Command Palette
Search for a command to run...
OpenClaw-RL: Train Any Agent Simply by Talking
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang Xuyang Chen Xiaolong Jin Mengdi Wang Ling Yang
Abstract
Every agent interaction generates a next-state signal, namely the user reply, tool output, terminal or GUI state change that follows each action, yet no existing agentic RL system recovers it as a live, online learning source. We present OpenClaw-RL, a framework built on a simple observation: next-state signals are universal, and policy can learn from all of them simultaneously. Personal conversations, terminal executions, GUI interactions, SWE tasks, and tool-call traces are not separate training problems. They are all interactions that can be used to train the same policy in the same loop. Next-state signals encode two forms of information: evaluative signals, which indicate how well the action performed and are extracted as scalar rewards via a PRM judge; and directive signals, which indicate how the action should have been different and are recovered through Hindsight-Guided On-Policy Distillation (OPD). We extract textual hints from the next state, construct an enhanced teacher context, and provide token-level directional advantage supervision that is richer than any scalar reward. Due to the asynchronous design, the model serves live requests, the PRM judges ongoing interactions, and the trainer updates the policy at the same time, with zero coordination overhead between them. Applied to personal agents, OpenClaw-RL enables an agent to improve simply by being used, recovering conversational signals from user re-queries, corrections, and explicit feedback. Applied to general agents, the same infrastructure supports scalable RL across terminal, GUI, SWE, and tool-call settings, where we additionally demonstrate the utility of process rewards. Code: https://github.com/Gen-Verse/OpenClaw-RL
One-sentence Summary
The authors from OpenClaw propose OpenClaw-RL, a unified framework that transforms universal next-state signals into live online learning sources via binary reinforcement learning and Hindsight-Guided On-Policy Distillation. This approach enables continuous policy improvement for both personal and general agents across diverse scenarios like terminal, GUI, and software engineering tasks without interrupting service.
Key Contributions
- OpenClaw-RL addresses the problem of discarded next-state signals in AI agents by treating user replies, tool results, and error traces as implicit, free-form evaluations rather than mere context for future actions.
- The framework introduces a unified asynchronous architecture that recovers both scalar process rewards via a PRM judge and token-level directional supervision through Hindsight-Guided On-Policy Distillation (OPD) from live interaction data.
- Experiments demonstrate that combining these methods significantly improves performance for personal agents in conversational settings and general agents across terminal, GUI, SWE, and tool-call environments by providing dense credit assignment for long-horizon tasks.
Introduction
Deployed AI agents continuously generate valuable next-state signals, such as user replies or test results, yet current systems discard this data by treating it only as context for future actions rather than a source of live learning. Existing reinforcement learning approaches typically rely on offline batch data, scalar outcome rewards that lack step-level granularity, or pre-curated feedback pairs, which prevents continuous optimization during real-world deployment. The authors introduce OpenClaw-RL, a unified asynchronous infrastructure that recovers these implicit signals to enable online training for both personal and general agents. Their framework leverages Process Reward Models to extract dense step-wise rewards from live interactions and employs Hindsight-Guided On-Policy Distillation to convert textual error traces into directional token-level supervision without requiring external annotators.
Dataset
-
Dataset Composition and Sources: The authors curate a multi-scenario dataset to support terminal, GUI, software engineering (SWE), and tool-call agents by combining four distinct sources: SETA RL data, OSWorld-Verified, SWE-Bench-Verified, and DAPO RL data.
-
Key Details for Each Subset:
- Terminal Agents: Trained on SETA RL data to leverage efficient text-based interfaces.
- GUI Agents: Trained on OSWorld-Verified data to handle visual interfaces and pointer interactions, with evaluation restricted to the training set after excluding Chrome and multi-app tasks.
- SWE Agents: Trained on SWE-Bench-Verified data to utilize rich executable feedback like tests and diffs.
- Tool-Call Agents: Trained on DAPO RL data to enhance reasoning and factual accuracy, with evaluation performed on the AIME 2024 mathematics competition dataset.
-
Model Usage and Training Strategy: The authors apply specific model configurations to each subset, using Qwen3-8B for terminal tasks, Qwen3VL-8B-Thinking for GUI tasks, Qwen3-32B for SWE tasks, and Qwen3-4B-SFT for tool-call tasks. Performance for terminal and SWE agents is measured by averaging rollout-task accuracy over a window of reinforcement learning steps.
-
Processing and Metadata Construction: For GUI agent evaluation, the authors construct a strict step-level feedback prompt that combines text instructions, historical actions, and base64-encoded images of the environment state before and after an action. This prompt instructs the evaluator to assign a binary score of +1 or -1 based on whether the action is relevant, executable, and results in concrete progress toward the objective.
Method
The OpenClaw-RL framework is built on the observation that next-state signals, such as user replies or tool outputs, encode both evaluative and directive information about an agent's actions. The system unifies the training of personal and general agents through a fully asynchronous pipeline that decouples policy serving, environment hosting, reward judging, and policy training. Refer to the framework diagram for the overall architecture. The infrastructure connects Personal Agents and General Agents to Environment Servers, which handle confidential API keys and large-scale environments respectively. These servers feed data into an RL Server comprising a Training Engine (Megatron), a Policy Server (SGLang), and a PRM Server. This decoupled design ensures that the model can serve live requests while the PRM judges interactions and the trainer updates weights without blocking dependencies.
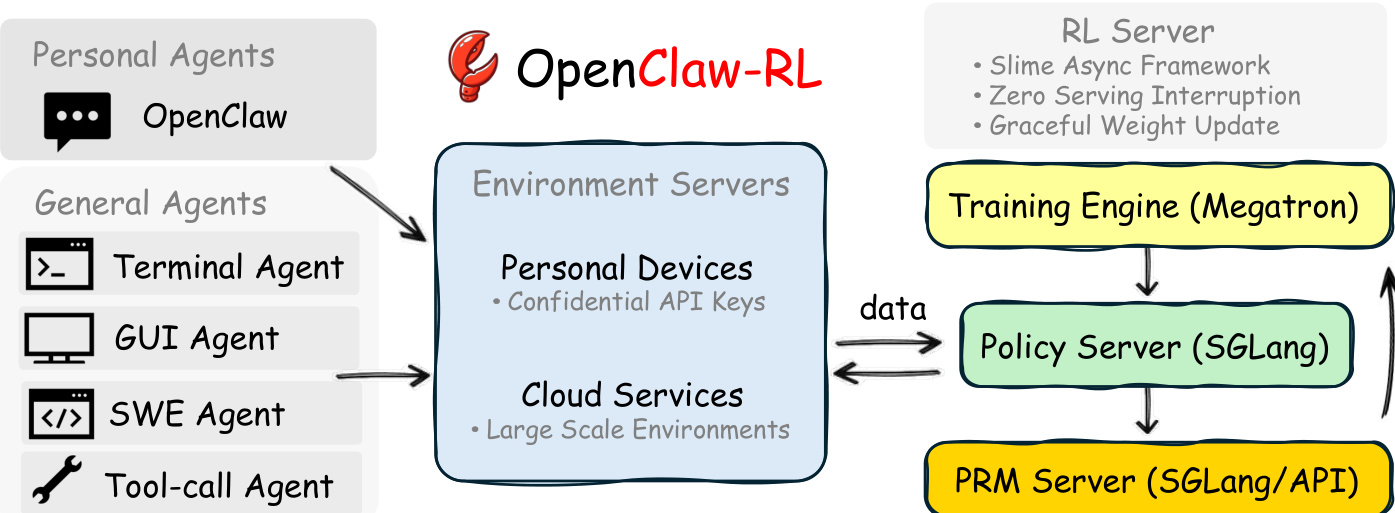
The learning process leverages next-state signals through two complementary methods. As shown in the figure below, the framework supports Binary RL for evaluative signals and On-policy Distillation for directive signals. In the Binary RL approach, a PRM judge evaluates the quality of an action at given the next state st+1, producing a scalar reward r∈{+1,−1,0}. This reward serves as the advantage At in a standard PPO-style clipped surrogate objective.
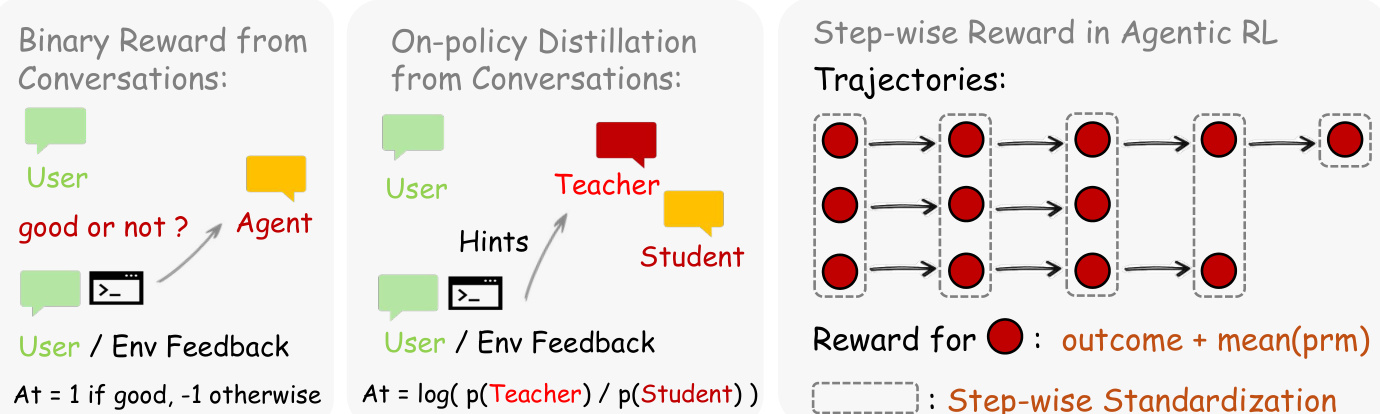
For more granular improvement, Hindsight-Guided On-Policy Distillation (OPD) extracts textual hints from the next state to construct an enhanced teacher context. The advantage is calculated as the per-token log-probability gap between the teacher model, which conditions on the hint, and the student model: At=logπteacher(at∣senhanced)−logπθ(at∣st) This provides directional guidance at the token level, indicating which tokens should be upweighted or downweighted. For general agents, the system further integrates step-wise rewards with outcome rewards, utilizing step-wise standardization to handle long-horizon trajectories. The authors combine both methods by weighting their respective advantages, allowing the policy to benefit from broad coverage via scalar rewards and high-resolution corrections via distillation.
Experiment
- The personal agent track validates that conversational next-state signals enable continuous personalization, with a combined optimization method outperforming binary reinforcement learning and on-policy distillation to help agents adopt natural writing styles and provide friendlier feedback after minimal interactions.
- The general agent track demonstrates that the unified infrastructure supports scalable reinforcement learning across terminal, GUI, software engineering, and tool-call scenarios through large-scale environment parallelization.
- Experiments confirm that integrating process reward models with outcome rewards yields stronger optimization for long-horizon tasks compared to outcome-only approaches, despite the additional resource requirements.