Command Palette
Search for a command to run...
Generated Reality: Human-centric World Simulation using Interactive Video Generation with Hand and Camera Control
Generated Reality: Human-centric World Simulation using Interactive Video Generation with Hand and Camera Control
Linxi Xie Lisong C. Sun Ashley Neall Tong Wu Shengqu Cai Gordon Wetzstein
Abstract
Extended reality (XR) demands generative models that respond to users' tracked real-world motion, yet current video world models accept only coarse control signals such as text or keyboard input, limiting their utility for embodied interaction. We introduce a human-centric video world model that is conditioned on both tracked head pose and joint-level hand poses. For this purpose, we evaluate existing diffusion transformer conditioning strategies and propose an effective mechanism for 3D head and hand control, enabling dexterous hand--object interactions. We train a bidirectional video diffusion model teacher using this strategy and distill it into a causal, interactive system that generates egocentric virtual environments. We evaluate this generated reality system with human subjects and demonstrate improved task performance as well as a significantly higher level of perceived amount of control over the performed actions compared with relevant baselines.
One-sentence Summary
Researchers from Stanford, NYU Shanghai, and UNC Chapel Hill propose Generated Reality, a human-centric video world model using hybrid 2D-3D conditioning for head and hand poses, enabling dexterous interactions via distilled autoregressive generation—outperforming baselines in control and immersion for XR applications.
Key Contributions
- We address the limitation of current video world models in XR by introducing a human-centric diffusion model conditioned on tracked 3D head and joint-level hand poses, enabling dexterous hand-object interactions through a novel hybrid 2D-3D conditioning strategy.
- We train a bidirectional video diffusion teacher model and distill it into a causal, autoregressive system that runs at 11 FPS with 1.4s latency on an H100, supporting real-time ego-centric environment generation without prebuilt 3D assets.
- Human subject evaluations show our system improves task performance and significantly increases perceived user control compared to baselines, validating its effectiveness for embodied interaction in immersive applications.
Introduction
The authors leverage recent advances in video diffusion models to build a human-centric world simulator for extended reality (XR), where users interact via tracked head and hand poses rather than coarse inputs like text or keyboard commands. Prior models lack fine-grained control over dexterous hand-object interactions, limiting their use in immersive applications that demand embodied interactivity. To address this, the authors conduct a systematic comparison of hand pose conditioning strategies and introduce a hybrid 2D-3D approach that combines rendered hand skeletons with 3D joint parameters, yielding superior fidelity and temporal coherence. They then distill a bidirectional teacher model into a causal, autoregressive system running at interactive frame rates, enabling real-time, zero-shot generation of diverse virtual environments with measurable gains in user task performance and perceived control.
Method
The authors leverage a latent video diffusion transformer architecture, extending the Wan family of models, to enable conditional video generation driven by tracked head and hand poses. The core framework operates in the latent space, where a 3D variational autoencoder (E,D) compresses input video or image sequences into compact latents. The diffusion process follows a rectified flow formulation, where noise is linearly interpolated with the initial latent z0 over time t∈[0,1], defined as:
zt=(1−t)z0+tϵ,ϵ∼N(0,I)The denoising model, parameterized by Θ, learns a velocity field vΘ(zt,t) to reverse this process. Training employs conditional flow matching with the objective:
LCFM=Et,z0,ϵ[vΘ(zt,t)−ut(z0∣ϵ)22]where ut is the analytically derived target velocity. At inference, the model autoregressively generates a sequence of latent frames, starting from either an encoded image zimg=E(I0) (I2V) or a text embedding ztext=T(p) (T2V), and reconstructs the final video via V^=D(z(1),…,z(F)).
To incorporate hand pose conditioning, the authors introduce a hybrid 2D-3D strategy. The 2D component uses a ControlNet-style skeleton video, rendered from the egocentric viewpoint, which provides spatial grounding but lacks depth information. The 3D component employs hand pose parameters (HPP) derived from a parametric hand model—specifically, 20 joint angles per hand plus 6-DoF wrist transformation—which are processed through a lightweight 1D convolutional motion encoder Econv. These HPP embeddings are injected via element-wise token addition after patchification, as shown in the conditioning pipeline.
For joint head and hand control, the system integrates 6-DoF camera poses from HMD sensors. These poses are transformed into per-frame Plücker embeddings P∈Rb×f×6×h×w and encoded via Ecam to match the token dimensionality. The final conditioning representation is formed by summing three components: the patchified latent from the raw and skeleton video, the HPP embeddings, and the camera embeddings:
x=patchify([ zr, zc ]channel−dim)+Econv(H)+Ecam(P)This fused representation is then fed into the DiT blocks, which include self-attention, cross-attention, and feed-forward layers. The model is trained under a unified conditioning schema to ensure coherent alignment between hand motion and viewpoint changes.
Refer to the framework diagram for a visual overview of the conditioning pipeline, including the integration of camera pose, hand pose parameters, and skeleton video into the DiT backbone.
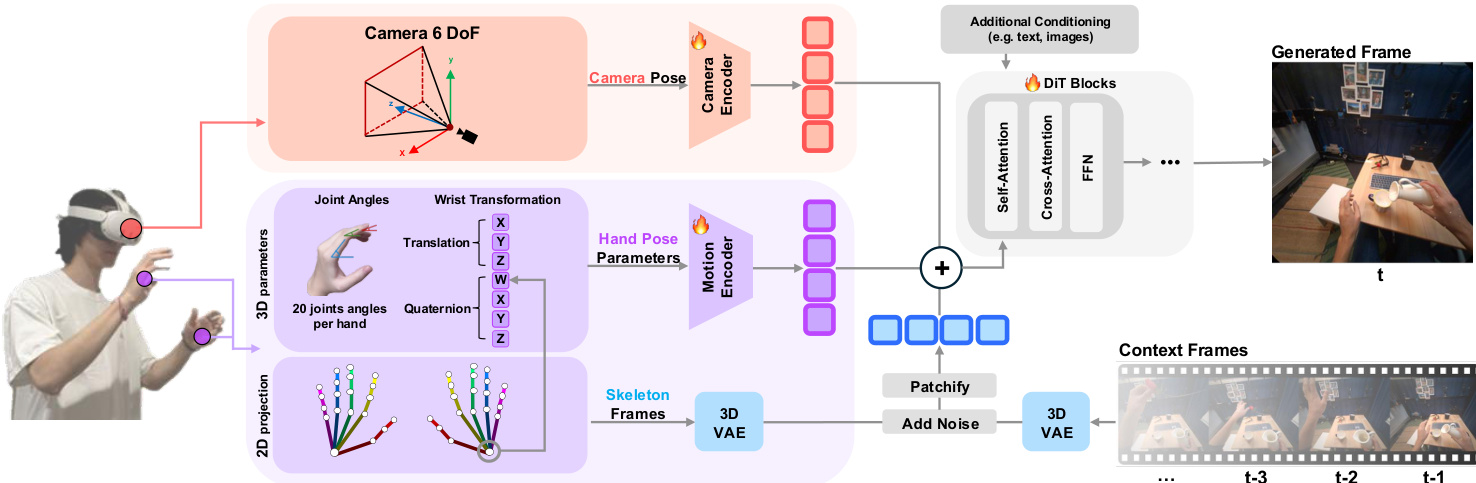
To stabilize training, the authors adopt an iterative encoder training strategy: the camera and HPP encoders are first trained independently, with the camera encoder initialized from a pretrained FUN model, and then jointly fine-tuned. For deployment, the model is distilled into a causal autoregressive variant to support real-time interaction. The system streams hand and head pose data from a Meta Quest 3 to a server hosting the distilled model, generating 12-frame video chunks at 11 FPS with minimal added latency. The generated output is streamed back to the headset, enabling closed-loop interaction where user movements directly influence the rendered scene.
As shown in the figure below, the system accepts either a text prompt or an initial image, along with real-time head and hand pose inputs, to generate dynamic, interactive video sequences that reflect user intent and viewpoint.

Experiment
- Hybrid hand-pose conditioning (combining 2D skeleton and 3D HPP) outperforms all baselines in hand accuracy, especially under occlusion, while maintaining competitive video quality.
- Joint hand-camera conditioning enables coordinated control of both modalities, surpassing single-modality models in overall performance and visual coherence.
- Evaluations on GigaHands confirm scalability: hybrid conditioning consistently improves hand accuracy metrics across larger, more complex data.
- Qualitative results show the hybrid model reconstructs anatomically faithful hands near frame boundaries where 2D-only methods fail.
- User studies validate improved perceived controllability and task completion over baselines, despite current system latency.
- Text-to-video generation demonstrates generalization to unseen, dynamic scenes beyond the training domain.
- Limitations include challenges with long-range object dependencies and latency, though these are not inherent to the method and can be optimized.
The authors evaluate hand-pose conditioning strategies using a hybrid approach that combines 2D skeleton projections and 3D hand pose parameters, achieving the lowest error across all metrics compared to baseline and single-modality methods. Results show the hybrid method significantly improves 3D hand shape and joint position accuracy while reducing pixel-space landmark error, indicating more anatomically faithful and spatially consistent reconstructions. This improvement holds across datasets, including larger and more complex ones like GigaHands, demonstrating scalability and robustness.
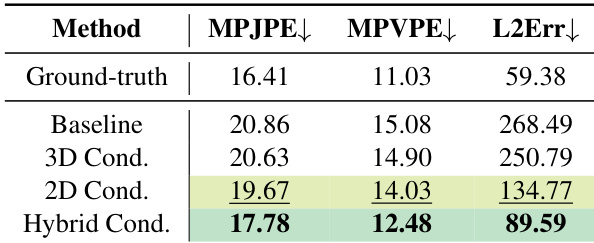
The authors evaluate the inherent accuracy limits of their hand and camera pose estimation pipeline using ground truth annotations from the HOT3D dataset, reporting baseline errors for 3D hand joint and vertex positions, 2D landmark alignment, and camera trajectory estimation. These values represent the lower bounds achievable under their evaluation protocol, indicating the best possible performance given the annotation and reconstruction methods used. Results from their hybrid conditioning approach approach these limits, suggesting high fidelity in reconstructing hand and camera dynamics.

The authors evaluate multiple hand-pose conditioning strategies on a video generation model and find that combining 2D skeleton video with 3D hand pose parameters yields the best hand pose accuracy while maintaining competitive video quality. Results show this hybrid approach outperforms both standalone 3D parameter injection and 2D image-based conditioning, particularly in preserving anatomical fidelity and handling boundary occlusions. The method also approaches the estimated lower bound of hand pose estimation error, indicating strong alignment with ground truth annotations.
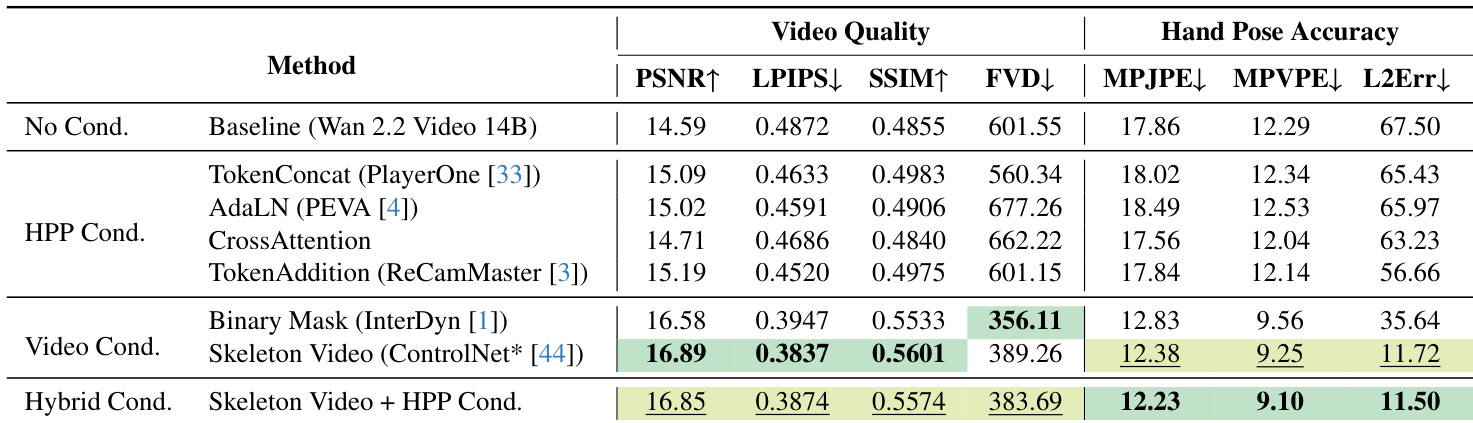
The authors evaluate joint hand and camera conditioning against separate baselines, finding that their JointCtrl method achieves the best overall video quality while maintaining competitive accuracy for both hand and camera pose control. Although camera-only conditioning yields the lowest camera pose errors, it fails to preserve hand alignment, whereas hand-only conditioning sacrifices camera control. JointCtrl effectively balances both modalities, enabling coherent coordination between hand motion and camera dynamics without significant degradation in visual fidelity.
