Command Palette
Search for a command to run...
Where Vision Becomes Text: Locating the OCR Routing Bottleneck in Vision-Language Models
Where Vision Becomes Text: Locating the OCR Routing Bottleneck in Vision-Language Models
Jonathan Steinberg Oren Gal
Abstract
Vision-language models (VLMs) can read text from images, but where does this optical character recognition (OCR) information enter the language processing stream? We investigate the OCR routing mechanism across three architecture families (Qwen3-VL, Phi-4, InternVL3.5) using causal interventions on five dense models in the 2B–8B parameter regime. By computing activation differences between original images and text-inpainted versions, we identify architecture-specific OCR depth bands whose dominant location depends on the vision-language integration strategy: DeepStack models (Qwen) show peak sensitivity at mid-depth (~50%) for scene text, while single-stage projection models (Phi-4, InternVL) peak at early layers (6–25%), though the exact layer of maximum effect varies across datasets. The OCR signal is remarkably low-dimensional: PC1 captures 72.9% of variance. Crucially, Principal Component Analysis (PCA) directions learned on one dataset transfer to others, demonstrating shared text-processing pathways. Surprisingly, in models with modular OCR circuits (notably Qwen3-VL-4B), OCR removal can improve counting performance (up to +6.9pp), suggesting OCR interferes with other visual processing in sufficiently modular architectures within this model-size regime.
One-sentence Summary
By applying causal interventions and principal component analysis to Qwen3-VL, Phi-4, and InternVL3.5, the authors identify architecture-specific OCR routing depth bands, revealing that single-stage projection models process text signals at earlier layers than DeepStack architectures and that modular OCR circuits can occasionally interfere with visual counting performance.
Key Contributions
- The paper identifies architecture-specific OCR routing mechanisms by using causal interventions and activation patching to locate depth bands where text information is processed in 2B–8B parameter vision-language models.
- This research demonstrates that OCR signals are concentrated in a low-dimensional subspace, with the primary component capturing 72.9% of the variance and showing transferable properties across different datasets.
- The study shows that surgically removing this OCR-specific subspace can improve performance in other visual tasks, such as counting, which suggests a capacity competition between OCR and other visual processing functions in modular architectures.
Introduction
Vision-language models (VLMs) rely on optical character recognition (OCR) to interpret text within images, a capability essential for tasks ranging from document understanding to autonomous web browsing. While these models demonstrate strong text-reading performance, the internal routing mechanisms that transition visual text into the language processing stream remain poorly understood. This lack of clarity poses significant safety risks, as adversarial text embedded in images can be used to hijack model behavior through typographic prompt injections. The authors leverage causal interventions and Principal Component Analysis (PCA) to identify architecture-specific depth bands where OCR information is processed. They demonstrate that the OCR signal is remarkably low-dimensional and that its processing pathways are consistent across different datasets. Furthermore, the authors show that surgically removing this OCR subspace can actually improve performance on non-textual tasks like counting, suggesting that OCR circuits can interfere with other visual reasoning processes in certain model architectures.
Dataset
The authors utilize several datasets to evaluate the impact of OCR interventions on visual models:
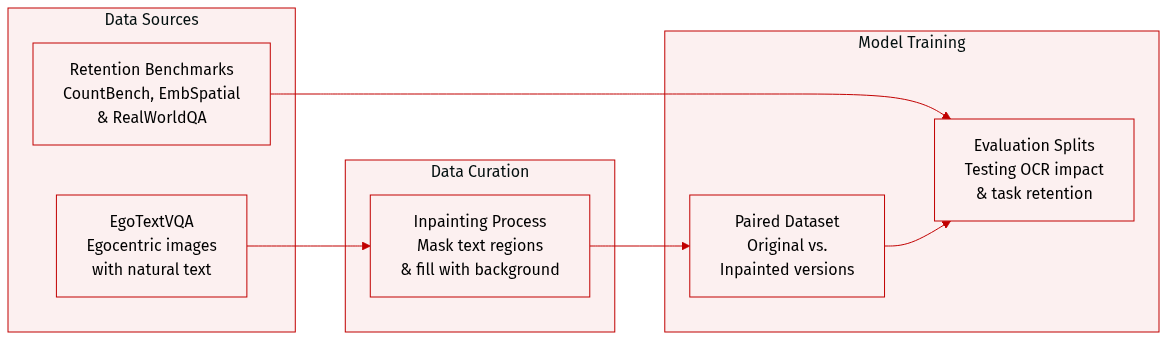
- EgoTextVQA (Primary Dataset): The authors use this egocentric dataset, which features images containing natural text such as signs, labels, and screens. To study how text affects model activations, they create a paired dataset consisting of the original image and an inpainted version where the text has been removed.
- Inpainting Processing: To generate the inpainted versions, the authors extract text region bounding boxes from existing annotations and expand them by 10 percent to ensure total coverage. They then apply a standard inpainting model to fill these masked regions. The quality of this process was verified through manual spot-checks of 50 random samples.
- Retention Benchmarks: To measure collateral damage to non-OCR tasks, the authors employ three specific benchmarks using complete datasets and deterministic greedy decoding:
- CountBench: A benchmark used to measure object counting abilities.
- EmbSpatial: A benchmark designed to test spatial reasoning and understanding for embodied tasks.
- RealWorldQA: A general visual question answering benchmark based on real-world images.
Method
To investigate how vision-language integration affects OCR routing, the authors examine three distinct architectural families of Vision-Language Models (VLMs). The first category consists of DeepStack models, including Qwen3-VL-4B-Instruct, Qwen3-VL-2B-Instruct, and Qwen3-VL-8B-Instruct. These models utilize a progressive injection strategy where visual features are introduced into multiple layers of the Large Language Model (LLM) backbone. In contrast, the second category comprises single-stage models, such as Phi-4-multimodal-instruct and InternVL3.5-4B. These architectures inject all visual tokens exclusively at the input layer. This variation in integration strategy allows for the identification of how the OCR bottleneck is distributed across the model layers.
As shown in the figure below:
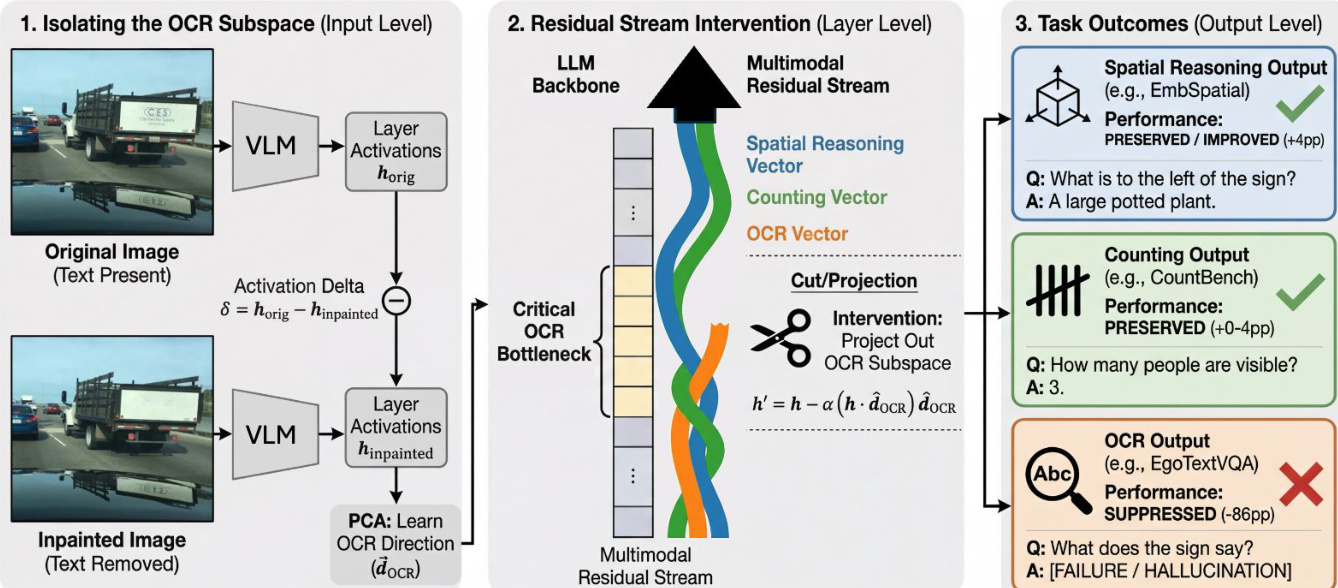
The authors employ a PCA-based subspace removal method to isolate the components of the residual stream responsible for text processing. For each layer ℓ, the activation difference is computed across a held-out training split using the formula: Δhℓ=hℓoriginal−hℓinpainted where hℓoriginal represents the activations from images containing text and hℓinpainted represents activations from images where text has been removed. By performing Principal Component Analysis (PCA) on these differences, the authors identify principal components that capture the specific changes occurring when text is present.
During inference, the authors intervene by projecting out the top N principal components from the residual stream. The intervened activation hℓint is calculated as: \nhℓint=hℓ−α∑i=1N(hℓ⋅pci)pci In this equation, hℓ is the residual-stream activation at layer ℓ, pci is the i-th principal component, N is the number of components removed, and α is a scaling factor for intervention strength. The authors set α=1 to achieve full projection removal. These interventions are implemented via forward hooks on the transformer layer outputs, specifically targeting the post-MLP residual stream.
Complementing the subspace removal, the authors also perform head ablation to identify attention heads specialized for OCR. They define a selectivity ratio for each attention head, calculated as the ratio of attention weights assigned to OCR regions versus background regions. Heads with a ratio greater than 1.0 are considered to preferentially attend to text. The authors rank all 720 heads based on this selectivity and ablate the top N heads by zeroing their output projections during both the prefill and decode stages to assess their causal importance to text reading tasks.
Experiment
The researchers evaluated five vision-language models across multiple OCR and visual reasoning benchmarks to identify and intervene upon text-processing bottlenecks. The experiments demonstrate that OCR signals are concentrated in low-dimensional subspaces and that the location of these bottlenecks is determined by model architecture, with DeepStack models showing mid-depth sensitivity and single-stage models showing early-layer sensitivity. Results indicate that targeted OCR removal can actually improve performance on certain visual tasks like object counting by reducing representational interference, particularly in larger models that exhibit more modular circuit organization.
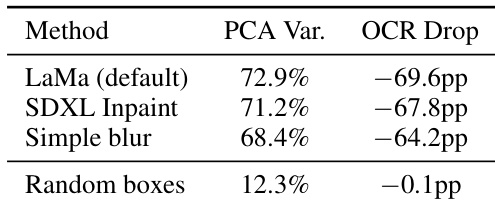
The authors conduct control experiments to ensure that the observed OCR suppression stems from actual text removal rather than artifacts introduced by inpainting. They compare three different inpainting methods against a random box baseline to validate the specificity of their PCA-based intervention. Different inpainting techniques yield similar levels of explained variance and OCR suppression The random box control shows minimal impact on both variance and OCR accuracy Results confirm that the identified signals are specific to text removal rather than general image perturbations
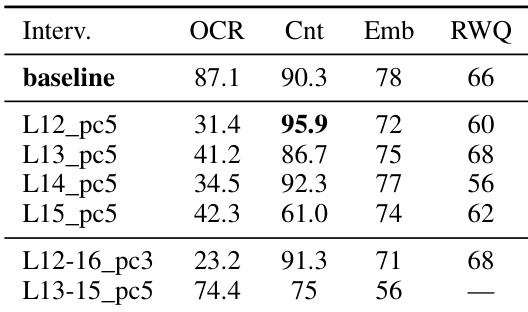
The authors evaluate different layer-wise interventions on the Qwen3-VL-2B model to observe the impact on OCR and visual reasoning tasks. Results show that interventions in the mid-network range can suppress OCR while simultaneously improving performance on certain visual tasks like counting. Interventions at specific mid-layers achieve significant OCR suppression while increasing counting accuracy Certain interventions provide a trade-off where counting improves but spatial reasoning and general visual QA scores decrease Multi-layer interventions can effectively reduce OCR with varying impacts on downstream visual reasoning tasks
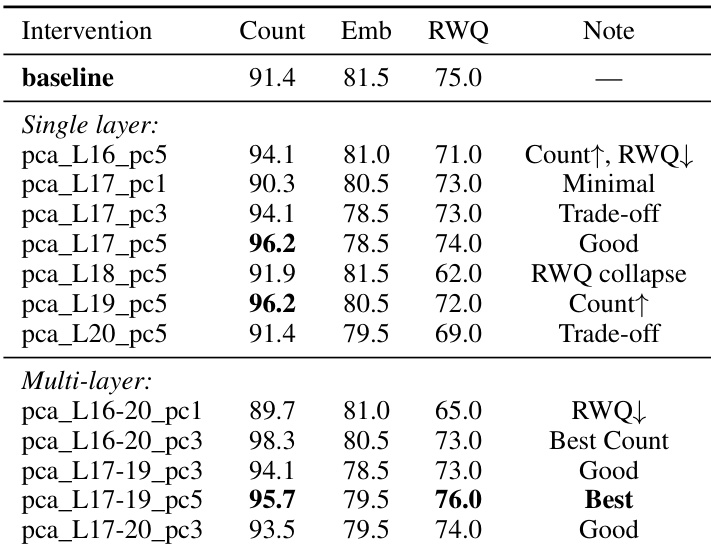
The authors identify the most OCR-selective attention heads by ranking them based on their selectivity ratio. These heads are primarily concentrated within specific mid-network layers. The most selective heads are located within layers 16, 18, 8, 12, and 17 Selectivity ratios for the top ranked heads range from approximately 1.10 to 1.41 A significant cluster of highly selective heads is found in the mid-layer range between layer 16 and layer 20
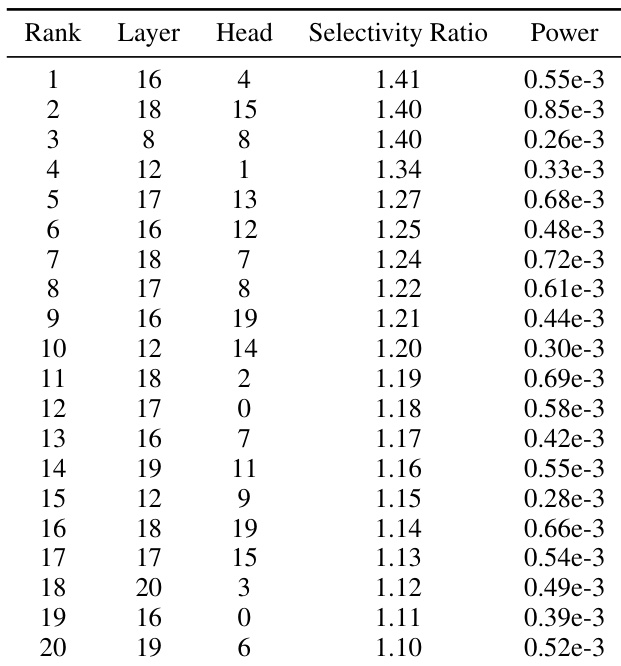
The authors evaluate how targeted OCR interventions affect various visual reasoning tasks across different model architectures. Results show that while some models achieve improved performance in counting tasks with minimal impact on other metrics, others experience significant degradation in spatial reasoning and general visual QA. Qwen3-VL-4B achieves a favorable trade-off by improving counting performance with only minor impacts on spatial reasoning and general visual QA. Smaller models like Qwen3-VL-2B and Phi-4 show gains in counting but suffer from notable declines in spatial reasoning and general visual tasks. InternVL exhibits a complete degradation in all measured metrics when interventions are applied to its early-layer bottleneck.
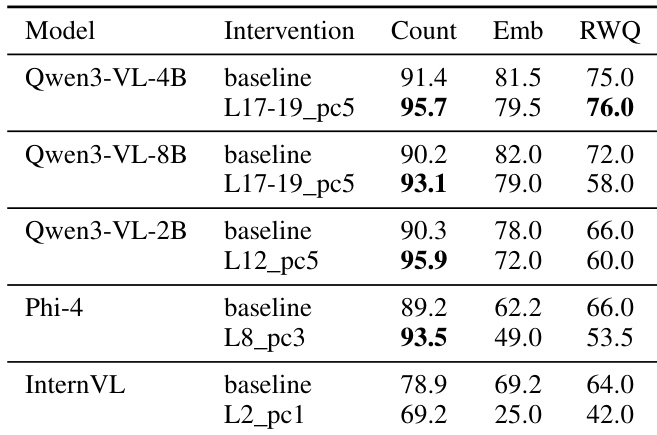
The authors evaluate different PCA-based interventions on the Qwen3-VL-4B model to identify optimal layers for OCR suppression. Results show that targeting specific mid-layer components can improve object counting performance while maintaining or slightly adjusting other visual reasoning capabilities. Multi-layer interventions at layers 17 through 19 achieve a favorable balance by improving counting and general visual QA with minimal impact on spatial reasoning. Single-layer interventions at layer 18 lead to a significant collapse in general visual QA performance. Certain mid-layer interventions, such as pca_L17_pc5, demonstrate effective trade-offs by increasing counting accuracy while preserving most other metrics.
The authors conduct control experiments and layer-wise interventions to validate that their PCA-based method specifically suppresses OCR without being caused by general image perturbations. By identifying highly selective attention heads in the mid-network layers, they demonstrate that targeted interventions can suppress text recognition while potentially improving certain visual tasks like counting. The effectiveness of these interventions varies across architectures, with some models achieving a favorable balance between OCR suppression and reasoning capabilities while others experience performance trade-offs.