Command Palette
Search for a command to run...
AutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines
AutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines
Abstract
The performance of autonomous Web GUI agents heavily relies on the quality and quantity of their training data. However, a fundamental bottleneck persists: collecting interaction trajectories from real-world websites is expensive and difficult to verify. The underlying state transitions are hidden, leading to reliance on inconsistent and costly external verifiers to evaluate step-level correctness. To address this, we propose AutoWebWorld, a novel framework for synthesizing controllable and verifiable web environments by modeling them as Finite State Machines (FSMs) and use coding agents to translate FSMs into interactive websites. Unlike real websites, where state transitions are implicit, AutoWebWorld explicitly defines all states, actions, and transition rules. This enables programmatic verification: action correctness is checked against predefined rules, and task success is confirmed by reaching a goal state in the FSM graph. AutoWebWorld enables a fully automated search-and-verify pipeline, generating over 11,663 verified trajectories from 29 diverse web environments at only $0.04 per trajectory. Training on this synthetic data significantly boosts real-world performance. Our 7B Web GUI agent outperforms all baselines within 15 steps on WebVoyager. Furthermore, we observe a clear scaling law: as the synthetic data volume increases, performance on WebVoyager and Online-Mind2Web consistently improves.
One-sentence Summary
Researchers from multiple institutions propose AutoWebWorld, a framework generating verifiable synthetic web environments via FSMs to train GUI agents, enabling cost-efficient, scalable data production that boosts real-world performance without human verification.
Key Contributions
- AutoWebWorld introduces a state-driven framework that models web environments as Finite State Machines (FSMs) to enable programmatic verification of agent actions and task success, eliminating reliance on costly and inconsistent human or LLM verifiers.
- The system automatically generates 29 synthetic websites and 11,663 verified interaction trajectories at $0.04 per trajectory by executing breadth-first search over FSM graphs and validating outcomes via executable front-end renderings.
- Training agents on this synthetic data yields state-of-the-art performance on WebVoyager within 15 steps and demonstrates a clear scaling law, where increasing synthetic data volume consistently improves real-world benchmark results on WebVoyager and Online-Mind2Web.
Introduction
The authors leverage Finite State Machines to synthesize verifiable web environments for training GUI agents, addressing the high cost and inconsistency of verifying real-world interaction trajectories. Prior methods rely on external verifiers—human annotators or LLMs—to judge correctness from opaque UI feedback, creating a costly and unreliable bottleneck. AutoWebWorld eliminates this by encoding explicit states, actions, and transitions into synthetic websites, enabling programmatic verification and scalable trajectory generation at $0.04 per trajectory. Their approach yields 11,663 verified trajectories across 29 environments, and training on this data improves real-world agent performance with a clear scaling law, demonstrating synthetic data’s potential to drive generalization in foundational models.
Dataset

The authors use AutoWebWorld, a synthesized GUI trajectory dataset built from 29 programmatically generated websites, to train and evaluate GUI agents. Here’s how the data is composed, processed, and used:
-
Dataset Composition and Sources:
Each website is defined by three core files:fsm.json: Encodes semantic transitions, grounded GUI actions, and success criteria (via terminal pages).bfs.json: Contains BFS-generated trajectories with step-by-step semantic states and GUI procedures.data.js: Structured backend data (e.g., provider lists, appointments, bills) used to render dynamic UI elements and generate visual-grounded queries.
-
Key Subset Details:
- BFS-driven Queries: Generated directly from
bfs.json, using interaction templates over verified trajectories. - Visual-grounded Queries: Built from
data.jsand rendered item images; target items are referenced via visual descriptions (not names), preserving interaction templates. - Screenshot QA Queries: Sampled from feature-based QA templates in
data.js, then filtered via VLM to ensure the queried feature is visible in the screenshot. - All subsets use five standardized interaction modes: search, scroll, slider, sort, checkbox — differing only in grounding signal (name vs. visual description).
- BFS-driven Queries: Generated directly from
-
Training Data Usage:
- 11,663 verified trajectories are synthesized across 29 websites.
- To reduce redundancy, one trajectory per task is sampled from parallel BFS paths → 1,215 distinct trajectories (12,585 steps total).
- Some trajectories are converted into grounding supervision: individual steps are extracted and rewritten as UI localization examples.
- Final training set combines trajectory steps and grounding examples → ~16k total training steps for GRPO.
- Mixture ratios are not explicitly stated, but grounding and trajectory data are unified into a single training corpus.
-
Processing and Filtering:
- Trajectories undergo strict execution-based filtering via Playwright: each atomic GUI action is replayed; any failure (e.g., missing element, broken button) discards the entire trajectory.
- Only reproducibly executable trajectories are retained, paired with grounded actions and state sequences.
- Queries are generated post-filtering, with metadata (interaction mode, template parameters, thresholds) stored in lightweight manifests for reproducible analysis.
- No cropping is applied; instead, visual grounding relies on feature-conditioned images and screenshot visibility checks.
- Final dataset enables intrinsic verification (no human judges), with deterministic transitions and goal attainment defined by the FSM.
This pipeline yields high-quality, reproducible, long-horizon trajectories (avg. 21.94 steps) at low cost ($0.04 per trajectory), suitable for training and benchmarking GUI agents on real-world tasks.
Method
The authors leverage a transition-driven, multi-stage pipeline to generate synthetic web environments with intrinsic verification, enabling scalable trajectory synthesis and reproducible benchmarking. The core architecture, as depicted in the framework diagram, consists of four sequential phases: FSM generation, web environment synthesis, trajectory enumeration via BFS, and execution-based filtering.
In the first phase, a multi-agent system generates a Finite State Machine (FSM) specification from a given web theme. The FSM proposer drafts an initial structure including page definitions, signature variables, and transition rules. This candidate FSM is then validated by an automated validator that checks for structural soundness—such as reachability of terminal states and deterministic effect application—and returns revision suggestions if constraints are violated. An improver agent iteratively refines the FSM until validation passes. This loop ensures the FSM encodes a deterministic state-transition system where each state s=(p,σ) comprises a page identifier p and a structured signature σ capturing task-relevant variables. Transitions are governed by explicit preconditions and effect rules, ensuring that the next state st+1=T(st,at) is uniquely determined by the current state and action.
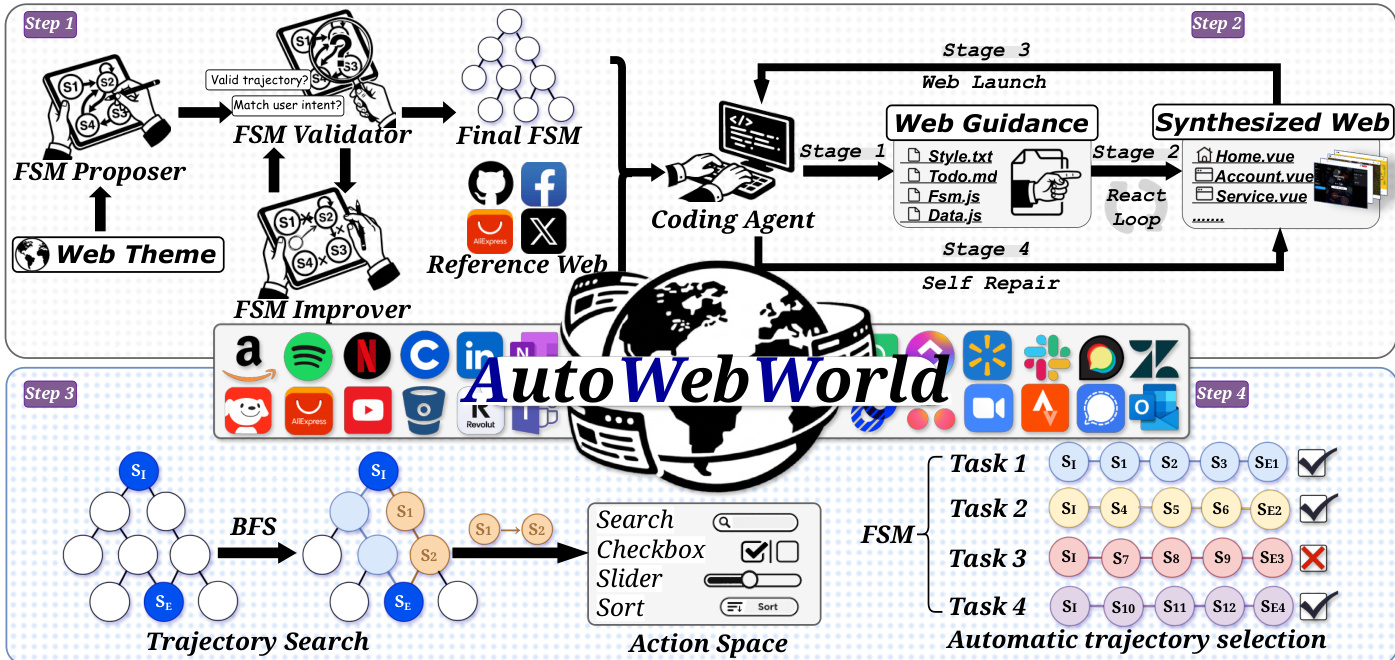
The second phase translates the validated FSM into an executable simulated web environment. A coding agent, guided by the FSM and a reference website for stylistic anchoring, follows a four-stage pipeline: (1) generating project guidelines and scaffolding, (2) synthesizing Vue components for each page with iterative self-review, (3) building the project, and (4) triggering a self-repair loop if build failures occur. Crucially, the generated DOM strictly implements the selectors defined in the FSM, creating a deterministic bridge between semantic actions and their GUI realizations.
In the third phase, the authors perform breadth-first search (BFS) over the FSM’s state graph to enumerate all possible trajectories from the initial state s0 to goal states. Each node corresponds to a semantic state (p,σ), and edges represent executable actions. BFS uses signature hashing for deduplication and expands nodes only if preconditions are satisfied. Goal states are defined via predicates G(s) over signature variables, such as reaching a terminal page or satisfying a constraint like “cart contains at least one item.” This ensures trajectories are correct by construction at the semantic level.
The final phase involves grounding and filtering. Each BFS-derived action sequence is expanded into a sequence of atomic GUI operations (e.g., click, type) via its pre-defined gui_procedure, which specifies selectors and normalized coordinates. These sequences are replayed on the synthesized website using Playwright. Only trajectories that execute all steps successfully and reach the intended goal state are retained. This end-to-end process, illustrated in the figure, ensures that collected trajectories are both semantically valid and executable, enabling large-scale, verifiable data generation without human annotation.
Experiment
- AutoWebWorld-synthesized trajectories enhance GUI agent performance in real-world navigation and grounding tasks, validated on WebVoyager and ScreenSpot benchmarks.
- Training on verified synthetic data yields strong generalization, with Ours-7B outperforming open-source baselines and Ours-3B surpassing larger models despite using only 16K steps, demonstrating high data efficiency.
- Grounding supervision from AutoWebWorld consistently improves performance on ScreenSpot-V2 and ScreenSpot-Pro, particularly in text and icon localization tasks.
- Scaling synthetic data volume shows clear performance gains on real-world benchmarks, with success rates rising steadily as sample size increases, indicating sustained scalability.
- Grounding data is critical for stable and effective GRPO training; its absence leads to early reward spikes but long-term performance degradation.
- AutoWebWorld’s synthesized websites serve as challenging, reproducible benchmarks, with agents performing worse on them than on real sites, confirming their non-trivial difficulty.
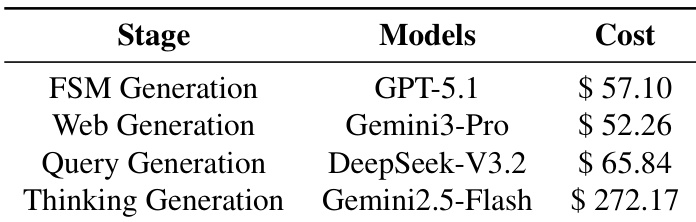
- Cost analysis reveals that per-step reasoning dominates expenses, highlighting optimization potential through reduced redundant planning and improved action constraints.
- Training details confirm efficient distributed setup using 8 A800 GPUs, BF16 precision, FlashAttention-2, and DeepSpeed ZeRO-3 for memory optimization.
The authors use AutoWebWorld-synthesized trajectories to train GUI agents, achieving significant performance gains over baseline models on real-world navigation and grounding tasks. Results show that even smaller models like Ours-3B outperform larger baselines when trained on verified synthetic data, demonstrating strong data efficiency. Scaling the synthesized dataset further improves performance, and grounding data proves essential for stable and sustained reward growth during training.
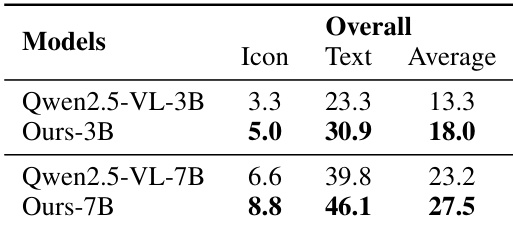
The authors use AutoWebWorld-synthesized trajectories to train GUI agents, achieving strong real-world navigation performance with significantly fewer training samples than comparable models. Results show that their 7B model outperforms other open-source baselines on WebVoyager, while their 3B model surpasses several larger models, demonstrating high data efficiency. Performance scales predictably with increased synthetic data volume, and grounding supervision further stabilizes and improves training outcomes.
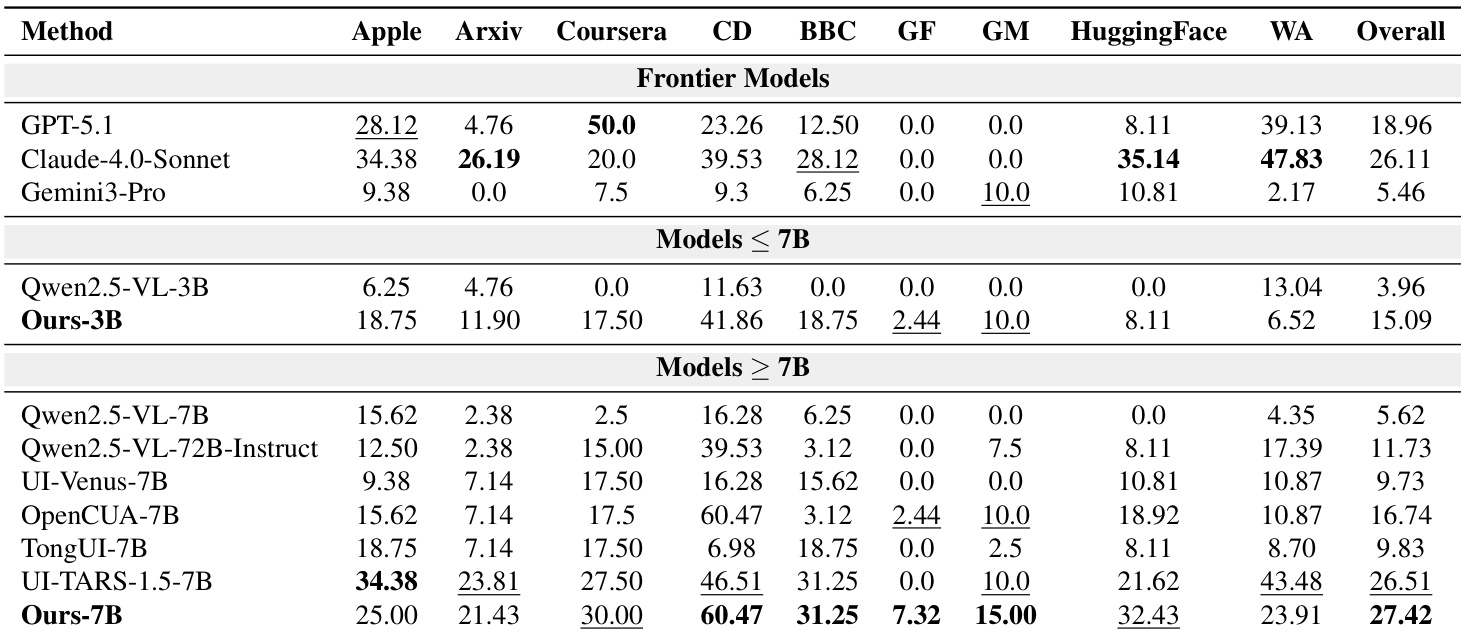
The authors use AutoWebWorld to generate synthesized GUI environments with inherently verified trajectories, achieving strong real-world navigation and grounding performance despite using far fewer training samples than comparable methods. Results show that scaling the synthesized data volume leads to consistent improvements on real-world benchmarks, and grounding data plays a critical role in stabilizing and enhancing reward learning during training. The synthesized environments also present non-trivial challenges comparable to real websites, while offering full controllability and reproducibility at a significantly lower cost per trajectory.

The authors use AutoWebWorld to generate synthetic GUI trajectories and grounding data, which significantly improve agent performance on real-world navigation and grounding benchmarks, even with limited training samples. Results show that scaling up synthesized data leads to consistent gains, and grounding supervision is critical for stable reward learning during training. The cost analysis reveals that per-step reasoning dominates expenses, highlighting the need to optimize planning efficiency rather than environment execution.
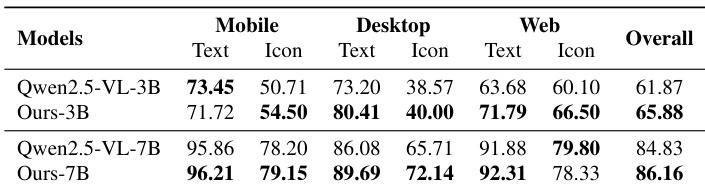
The authors use AutoWebWorld-synthesized trajectories to train GUI agents, achieving significant improvements in grounding performance across both ScreenSpot-V2 and ScreenSpot-Pro benchmarks. Results show consistent gains for both 3B and 7B models, particularly in text and icon localization tasks, indicating that the synthetic data effectively transfers to real-world grounding challenges. The improvements are more pronounced on ScreenSpot-Pro, suggesting the synthesized data better captures complex, real-world grounding demands.