Command Palette
Search for a command to run...
Arcee Trinity Large Technical Report
Arcee Trinity Large Technical Report
Abstract
We present the technical report for Arcee Trinity Large, a sparse Mixture-of-Experts model with 400B total parameters and 13B activated per token. Additionally, we report on Trinity Nano and Trinity Mini, with Trinity Nano having 6B total parameters with 1B activated per token, Trinity Mini having 26B total parameters with 3B activated per token. The models' modern architecture includes interleaved local and global attention, gated attention, depth-scaled sandwich norm, and sigmoid routing for Mixture-of-Experts. For Trinity Large, we also introduce a new MoE load balancing strategy titled Soft-clamped Momentum Expert Bias Updates (SMEBU). We train the models using the Muon optimizer. All three models completed training with zero loss spikes. Trinity Nano and Trinity Mini were pre-trained on 10 trillion tokens, and Trinity Large was pre-trained on 17 trillion tokens. The model checkpoints are available at https://huggingface.co/arcee-ai.
One-sentence Summary
Arcee AI and Prime Intellect researchers introduce Trinity Large, Nano, and Mini—sparse MoE models with up to 400B parameters—featuring SMEBU load balancing, Muon optimization, and modern attention architectures, achieving stable training on trillions of tokens for scalable, efficient inference.
Key Contributions
- The Trinity family introduces three open-weight sparse Mixture-of-Experts models—Nano (6B total, 1B active), Mini (26B total, 3B active), and Large (400B total, 13B active)—designed for efficient training and inference, with architecture innovations including interleaved local/global attention and gated attention to support long-context reasoning.
- Trinity Large introduces Soft-clamped Momentum Expert Bias Updates (SMEBU), a novel MoE load balancing strategy that improves expert utilization stability during training, paired with the Muon optimizer to enable large-batch training and zero loss spikes across all models despite scaling to 17T tokens.
- All models were trained stably without loss spikes—Nano and Mini on 10T tokens, Large on 17T tokens—and their checkpoints are publicly available, offering enterprise-friendly open-weight foundations for deployment with verifiable data provenance and jurisdictional control.
Introduction
The authors leverage the growing demand for efficient, scalable, and enterprise-friendly large language models to introduce Trinity Large — a 400B-parameter open-weight Mixture-of-Experts model with only 13B parameters activated per token. Prior work in MoE and long-context architectures often struggles with training stability and inference efficiency at scale, especially under real-world constraints like data sovereignty and auditability. Trinity addresses this by combining sparse MoE layers, interleaved local/global attention, gated attention modules, and the Muon optimizer for improved sample efficiency and stability — all while being trained on 17 trillion tokens and designed for full organizational control. Their contribution includes not only the large model but also a scaling ladder with Trinity Nano and Mini, validating architecture and training pipelines for future efficient scaling.
Dataset
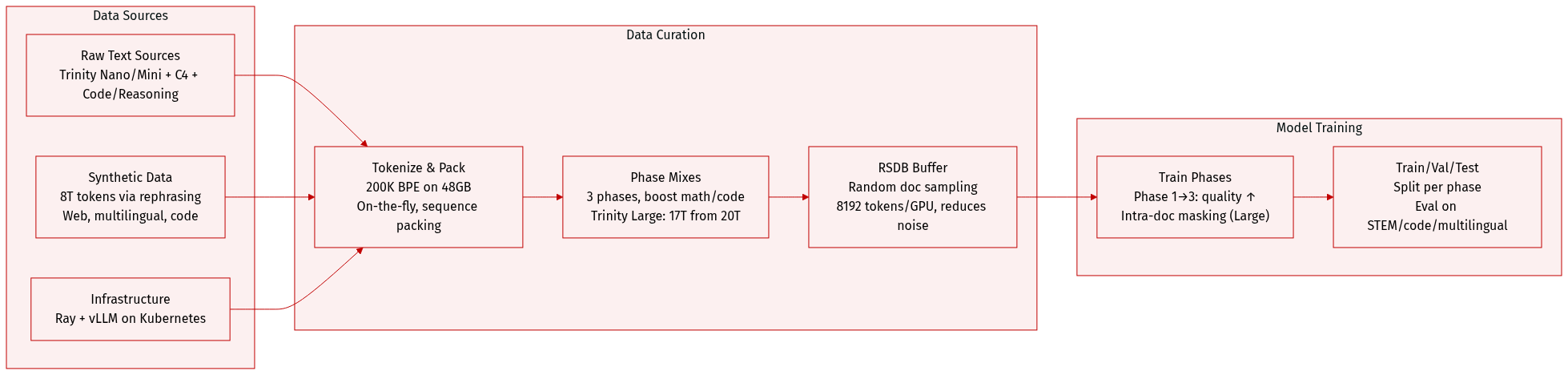
The authors use a custom 200,000-token BPE tokenizer trained on ~48GB of data (~10B tokens), drawn from Trinity Nano/Mini pretraining corpora, multilingual C4 splits, and instruction/reasoning/code data. Non-English languages are underrepresented relative to final training data due to timing constraints.
Key dataset subsets and composition:
- Trinity Nano and Mini: trained on a 10T-token mix (7T phase 1, 1.8T phase 2, 1.2T phase 3), reusing AFM-4.5B and adding math/code.
- Trinity Large: trained on 17T tokens sampled proportionally from a 20T mix (13T phase 1, 4T phase 2, 3T phase 3), enriched with state-of-the-art programming, STEM, reasoning, and multilingual data (Arabic, Mandarin, Japanese, Spanish, German, French, Italian, Portuguese, Indonesian, Russian, Vietnamese, Hindi, Korean, Bengali).
- Synthetic data: over 8T tokens generated via rephrasing high-quality seed documents (6.5T web, 1T multilingual, 800B code), using style/format/content transformations to boost diversity and relevance.
- Infrastructure: synthetic generation scaled via Ray and vLLM on Kubernetes across heterogeneous GPU clusters.
Data usage and processing:
- All models trained in three phases, progressively increasing math/code比重 and data quality.
- Tokenization done on the fly with sequence packing; Trinity Large uses intra-doc attention masking.
- For Trinity Large phase 3, they introduce the Random Sequential Document Buffer (RSDB) to reduce inter-batch correlation: documents are buffered and tokens are randomly sampled across documents during minibatch construction.
- RSDB uses 8192-token buffer per GPU (4096 user-specified), split across 4 workers, with bulk refills and purges for efficiency.
- RSDB reduces Batch Heterogeneity (BatchHet) by 4.23x and step-to-step loss variance by 2.4x compared to baseline sequential packing, improving gradient stability without dropping tokens.
- BatchHet metric tracks microbatch loss variance, correlating with training instability; RSDB reduces kurtosis in gradient norms from 187 to 14.6 in small-scale tests.
The dataset curation represents one of the largest documented synthetic data efforts for LLM pretraining, targeting general English, programming, STEM, and multilingual capabilities — validated by strong downstream performance.
Method
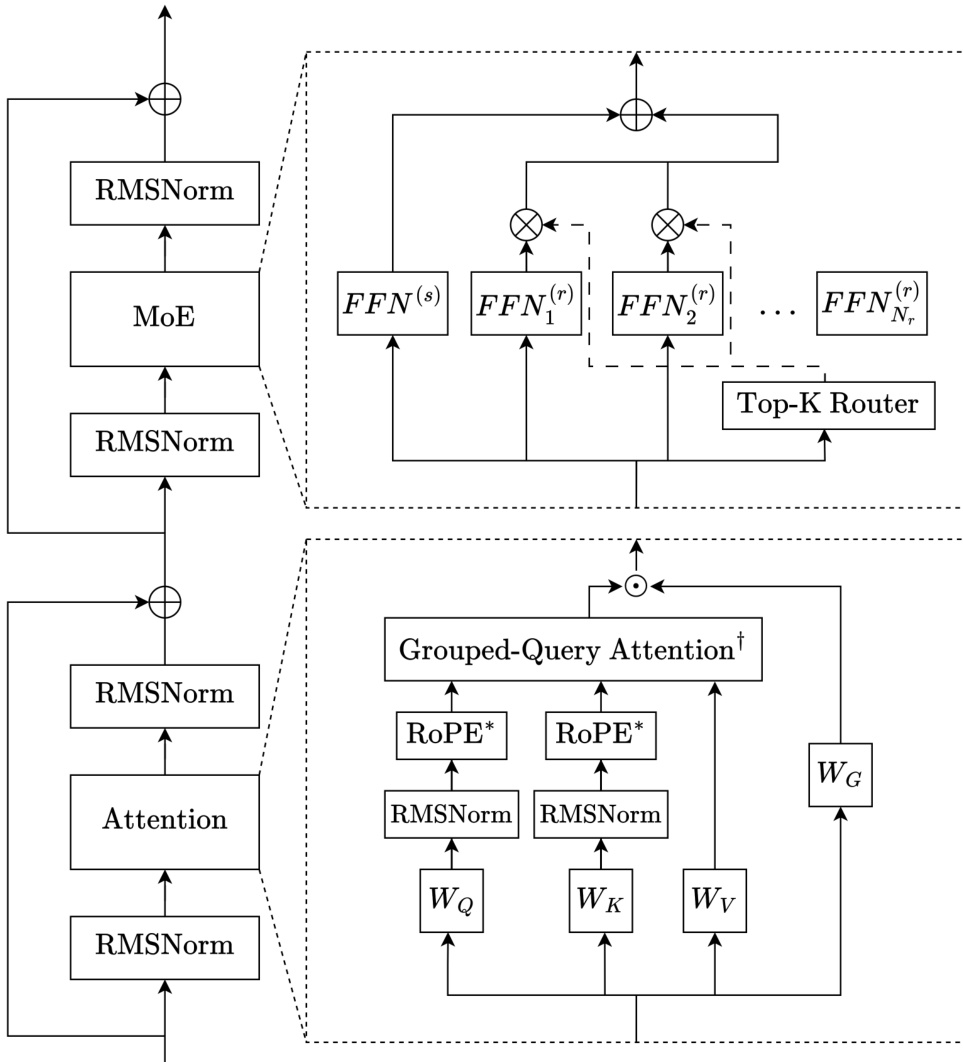
The authors leverage a decoder-only sparse Mixture-of-Experts (MoE) architecture, built upon the Transformer framework, to construct the Trinity family of models. The overall design integrates several modern architectural innovations to enhance training stability, long-context performance, and computational efficiency. The core module structure, as depicted in the framework diagram, consists of alternating attention and MoE blocks, each wrapped in a depth-scaled sandwich normalization scheme.
Each Transformer layer begins with an RMSNorm applied to the input, followed by either an attention or MoE sublayer, and concludes with a second RMSNorm before the residual connection. The attention sublayer employs grouped-query attention (GQA) with QK-normalization, where queries and keys are RMSNormed prior to scaled dot-product attention. This normalization is critical for stabilizing training, particularly under the Muon optimizer, by constraining the growth of attention logits. The attention mechanism alternates between local and global layers in a 3:1 ratio. Local layers use sliding window attention with rotary positional embeddings (RoPE), while global layers omit positional embeddings (NoPE), enabling efficient long-sequence processing and observed length extrapolation. Gated attention is applied post-attention, using a sigmoid-gated linear transformation to modulate the attention output, which mitigates attention sinks and improves generalization.
The MoE sublayer follows the DeepSeekMoE design, incorporating one always-active shared expert and multiple routed experts, with outputs combined via sigmoid-based routing. The router computes normalized sigmoid scores for each expert, and Top-K selection is determined by the sum of router scores and expert bias. The gating scores applied to expert outputs are derived from the router scores alone, decoupling them from the bias updates. For Trinity Mini and Nano, load balancing is achieved via auxiliary-loss-free updates with re-centered expert bias. For Trinity Large, the authors introduce Soft-clamped Momentum Expert Bias Updates (SMEBU), replacing the discrete sign-based update with a continuous tanh-clamped, momentum-smoothed variant to stabilize convergence and reduce oscillation during training. Additionally, a sequence-wise auxiliary loss is applied to promote intra-sequence expert balance.
The model employs depth-scaled sandwich normalization: the first RMSNorm in each layer has a gain initialized to 1, while the second RMSNorm’s gain is scaled by 1/L, where L is the total number of layers. All parameters are initialized from a zero-mean truncated normal distribution with standard deviation 0.5/d, and embedding activations are scaled by d during the forward pass. The architecture is further optimized for throughput in Trinity Large by reducing expert granularity—activating fewer but larger experts per token—while maintaining high total parameter count and low active parameter count.
Experiment
- The tokenizer achieves top compression efficiency for English and French among standard tokenizers, with competitive but slightly trailing CJK performance, attributed to training data constraints; full Trinity Large corpus training is expected to close this gap.
- Infrastructure leverages GPU clusters with customized frameworks and optimizations, including expert parallelism for Trinity Large, dynamic PyTorch version tuning for B300 hardware, and robust failure recovery mechanisms.
- Training hyperparameters are carefully tuned per model size, using Muon for hidden layers and AdamW for embeddings, with learning rate adjustments enabling smooth scaling; context extension employs cosine decay and avoids re-warmup for efficiency.
- Context extension is highly effective, especially for larger models, with Trinity Large achieving near-perfect MK-NIAH scores at 256K and strong generalization up to 1M context; training directly at target length outperforms progressive extension.
- Trinity Large Base matches or exceeds similar open-weight models despite higher sparsity and fewer active parameters, showing strong performance across coding, math, knowledge, and reasoning benchmarks.
- Inference benchmarks confirm efficient performance under FP8 quantization, with vLLM throughput reflecting architectural advantages from sparsity and attention design.
- Training instability in Trinity Large was resolved by combining six stabilization techniques—including SMEBU load balancing, z-loss, aux loss, and intra-document masking—though ablation studies were not feasible due to time constraints.
The authors evaluate Trinity Large Base across multiple benchmarks, showing strong performance in coding, math, commonsense, and knowledge tasks. Results indicate competitive scores relative to other open-weight base models, despite having significantly fewer active parameters. The model demonstrates particular strength in tasks like HellaSwag and TriviaQA, while GPQA Diamond remains a challenging area for improvement.

The authors use a custom tokenizer that achieves the highest bytes-per-token compression on English and French datasets among standard tokenizers, benefiting from a larger vocabulary. For CJK languages, compression is competitive but slightly lower than specialized tokenizers, which the authors attribute to training data constraints. Results show that expanding the training corpus would likely close this gap.

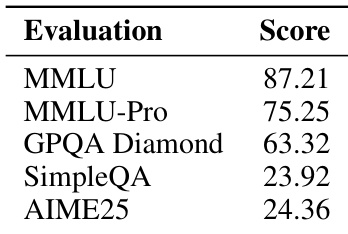
The authors evaluate their instruct-tuned model, Trinity Large Preview, on a set of standard benchmarks including MMLU, MMLU-Pro, GPQA Diamond, SimpleQA, and AIME25, reporting scores that reflect its performance across knowledge, reasoning, and instruction-following tasks. Results show strong performance on knowledge-intensive benchmarks like MMLU and MMLU-Pro, while scores on more specialized or challenging tasks such as GPQA Diamond and AIME25 indicate room for improvement. The model’s design, featuring extreme sparsity and interleaved attention, supports efficient inference without compromising competitive benchmark outcomes.