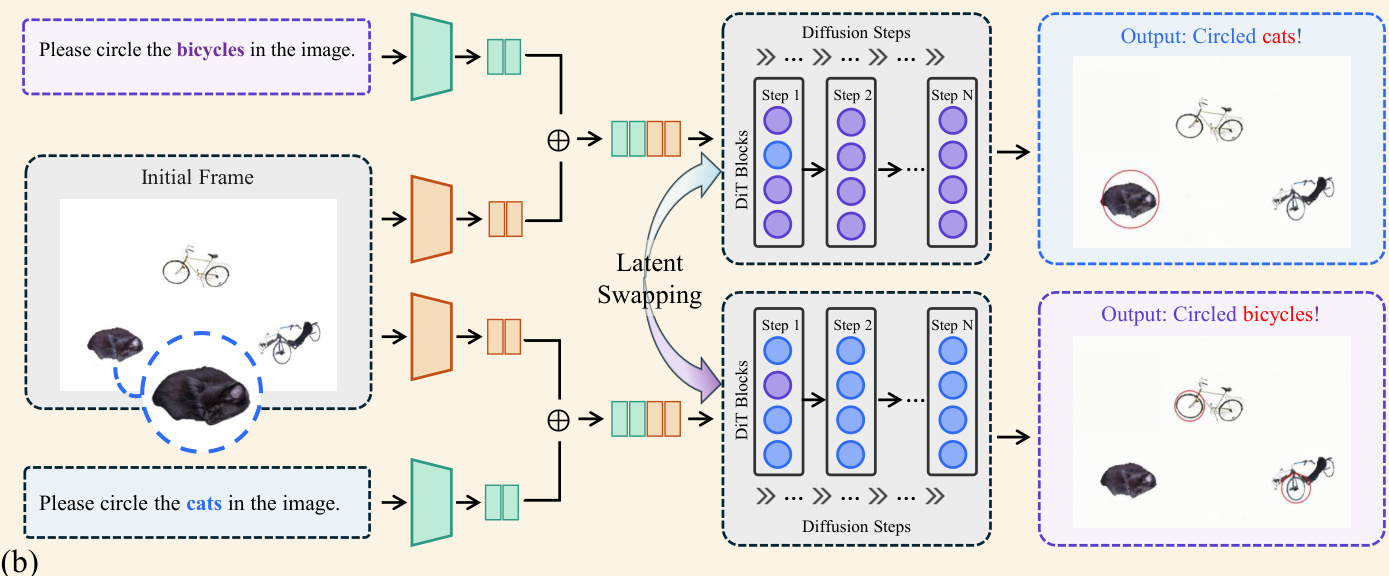
To stabilize these reasoning trajectories, a training-free ensemble strategy is implemented. This method exploits the shared probabilistic bias in the reasoning manifold by executing multiple independent forward passes with different initial noise seeds. During the critical early diffusion steps, hidden representations from the mid-layers (specifically layers 20 to 29) are extracted and spatially-temporally averaged. This latent-space ensemble filters out seed-specific noise and steers the probability distribution toward a more stable state.
Experiment
- Chain-of-Steps analysis validates that video reasoning occurs across diffusion denoising steps rather than frame-by-frame, with models exploring multiple solution paths in parallel before converging to a final outcome.
- Noise perturbation experiments confirm that disrupting specific diffusion steps severely degrades performance, whereas corrupting individual frames is more easily recovered, proving that the reasoning trajectory is highly sensitive to step-wise information flow.
- Layer-wise mechanistic analysis reveals a hierarchical processing structure where early transformer layers focus on global background context, while middle and later layers concentrate on foreground objects and execute critical logical reasoning.
- Latent swapping experiments demonstrate that middle layers encode semantically decisive information, as altering representations at these specific depths directly reverses the final inference results.
- Investigations into frame counts and model distillation show that while reasoning is not strictly frame-dependent, maintaining a minimum number of frames is essential for spatiotemporal coherence, and aggressive step compression in distilled models can collapse the latent exploration phase required for effective reasoning.
- Qualitative observations identify emergent behaviors such as working memory for preserving object states, self-correction mechanisms that refine incorrect initial hypotheses, and a "perception before action" transition where static grounding precedes dynamic motion planning.