Command Palette
Search for a command to run...
Unified Latents (UL): How to train your latents
Unified Latents (UL): How to train your latents
Jonathan Heek Emiel Hoogeboom Thomas Mensink Tim Salimans
Abstract
We present Unified Latents (UL), a framework for learning latent representations that are jointly regularized by a diffusion prior and decoded by a diffusion model. By linking the encoder's output noise to the prior's minimum noise level, we obtain a simple training objective that provides a tight upper bound on the latent bitrate. On ImageNet-512, our approach achieves competitive FID of 1.4, with high reconstruction quality (PSNR) while requiring fewer training FLOPs than models trained on Stable Diffusion latents. On Kinetics-600, we set a new state-of-the-art FVD of 1.3.
One-sentence Summary
Google DeepMind Amsterdam researchers propose Unified Latents (UL), a diffusion-based framework that jointly trains encoder, prior, and decoder to optimize latent representations for generation, achieving state-of-the-art FID and FVD while offering interpretable bitrate control via simple hyperparameters.
Key Contributions
- Unified Latents introduces a diffusion-based framework that jointly trains an encoder, diffusion prior, and diffusion decoder, using a deterministic encoder with fixed noise to simplify training and provide a tight upper bound on latent bitrate.
- The method aligns the prior’s minimum noise level with the encoder’s output noise, reducing the KL term to a weighted MSE and enabling interpretable control over the reconstruction-modeling tradeoff via simple hyperparameters.
- Evaluated on ImageNet-512 and Kinetics-600, UL achieves competitive FID (1.4) and state-of-the-art FVD (1.3) with high PSNR and fewer training FLOPs than Stable Diffusion latents, demonstrating improved efficiency and generation quality.
Introduction
The authors leverage a unified framework called Unified Latents (UL) to train latent representations that are simultaneously encoded, regularized by a diffusion prior, and decoded by a diffusion model. This approach matters because efficient, high-quality latents are critical for scaling diffusion models to high-resolution image and video generation, yet prior methods struggle to balance information density with reconstruction fidelity—often sacrificing PSNR for better FID or requiring manual tuning of regularization weights. Existing techniques either rely on fixed bottlenecks, unstable entropy terms, or pretrained semantic encoders that lose high-frequency detail. The authors’ main contribution is a simple, stable training objective that ties the encoder’s noise level to the diffusion prior’s minimum noise, yielding a tight bound on latent bitrate and interpretable hyperparameters to control the reconstruction-generation tradeoff—all while achieving state-of-the-art FID and FVD with fewer training FLOPs.
Method
The authors leverage a unified latent diffusion framework that integrates a deterministic encoder, a diffusion-based prior, and a conditional diffusion decoder to model image data. The architecture is designed to explicitly regularize the information content of the latent space through the prior while enabling high-fidelity reconstruction via the decoder.
The encoder Eθ maps an input image x to a deterministic latent representation zclean, avoiding the instability associated with learning flexible posterior distributions. This clean latent is then forward-noised to time t=0 using a fixed noise schedule with λ(0)=5, producing a slightly noisy latent z0∼N(α0zclean,σ0), where α0≈1.0 and σ0≈0.08. This step ensures that the latent space is regularized by the diffusion prior, which models the reverse process from pure noise z1∼N(0,I) to z0. The KL divergence between the encoder’s path and the prior’s generative path is minimized using an unweighted ELBO, enforcing that the latent encodes only information that the prior can reliably reconstruct.
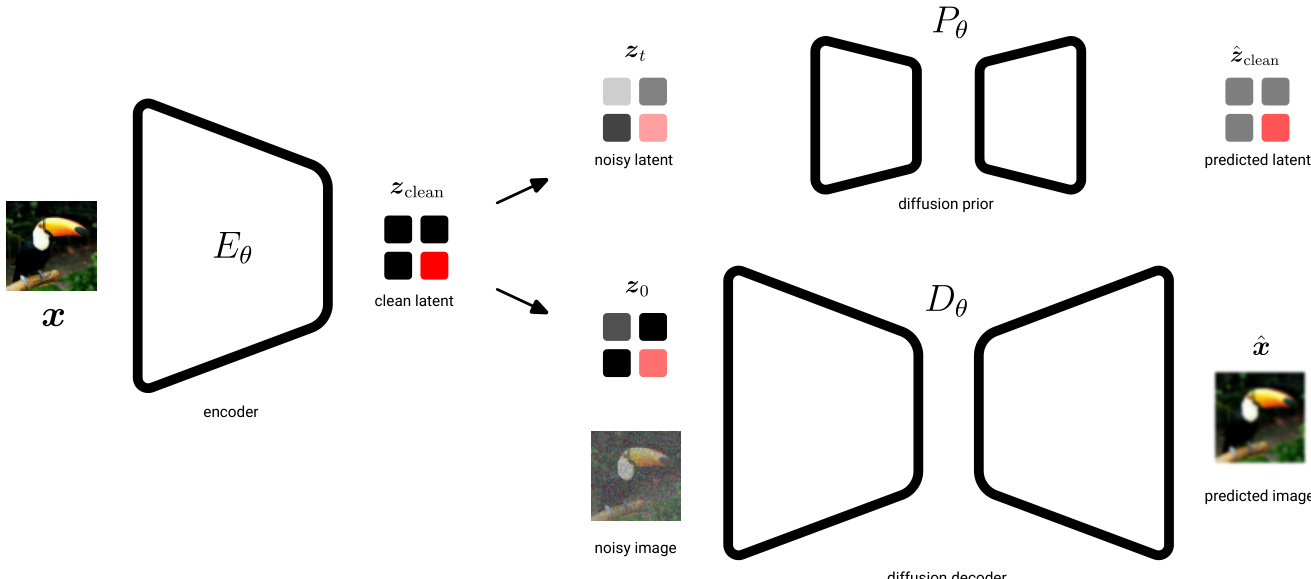
The diffusion decoder Dθ operates in image space and conditions on the latent z0 to reconstruct the original image. It models the reverse diffusion process from noisy image xt to clean image x, with the loss computed as a weighted ELBO. The weighting function wx(λx(t))=sigmoid(λx(t)−b) is applied to prioritize modeling of perceptually salient features at intermediate noise levels. To prevent posterior collapse and encourage the latent to carry meaningful information, the decoder loss is up-weighted by a factor clf (typically 1.3–1.7), effectively down-weighting the KL term in the overall objective.
Training proceeds in two stages. In stage one, the encoder and decoder are jointly optimized with the prior using the combined loss L(θ)=Lz(θ)+Lx(θ), where Lz is the prior loss and Lx is the decoder loss. In stage two, the encoder and decoder are frozen, and a larger, more expressive base model is trained on the fixed latent space z0 using a sigmoid-weighted ELBO to improve sample quality. This base model uses the same final log-SNR λ(0) as the prior, ensuring consistency in the latent noise level.

Architecturally, the encoder is a ResNet with downsampling stages and residual blocks, while the prior and base models are Vision Transformers (ViTs) with varying depths and channel counts. The decoder is implemented as a UViT, combining convolutional downsampling/upscaling with a transformer bottleneck, and employs dropout for regularization. The use of 2x2 patching in the encoder and decoder reduces computational cost without sacrificing performance.
Experiment
- Unified Latents significantly improve pre-training efficiency, outperforming prior methods like Stable Diffusion in FID/FVD vs. training cost trade-offs on ImageNet-512 and Kinetics-600.
- Latent bitrate tuning is critical: lower bitrates favor smaller models for generation quality, while larger models benefit from higher bitrates; optimal settings depend on model scale.
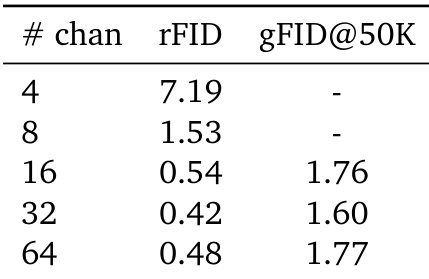
- Latent shape (channel count and spatial downsampling) has minimal impact on performance except at very low channel counts or extreme downsampling.
- L2 regularization or VAE-style priors degrade performance; fixed-variance noisy latents provide better stability and generation quality.
- Ablations confirm key components—diffusion prior, noisy latents, and fixed encoder variance—are essential for strong performance.
- Unified Latents generalize well to text-to-image and video tasks, achieving state-of-the-art FVD on Kinetics-600 and competitive text alignment with minimal guidance.
- End-to-end training is feasible but yields inferior results compared to the two-stage approach; decoder cost remains a practical limitation versus GAN-based alternatives.
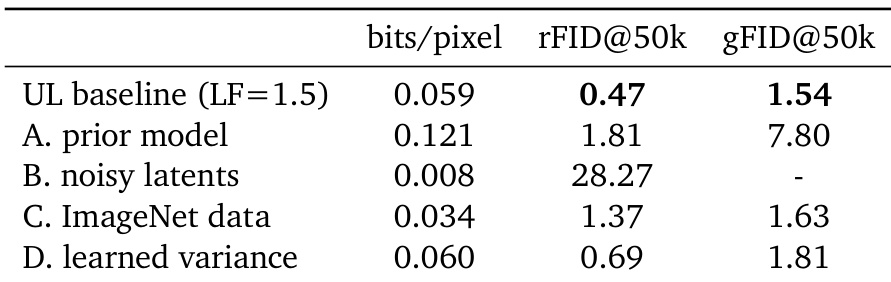
The authors use a diffusion-based prior and reconstruction loss to train Unified Latents, finding that this combination yields the lowest latent bitrate and best generation quality (gFID) compared to alternatives. Replacing either component—such as using an MSE reconstruction loss or a normal prior—leads to higher bitrates and worse generation performance, indicating that the joint diffusion setup is critical for efficient latent modeling. Results show that maintaining low latent complexity while preserving generation fidelity is achievable only when both the prior and reconstruction are diffusion-based.

The authors use Unified Latents with a fixed encoder variance and a diffusion prior to achieve efficient pre-training, and ablation studies show that removing the prior or using noisy latents degrades both reconstruction and generation quality. Results show that training on ImageNet data improves generation FID slightly over text-to-image data, while learned variance increases reconstruction fidelity at the cost of generation performance. The baseline configuration strikes the best balance between latent bitrate, reconstruction accuracy, and generation quality.
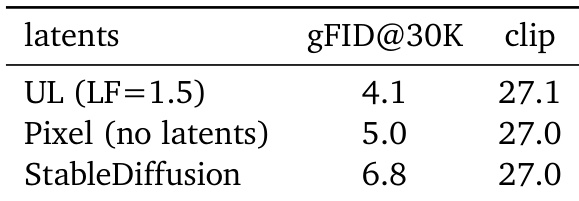
The authors use Unified Latents with a loss factor of 1.5 to achieve superior image generation quality compared to both pixel-based diffusion and Stable Diffusion latents, as measured by lower gFID scores. Text alignment, measured by CLIP scores, remains comparable across all methods, indicating that Unified Latents improve perceptual quality without sacrificing semantic fidelity. Results show that Unified Latents offer a more efficient trade-off between training cost and generation performance than prior approaches.
The authors evaluate how varying the number of latent channels affects reconstruction and generation quality, finding that performance stabilizes beyond 16 channels. While 4 channels yield poor reconstructions, 32 channels achieve the best balance between low rFID and competitive gFID, with 64 channels showing only marginal gains. Results indicate Unified Latents are largely insensitive to channel count once a minimum threshold is met.
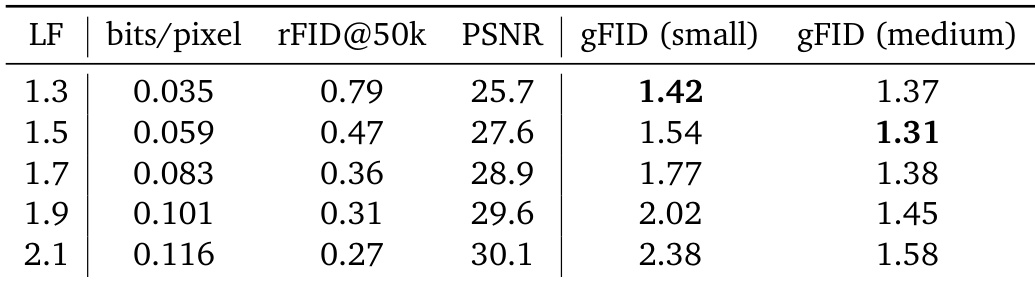
The authors use Unified Latents to tune latent bitrate via loss factor, finding that higher loss factors improve reconstruction quality but increase bitrate, which can hurt generation performance for smaller models. Results show that medium-sized models achieve the best generation FID at moderate loss factors, while small models perform best at lower bitrates despite worse reconstruction. This indicates a trade-off between reconstruction fidelity and generation efficiency that depends on model scale.