Command Palette
Search for a command to run...
Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Mobile-Agent-v3.5: Multi-platform Fundamental GUI Agents
Abstract
The paper introduces GUI-Owl-1.5, the latest native GUI agent model that features instruct/thinking variants in multiple sizes (2B/4B/8B/32B/235B) and supports a range of platforms (desktop, mobile, browser, and more) to enable cloud-edge collaboration and real-time interaction. GUI-Owl-1.5 achieves state-of-the-art results on more than 20+ GUI benchmarks on open-source models: (1) on GUI automation tasks, it obtains 56.5 on OSWorld, 71.6 on AndroidWorld, and 48.4 on WebArena; (2) on grounding tasks, it obtains 80.3 on ScreenSpotPro; (3) on tool-calling tasks, it obtains 47.6 on OSWorld-MCP, and 46.8 on MobileWorld; (4) on memory and knowledge tasks, it obtains 75.5 on GUI-Knowledge Bench. GUI-Owl-1.5 incorporates several key innovations: (1) Hybird Data Flywheel: we construct the data pipeline for UI understanding and trajectory generation based on a combination of simulated environments and cloud-based sandbox environments, in order to improve the efficiency and quality of data collection. (2) Unified Enhancement of Agent Capabilities: we use a unified thought-synthesis pipeline to enhance the model's reasoning capabilities, while placing particular emphasis on improving key agent abilities, including Tool/MCP use, memory and multi-agent adaptation; (3) Multi-platform Environment RL Scaling: We propose a new environment RL algorithm, MRPO, to address the challenges of multi-platform conflicts and the low training efficiency of long-horizon tasks. The GUI-Owl-1.5 models are open-sourced, and an online cloud-sandbox demo is available at https://github.com/X-PLUG/MobileAgent.
One-sentence Summary
Researchers from Tongyi Lab and Alibaba Group propose GUI-Owl-1.5, a scalable native GUI agent model across 2B–235B sizes, enabling real-time cloud-edge interaction via innovations like Hybrid Data Flywheel, unified reasoning, and MRPO RL—outperforming open-source models on 20+ benchmarks for automation, grounding, and tool use.
Key Contributions
- GUI-Owl-1.5 introduces a scalable family of native GUI agent models (2B to 235B parameters) supporting desktop, mobile, and browser platforms, enabling real-time cloud-edge collaboration and achieving state-of-the-art results across 20+ benchmarks including OSWorld (56.5), AndroidWorld (71.6), and ScreenSpotPro (80.3).
- The model integrates three core innovations: a Hybrid Data Flywheel combining simulated and cloud sandbox environments for high-quality trajectory data, a Unified Thought-Synthesis pipeline to boost reasoning and tool/memory capabilities, and MRPO, a new RL algorithm that improves training efficiency for multi-platform, long-horizon tasks.
- Built on Qwen3-VL and enhanced with expanded action spaces, hierarchical context compression, and multi-agent collaboration support, GUI-Owl-1.5 demonstrates robust real-world performance in automation, grounding, tool calling, and knowledge tasks, with all models and a cloud-sandbox demo open-sourced.
Introduction
The authors leverage GUI-Owl-1.5, a native multimodal GUI agent model spanning 2B to 235B parameters, to enable cross-platform automation across mobile, desktop, and browser interfaces—addressing the growing need for real-time, cloud-edge collaborative agents. Prior GUI agents struggled with fragmented platform support, limited action spaces, poor long-horizon reasoning, and inefficient data collection. To overcome these, the authors introduce a Hybrid Data Flywheel for high-quality synthetic data, a unified thought-synthesis pipeline to boost tool use and memory, and MRPO, a novel RL algorithm for multi-platform training efficiency. Their model achieves state-of-the-art results across 20+ benchmarks and is open-sourced to accelerate real-world adoption.
Dataset
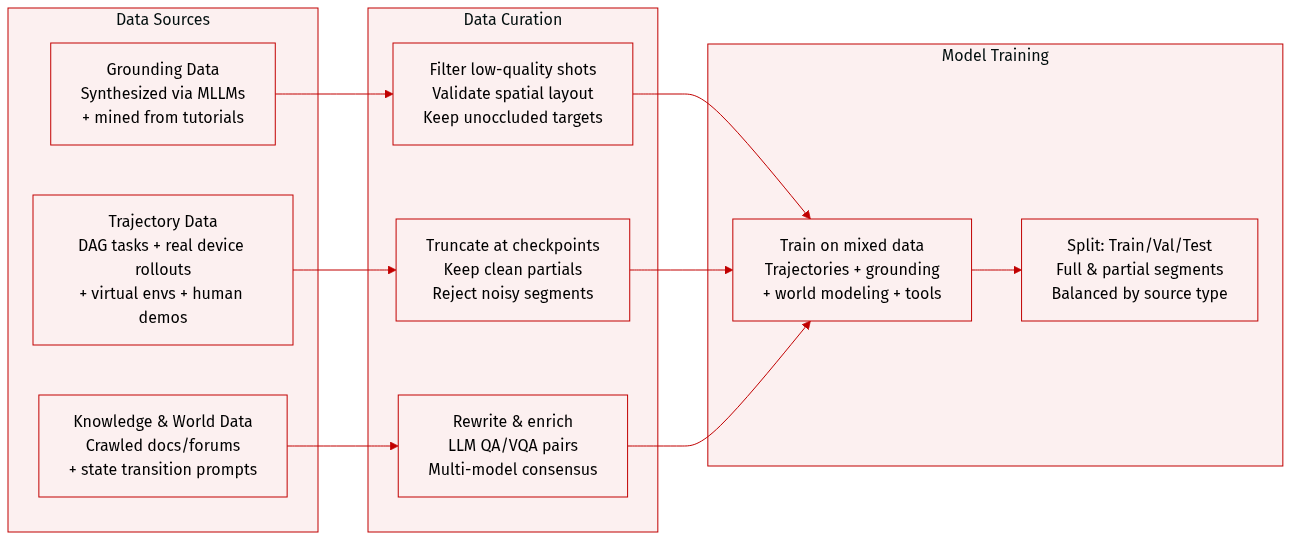
The authors use a unified, multi-source dataset to train GUI-Owl-1.5, combining trajectory and grounding data across real and simulated environments. Here’s how they build and use it:
-
Dataset Composition & Sources:
- Grounding data: Synthesized via MLLMs for complex app interfaces and multi-window layouts; extended via trajectory mining, tutorial parsing, and infeasible query generation.
- Trajectory data: Collected through DAG-based task synthesis, automated rollouts on real devices, human demonstrations, and virtual environments for fine-grained actions.
- Knowledge data: Crawled from official docs, forums, and web datasets, then rewritten into QA/VQA pairs to enrich GUI understanding.
- World modeling data: Generated by prompting models to describe state transitions after each action, teaching the agent to anticipate UI changes.
-
Key Subset Details:
- Hard Grounding Data: Synthesized using annotated UI elements and MLLMs with iterative validation; multi-window scenes built with spatial constraints to avoid occlusion.
- Extended Grounding Data: Trajectory mining uses critic models for quality control; tutorial parsing extracts spatial-semantic QA pairs; infeasible queries are generated via random pairing + multi-model consensus filtering.
- Trajectory Data:
- DAG-based: Tasks sampled as paths in directed acyclic graphs; templates instantiated for diverse entities.
- Automated rollouts: Truncated at last valid checkpoint; remaining subtasks stored as partial trajectories for clean supervision.
- Human demos: Collected for unsolved tasks via cloud annotation on real devices.
- Virtual environments: Web-rendered simulators for scroll/drag actions and high-frequency tasks; support LLM-driven decomposition and RPA scripts for scalable, high-fidelity trajectories.
-
Training Use & Mixture:
- Pre-training combines trajectory data, grounding pairs, QA/VQA knowledge, world-modeling transitions, and tool invocation data.
- Trajectories are split into full or partial segments based on checkpoint validation.
- Grounding data is mixed from synthesized, mined, and augmented sources to cover feasible and infeasible queries.
-
Processing & Cropping:
- Grounding synthesis includes spatial validation to ensure target elements remain visible.
- Trajectories are truncated at verified checkpoints to avoid noisy labels.
- Virtual environments provide precise feedback and enable script-based rollouts for canonical actions.
- All data undergoes LLM rewriting or filtering (e.g., critic models, multi-model consensus) to ensure fidelity and relevance.
Method
The authors leverage a multi-stage training paradigm to develop GUI-Owl-1.5, a multi-platform GUI agent capable of long-horizon reasoning, tool invocation, and cross-device orchestration. The system is initialized from Qwen3-VL and undergoes supervised fine-tuning followed by reinforcement learning, with architectural enhancements designed to support complex, real-world agent behaviors.
At the core of the agent’s decision-making is a multi-turn interactive framework that treats GUI control as a closed-loop decision process. At each step t, the agent receives a visual observation It and a natural language instruction Lt, then generates an action conclusion Ct and a structured tool call Ar. The action space is significantly expanded beyond primitive GUI operations to include external tool calls and API invocations, enabling integration with heterogeneous systems such as databases and third-party services. Refer to the framework diagram, which illustrates how the system message defines the available action space, the user message contains the task instruction and compressed histories, and the response message includes the agent’s reasoning, action summaries, and final output.
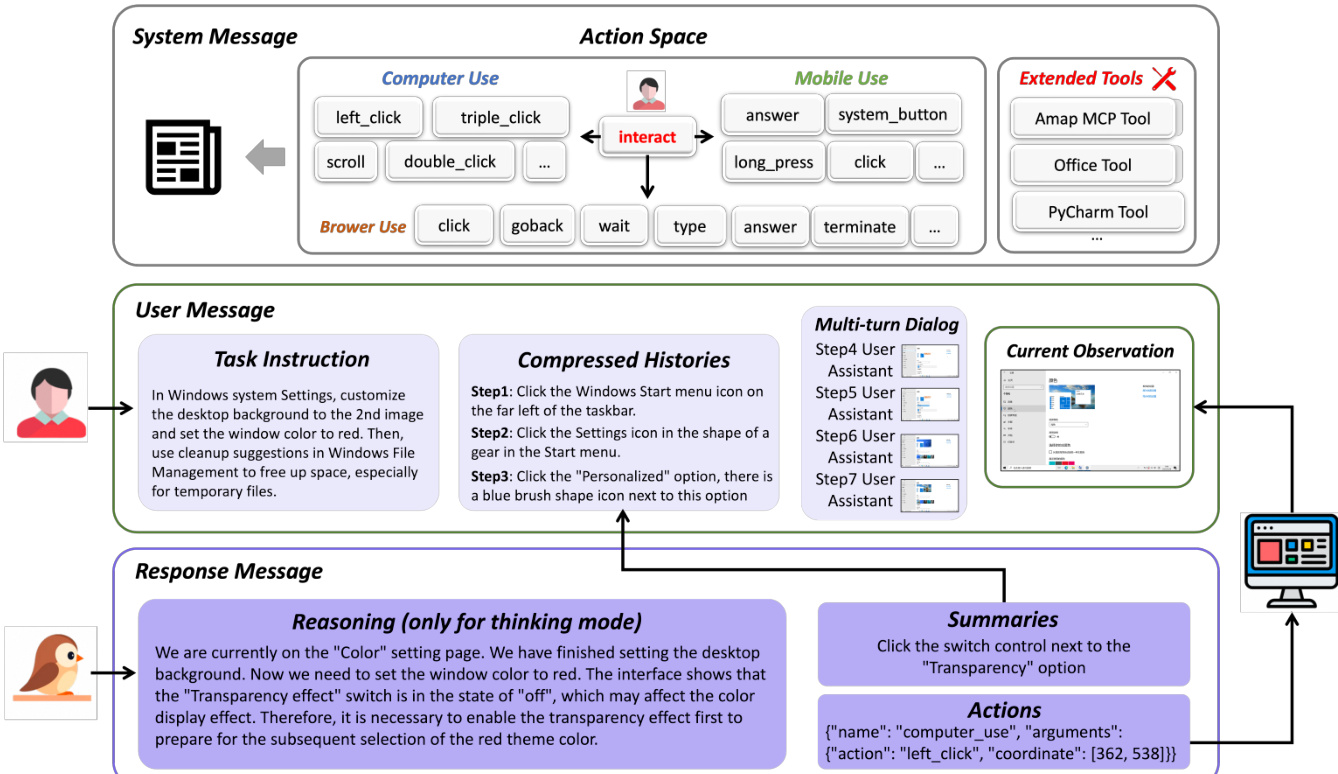
To manage long-horizon tasks efficiently, the agent employs a hierarchical context compression mechanism. The most recent N dialogue turns are retained in full, preserving multi-modal fidelity, while earlier interactions are condensed into a textual summary S1:t−N−1 formed by concatenating prior action conclusions. This design balances immediate decision-making precision with long-term task awareness.
Three complementary strategies enhance the agent’s capabilities: GUI Knowledge Injection, Unified CoT Synthesis, and Multi-Agent Collaboration. The Unified CoT Synthesis pipeline augments trajectory data with step-wise reasoning, memory, and reflection. For each trajectory step, a vision-language model (VLM) extracts query-relevant screen content and evaluates whether the executed action aligns with expectations by comparing pre- and post-action screenshots. If the outcome is consistent, task progress is updated; otherwise, error corrections are generated. These observations, reflections, and memory updates are fed into an LLM to synthesize a thought (simulating the agent’s reasoning) and a conclusion (the concise action decision). When tool invocation is involved, tool definitions are also provided to the LLM to guide tool selection.
The Multi-Agent Collaboration framework, based on Mobile-Agent-v3.5, decomposes agent functionality into four specialized roles: Manager (planner), Worker (executor), Reflector (verifier), and Notetaker (memory). The Manager decomposes the user instruction into subgoals and updates them dynamically using optionally retrieved external knowledge KRAG. The Worker generates actions conditioned on the current context, including subgoals, feedback, and persistent notes. The Reflector evaluates the transition after each action and provides diagnostic feedback Ft=(jt,ϕt), where jt∈{SUCCESS,FAILURE}. The Notetaker updates persistent memory Nt only upon successful transitions, ensuring salient information is retained for future steps. The system iterates through this loop until all subgoals are completed or a termination condition is met.
The training process begins with supervised fine-tuning (SFT) on diverse trajectory data annotated with CoT, augmented grounding data, structured tool invocation supervision, and browser interaction data. This stage aligns the pre-trained model with multi-device GUI manipulation, tool invocation, and browser automation. The subsequent reinforcement learning phase, called MRPO (Multi-platform Reinforcement Policy Optimization), further refines the agent for long-horizon, tool-augmented control across heterogeneous devices. To address challenges such as outcome collapse in grouped rollouts and cross-device gradient interference, the authors introduce an online rollout buffer that oversamples trajectories and subsamples to preserve on-policy diversity, and an alternating optimization schedule that trains on one device family per stage to isolate gradient conflicts.
To ensure consistency between training and inference, the authors implement token-id transport: the environment returns not only the textual action payload but also the exact token IDs used during inference, allowing the training process to compute log-probabilities on the same discrete events that were executed. This preserves the integrity of KL regularization and policy-gradient estimators.

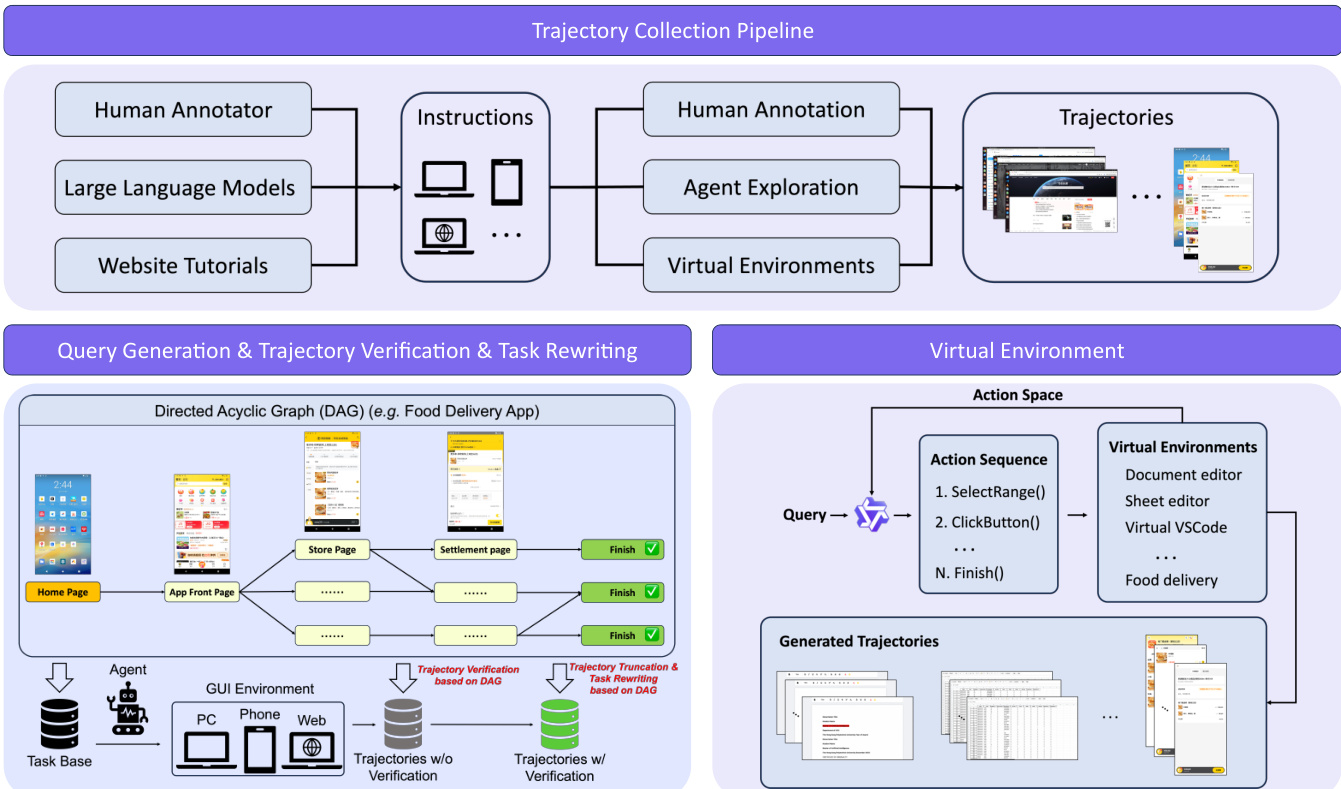
The trajectory collection pipeline integrates human annotation, agent exploration, and virtual environments to generate diverse training data. Virtual environments simulate complex applications such as document editors and food delivery apps, enabling the generation of structured action sequences and verified trajectories. Grounding data is synthesized through a multi-window, high-resolution pipeline that ensures element non-overlap and layout diversity, while infeasible grounding data is generated to improve robustness. The authors also inject external knowledge from official documentation, software forums, and web datasets to enhance the agent’s world modeling and task decomposition capabilities.
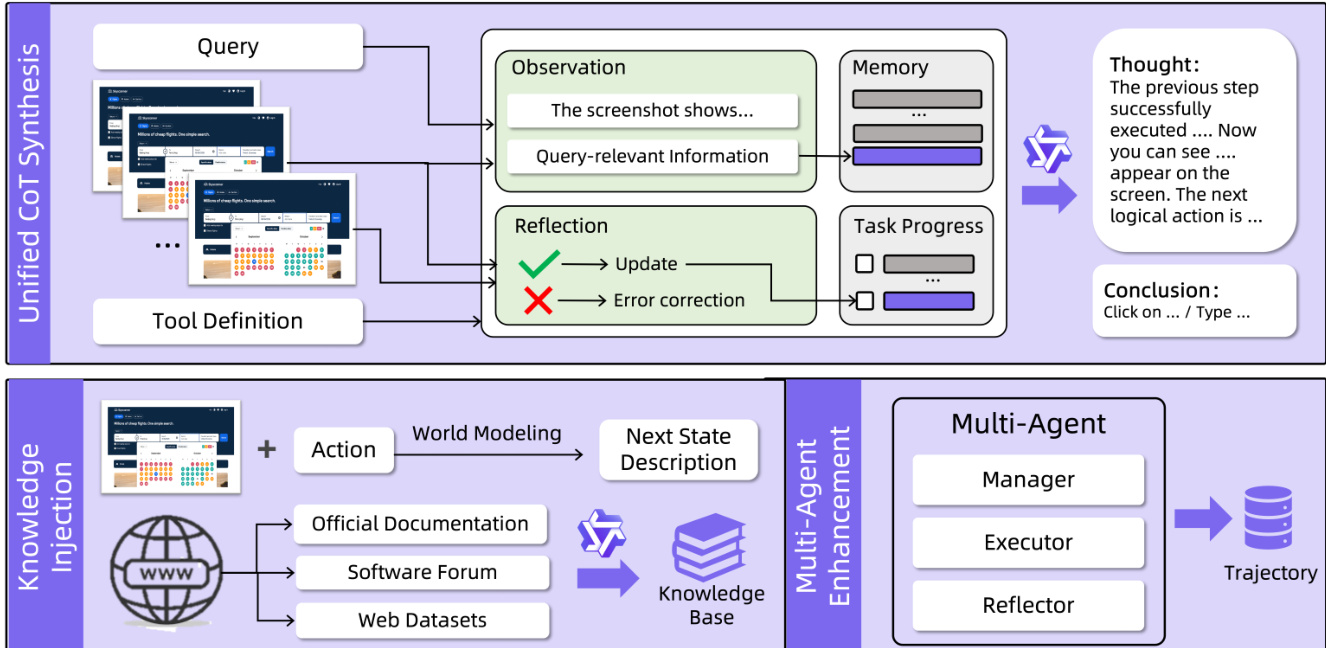
The resulting architecture enables GUI-Owl-1.5 to operate as both an end-to-end agent and a component within multi-agent frameworks, supporting unified control across PC, mobile, and web platforms with optimized latency and real-time interaction.
Experiment
- GUI-Owl-1.5 demonstrates state-of-the-art performance across multi-device GUI automation, excelling in end-to-end task execution and multi-agent coordination on live environments including mobile, computer, and browser platforms.
- The model shows strong grounding capability, particularly at high resolutions and complex interfaces, with further gains when using a two-stage refinement strategy involving cropping and zooming.
- It achieves top-tier results in comprehensive GUI understanding, including interface perception, interaction prediction, and instruction interpretation, while also exhibiting superior long-horizon memory retention compared to prior native agents.
- Thinking variants consistently outperform Instruct variants, especially on tasks requiring extended planning, validating the value of thought-based training.
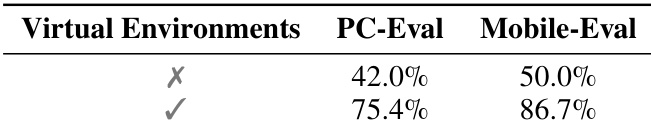
- Ablation studies confirm the critical role of virtual environment-generated trajectories and unified CoT synthesis in enabling robust reasoning and multi-step task execution.
- Reinforcement learning strategies—specifically unstable-task prioritization and interleaved multi-platform training—prove effective in accelerating convergence and maintaining stable cross-platform performance.
- Case studies illustrate the model’s ability to handle complex, real-world workflows involving cross-app navigation, tool invocation, memory retention, and multi-step planning across devices.
The authors evaluate GUI-Owl-1.5 across multiple platforms and find it consistently outperforms both general-purpose and specialized GUI models, particularly in grounding and multi-platform task execution. Results show that larger and thinking-mode variants deliver superior performance, with the 32B-Thinking model achieving the highest overall score. The model’s effectiveness is further validated through ablation studies, confirming that virtual environment training and unified CoT synthesis are critical to its strong end-to-end and cross-platform capabilities.
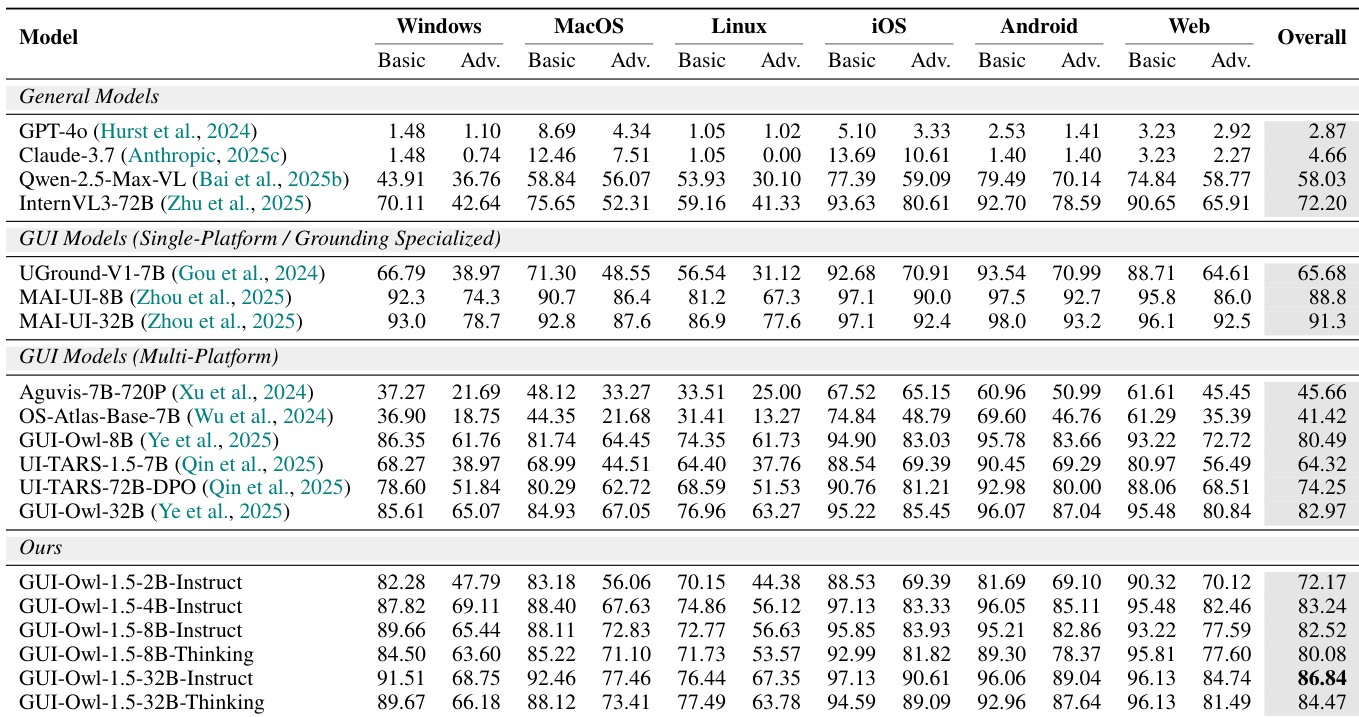
The authors evaluate GUI-Owl-1.5 across multiple platforms and find it consistently outperforms prior multi-platform and single-platform GUI models in grounding tasks, particularly in text and icon localization across mobile, desktop, and web interfaces. Results show that larger and thinking-mode variants of GUI-Owl-1.5 achieve the highest overall scores, with the 32B-Thinking model reaching 95.3, indicating strong cross-platform generalization and refined perception capabilities. The performance gains highlight the effectiveness of their training approach in unifying GUI understanding across diverse interface types.

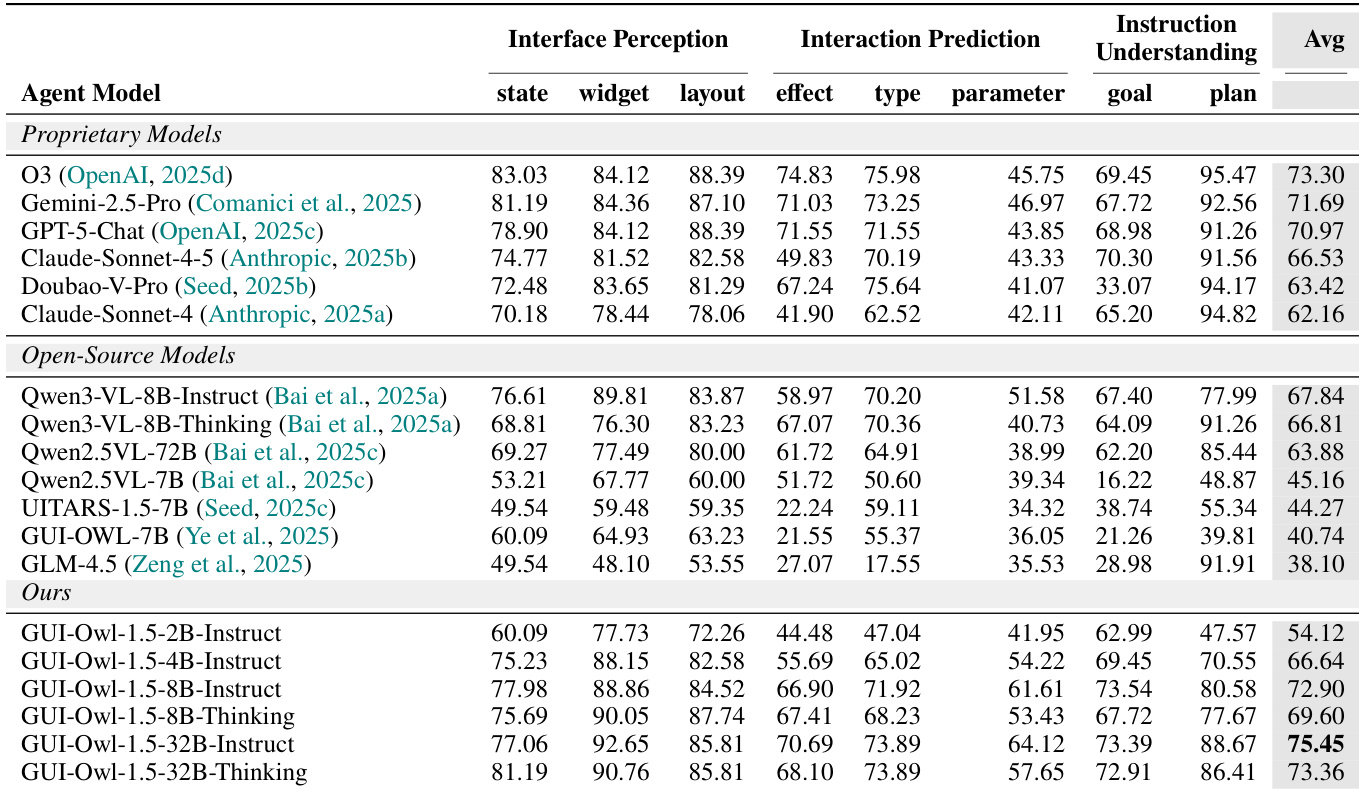
The authors evaluate GUI-Owl-1.5 across multiple dimensions of GUI understanding and find that its larger variants, particularly the 32B models, achieve state-of-the-art performance on comprehensive GUI knowledge benchmarks, outperforming both proprietary and open-source counterparts. Results show consistent gains with increasing model scale and the Thinking variant, indicating that enhanced reasoning supervision improves performance across interface perception, interaction prediction, and instruction understanding. The model’s strong performance across all subcategories confirms its ability to integrate deep UI comprehension with task planning and execution.
The authors use virtual environments to generate high-quality training trajectories, which significantly improve performance on both desktop and mobile evaluation benchmarks. Removing this component leads to substantial drops in accuracy, confirming its critical role in overcoming real-world exploration limitations and enabling scalable, effective training.
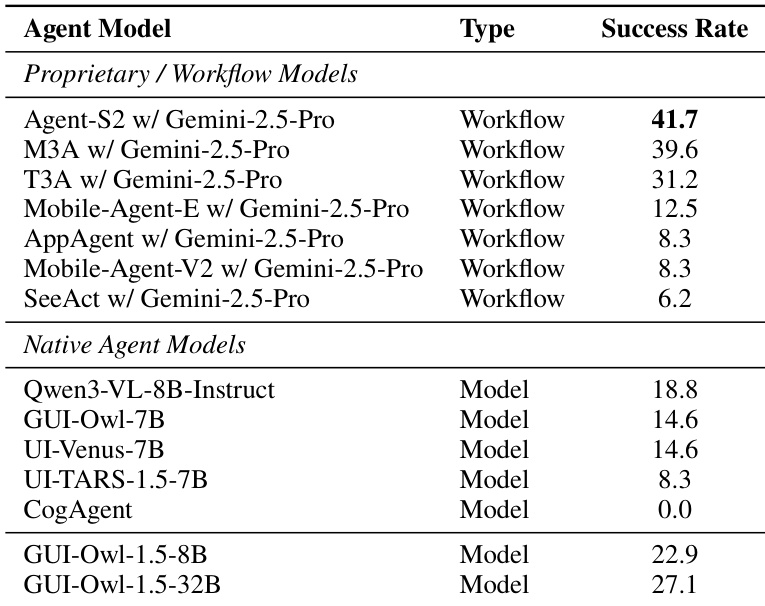
The authors evaluate GUI-Owl-1.5 across multiple benchmarks and find that its native agent variants significantly outperform both proprietary workflow-based systems and other open-source models, with the 32B version achieving the highest success rate at 27.1. Results indicate that larger parameter counts correlate with stronger performance, and GUI-Owl-1.5’s architecture enables it to surpass models relying on external orchestration or smaller-scale training. These findings confirm the effectiveness of its end-to-end training approach in handling complex, multi-step GUI automation tasks.