Command Palette
Search for a command to run...
AI Can Learn Scientific Taste
AI Can Learn Scientific Taste
Abstract
Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
One-sentence Summary
Researchers from Fudan University and collaborating institutes propose RLCF, a training paradigm that leverages community feedback to enhance AI scientific taste. By deploying the SCIENTIFIC JUDGE and SCIENTIFIC THINKER models, this work shifts focus from executive capability to generating high-impact research ideas, outperforming state-of-the-art systems in predicting future scientific success.
Key Contributions
- The paper introduces Reinforcement Learning from Community Feedback (RLCF), a training paradigm that frames scientific taste learning as a preference modeling and alignment problem using large-scale community signals like citations as supervision.
- A new dataset called SciJUDGEBench is constructed containing 700K field- and time-matched pairs of high- versus low-citation paper abstracts to enable the training and evaluation of AI scientific judgment.
- Two specialized models are developed where SCIENTIFIC JUDGE outperforms state-of-the-art LLMs in predicting paper impact across unseen fields and future years, while SCIENTIFIC THINKER generates research ideas with demonstrably higher potential impact than baseline methods.
Introduction
Current efforts to build AI scientists primarily focus on executive capabilities like literature search and automated experimentation, yet they struggle to replicate the human ability to judge and propose high-impact research directions, a skill known as scientific taste. Existing approaches often rely on costly human annotations or fail to capture the broader community consensus that drives scientific progress, leaving a gap in AI's intrinsic judgment and ideation potential. To address this, the authors introduce Reinforcement Learning from Community Feedback (RLCF), a paradigm that treats scientific taste as a preference modeling problem trained on large-scale citation signals. They construct SciJUDGEBench with 700K matched paper pairs to train SCIENTIFIC JUDGE, a reward model that outperforms state-of-the-art LLMs in predicting impact, and subsequently use it to train SCIENTIFIC THINKER, a policy model that generates research ideas with significantly higher potential impact than baseline methods.
Dataset
-
Dataset Composition and Sources The authors construct SciJUDGEBENCH from 2.1 million arXiv papers published through 2024, covering Computer Science, Mathematics, Physics, and a diverse "Others" category that includes Economics, Quantitative Biology, and Statistics. The dataset transforms community feedback into pairwise supervision signals by pairing scientific ideas represented by their titles and abstracts.
-
Key Details for Each Subset
- Training Set: Contains 696,758 field- and time-matched preference pairs derived from 1.4 million unique papers. Pairs are filtered to ensure the preferred paper has an absolute citation difference of at least 8 and a relative difference of at least 30% compared to the lower-cited paper.
- Main Test Set: Comprises 728 in-domain pairs with stricter filtering requiring an absolute citation difference greater than 32 and a relative difference of at least 50% to ensure clear preference signals.
- Temporal OOD Test Set: Includes 514 pairs from papers published in 2025 to test extrapolation to future data. This set uses adaptive percentile-based thresholds within subcategories to pair high-citation papers with low-citation contemporaries while maintaining a 5-day publication window.
- Metric OOD Test Set: Consists of 611 pairs from ICLR submissions (2017–2026) where preferences are determined by peer review scores rather than citations. The authors filter out papers with low reviewer confidence or high rating variance, then pair top and bottom performers to test transferability to review-based judgment.
- BioRxiv Test Set: A smaller set of 160 biology pairs is also reported for additional evaluation.
-
Model Training and Usage The authors train the SCIENTIFIC JUDGE model on various base architectures, including the Qwen2.5-Instruct series (1.5B to 32B parameters), Qwen3 variants, and Llama-3.1-8B-Instruct. They employ Group Relative Policy Optimization (GRPO) using preference prediction correctness as a verifiable reward. The model generates a reasoning trace followed by a binary prediction (A or B) and receives a reward of 1 only if the prediction is correct.
-
Processing and Evaluation Strategies To mitigate field and time biases, all pairs are matched within the same subcategory and similar publication time windows. The authors address position bias during evaluation by presenting each pair twice with swapped orders and scoring a prediction as correct only if the model remains consistent across both orderings. Metadata construction relies on primary arXiv categories, and the "Others" field is explicitly aggregated from specific subcategories rather than treated as a residual bucket.
Method
The authors propose Reinforcement Learning from Community Feedback (RLCF), a three-stage training paradigm designed to instill scientific taste in large language models. This framework leverages large-scale community signals to supervise the learning process, progressing from data construction to preference modeling and finally to preference alignment.
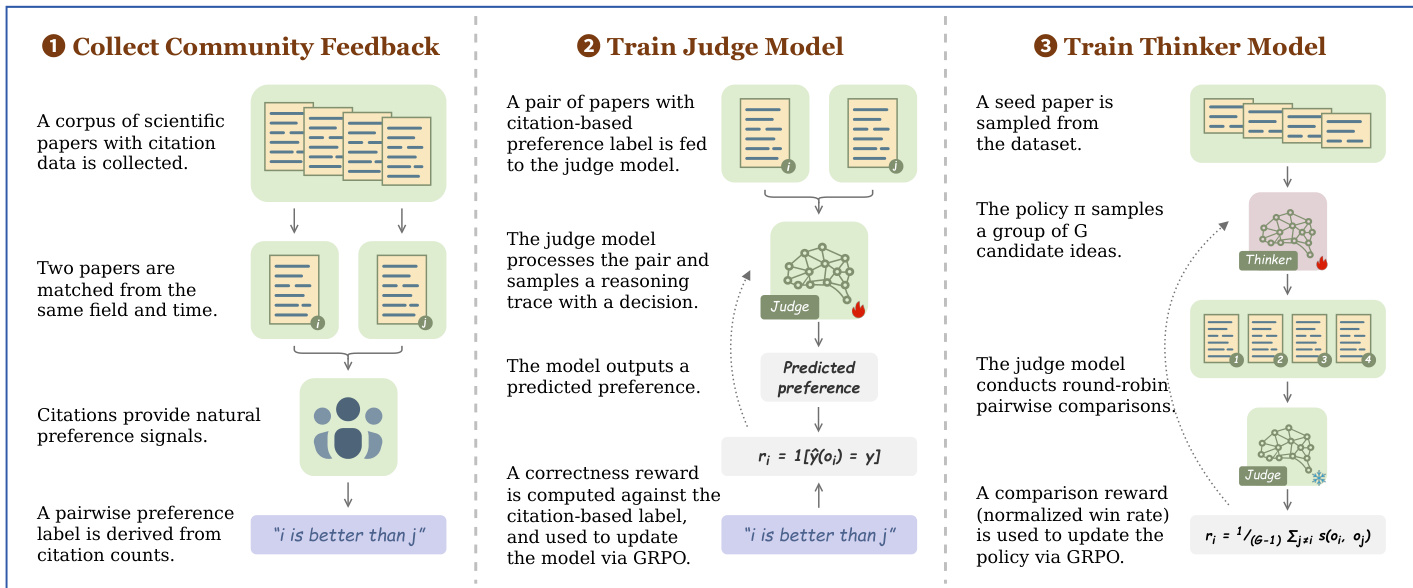
The process begins with the collection of community feedback to construct preference data. A corpus of scientific papers is gathered, and pairs are matched based on their field and publication time to ensure fair comparison. Citations serve as natural preference signals, where the paper with higher citation counts is deemed to have greater potential impact. Formally, the cumulative expected impact of a paper p is defined as I(p)=limN→∞∑t=1NE[ct(p)], where ct(p) represents the citations received in year t. This allows the derivation of pairwise preference labels, such as "paper i is better than paper j," which form the ground truth for subsequent training stages.
In the second stage, the authors train the SCIENTIFIC JUDGE model to predict the potential impact of research ideas. A pair of papers with a citation-based preference label is fed into the judge model, which processes the input and samples a reasoning trace to reach a decision. The model outputs a predicted preference, and a correctness reward is computed against the citation-based label. This reward is defined as ri=1[y^(oi)=y], where y^ is the predicted preference and y is the ground truth. This signal is used to update the judge model via Group Relative Policy Optimization (GRPO), enhancing its ability to evaluate scientific merit.
The final stage involves training the SCIENTIFIC THINKER model to generate high-impact research ideas. A seed paper is sampled from the dataset, and the policy π samples a group of G candidate ideas. The trained judge model then conducts round-robin pairwise comparisons among these candidates to evaluate their relative quality. A comparison reward, calculated as the normalized win rate, is used to update the policy. This reward is formulated as ri=G−11∑j=is(oi,oj), where s(oi,oj) represents the outcome of the comparison between idea i and idea j. This reward signal guides the THINKER model via GRPO to produce ideas that are more likely to achieve high potential impact.
Experiment
- Scaling experiments demonstrate that scientific judgement capability improves consistently with both increased training data and larger model sizes, with the 30B model surpassing proprietary baselines.
- Generalization tests confirm that models trained on computer science data effectively predict paper impact across future time periods, unseen scientific fields like mathematics and biology, and different evaluation metrics such as peer-review scores.
- Ideation training using the scientific judge as a reward model significantly enhances the quality of proposed research ideas, enabling the system to outperform base policies and compete with state-of-the-art models on future research topics.
- Case studies illustrate that larger models successfully reason about complex factors like topic generality, institutional influence, and downstream adoption, whereas smaller models occasionally rely on misleading heuristics regarding popularity or foundationality.
- Specialized training for scientific taste preserves general-purpose reasoning and knowledge capabilities, showing minimal degradation on standard benchmarks.