Command Palette
Search for a command to run...
SpargeAttention2: Trainable Sparse Attention via Hybrid Top-k+Top-p Masking and Distillation Fine-Tuning
SpargeAttention2: Trainable Sparse Attention via Hybrid Top-k+Top-p Masking and Distillation Fine-Tuning
Jintao Zhang Kai Jiang Chendong Xiang Weiqi Feng Yuezhou Hu Haocheng Xi Jianfei Chen Jun Zhu
Abstract
Many training-free sparse attention methods are effective for accelerating diffusion models. Recently, several works suggest that making sparse attention trainable can further increase sparsity while preserving generation quality. We study three key questions: (1) when do the two common masking rules, i.e., Top-k and Top-p, fail, and how can we avoid these failures? (2) why can trainable sparse attention reach higher sparsity than training-free methods? (3) what are the limitations of fine-tuning sparse attention using the diffusion loss, and how can we address them? Based on this analysis, we propose SpargeAttention2, a trainable sparse attention method that achieves high sparsity without degrading generation quality. SpargeAttention2 includes (i) a hybrid masking rule that combines Top-k and Top-p for more robust masking at high sparsity, (ii) an efficient trainable sparse attention implementation, and (iii) a distillation-inspired fine-tuning objective to better preserve generation quality during fine-tuning using sparse attention. Experiments on video diffusion models show that SpargeAttention2 reaches 95% attention sparsity and a 16.2x attention speedup while maintaining generation quality, consistently outperforming prior sparse attention methods.
One-sentence Summary
Researchers from Tsinghua University and ByteDance propose SpargeAttention2, a trainable sparse attention method combining Top-k and Top-p masking with distillation-based fine-tuning, enabling 95% sparsity and 16.2x speedup in video diffusion models without quality loss, surpassing prior training-free approaches.
Key Contributions
- SpargeAttention2 introduces a hybrid Top-k and Top-p masking rule that robustly preserves critical attention patterns under high sparsity, addressing failures of individual masking strategies when attention weight distributions are either uniform or highly skewed.
- It implements an efficient trainable sparse attention kernel and adopts a velocity-level distillation loss during fine-tuning, which aligns sparse attention outputs with a frozen full-attention model to maintain generation quality despite mismatched fine-tuning data distributions.
- Evaluated on video diffusion models, SpargeAttention2 achieves 95% attention sparsity and a 16.2x attention speedup while preserving visual quality and temporal coherence, outperforming prior training-free and trainable sparse attention methods.
Introduction
The authors leverage trainable sparse attention to accelerate video diffusion models, which face heavy computational costs due to long sequences and quadratic attention complexity. Prior methods either use fixed masking rules (like Top-k or Top-p) that fail under high sparsity—either missing context in uniform distributions or over-relying on attention sinks in skewed ones—or rely on diffusion loss for fine-tuning, which degrades quality when fine-tuning data doesn’t match pre-training distributions. Their main contribution, SpargeAttention2, introduces a hybrid Top-k+Top-p masker for robust token selection, an efficient trainable sparse attention kernel, and a distillation-based fine-tuning objective that preserves generation quality by aligning with a frozen full-attention model. This enables 95% sparsity and 16.2x attention speedup without sacrificing output fidelity.

Dataset
- The authors use four distinct image prompts to generate visual content for Figure 1, each designed to test stylistic and compositional diversity in image synthesis.
- The first prompt depicts a polar bear playing guitar on an Arctic shore, combining realistic wildlife photography with whimsical narrative elements under golden daylight.
- The second features a cartoon-style 3D animated teddy bear drumming in Times Square, emphasizing vibrant urban energy, dynamic camera movement, and high-detail animation.
- The third describes a serene coastal landscape at Carmel-by-the-Sea, rendered in realistic detail with natural lighting, wide-angle framing, and environmental motion like gentle waves and breeze.
- The fourth shows a clownfish swimming through a coral reef, captured in wide-angle underwater view with natural light filtering through water, highlighting biodiversity and fluid motion.
- No dataset is explicitly constructed or sourced from external collections; all content is generated from these hand-crafted prompts.
- The authors do not mention training splits, mixture ratios, or cropping strategies — the prompts serve as standalone creative specifications for visual generation, not as training data.
- Metadata or processing steps beyond prompt specification are not described; the focus is on visual output fidelity and stylistic control.
Method
The authors leverage a structured approach to sparse attention in diffusion models, combining architectural innovation with a tailored training objective to achieve high sparsity without compromising generation quality. The core of their method, SparseAttention2, consists of two key components: a hybrid masking strategy for accurate sparsity control and a distillation-based fine-tuning protocol to preserve generative behavior.
At the architectural level, SparseAttention2 operates within the block-sparse attention paradigm, which aligns sparsity patterns with GPU-friendly tiling to enable practical speedups. The attention computation begins with standard query, key, and value matrices Q,K,V∈RN×d, from which the score matrix S=QK⊤/d is derived. Instead of computing the full attention matrix, SparseAttention2 applies a binary mask M∈{0,1}N×N to retain only a subset of attention weights, reducing computational cost from O(N2d) to a sparse equivalent. To ensure hardware efficiency, the mask is applied at the block level: tensors are partitioned into tiles Qi,Kj,Vj, and each tile pair (i,j) is either fully retained or dropped based on a block-level mask Mij. This block-wise gating allows the kernel to skip entire matrix multiplications and softmax operations for masked tiles, as formalized by Mij[:,:]=0⇒skip QiKj⊤ and PijVj.
To determine which blocks to retain, the authors introduce a hybrid Top-k and Top-p masking strategy. Rather than relying on either method alone—which can fail under uniform or skewed attention distributions—the hybrid approach computes a pooled attention map Pˉ∈RN/bq×N/bkv by mean-pooling queries and keys within each block. The mask Mˉij is then set to 1 if block (i,j) is selected by either Top-k (keeping the top k% of weights per row) or Top-p (keeping the minimal set of blocks whose cumulative probability reaches p%). Formally, Mˉij=1 if j∈Top-k(Pˉi,:,k%)∪Top-p(Pˉi,:,p%). This dual criterion ensures robustness across diverse attention patterns, preventing the pitfalls of fixed-count or fixed-threshold masking.
For model adaptation, the authors replace the standard diffusion loss with a velocity distillation loss to mitigate behavior drift during fine-tuning. In the teacher-student setup, the original full-attention model is frozen as the teacher, while the sparse-attention model serves as the student. Both receive identical inputs: noisy latents xt=tx1+(1−t)x0, timesteps t, and text prompts ctxt. The student is trained to match the teacher’s predicted velocity field ufull(xt,ctxt,t), minimizing the mean squared error LVD=E[∥usparse−ufull∥2]. This distillation objective directly aligns the sampling dynamics of the two models, avoiding the distribution mismatch that arises when fine-tuning with the standard diffusion loss. The fine-tuning data are used only to construct xt; no supervision is derived from the ground-truth velocity vt=x1−x0.
The implementation of SparseAttention2 is built on FlashAttention, with custom CUDA kernels that efficiently skip masked computations during both forward and backward passes. The adaptation procedure involves replacing all attention layers in a pre-trained diffusion model with SparseAttention2 and fine-tuning the student model under the velocity distillation loss. This end-to-end pipeline enables 95% attention sparsity, yielding a 16.2× speedup in attention computation and a 4.7× speedup in end-to-end generation, while preserving video generation quality.
Experiment
- Top-k and Top-p masking strategies perform differently depending on attention weight distribution: Top-p outperforms Top-k on uniform distributions, while Top-k is better on skewed ones; their combination balances both cases.
- Fine-tuning with sparse attention leads to more concentrated attention distributions, reducing sparse-attention error by lowering dropped and renormalization terms under fixed sparsity.
- Standard diffusion-loss fine-tuning degrades model performance regardless of attention type, primarily due to dataset mismatch with pre-training data, not sparsity itself.
- SpargeAttention2 achieves state-of-the-art generation quality under high sparsity (85%–95%) while delivering significant efficiency gains, outperforming prior methods in both speed and stability.
- Ablations confirm that SpargeAttention2’s hybrid Top-k+Top-p masker, trainable adaptation, and velocity distillation loss are critical to its success under high sparsity.
- SpargeAttention2 enables up to 16.2× attention latency speedup and 4.7× end-to-end generation acceleration without sacrificing quality, with clear qualitative improvements over baselines.
Results show that after fine-tuning with sparse attention, the attention distribution becomes more concentrated, leading to higher sparsity and a lower L1 error compared to the pre-fine-tuning state. This indicates that fine-tuning improves the alignment between sparse and full attention outputs by reducing both dropped and renormalization errors.
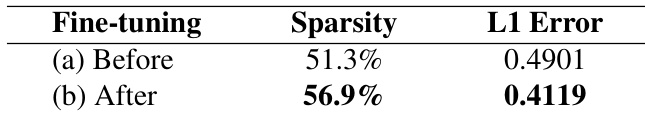
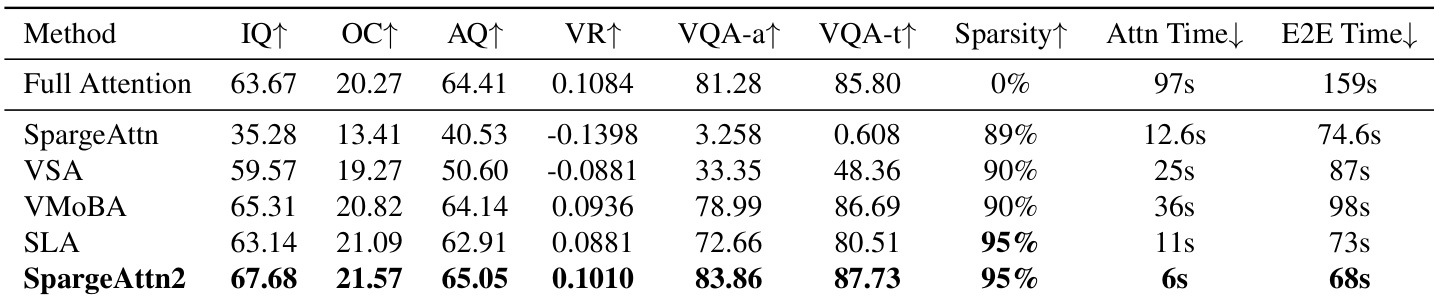
The authors evaluate SpargeAttention2 against prior sparse attention methods under high sparsity, showing it achieves the highest generation quality metrics while maintaining 95% attention sparsity. It also delivers the fastest attention latency and end-to-end generation time, outperforming baselines in both efficiency and output fidelity. Results confirm that SpargeAttention2’s hybrid masking and training design enables robust performance where other methods degrade.
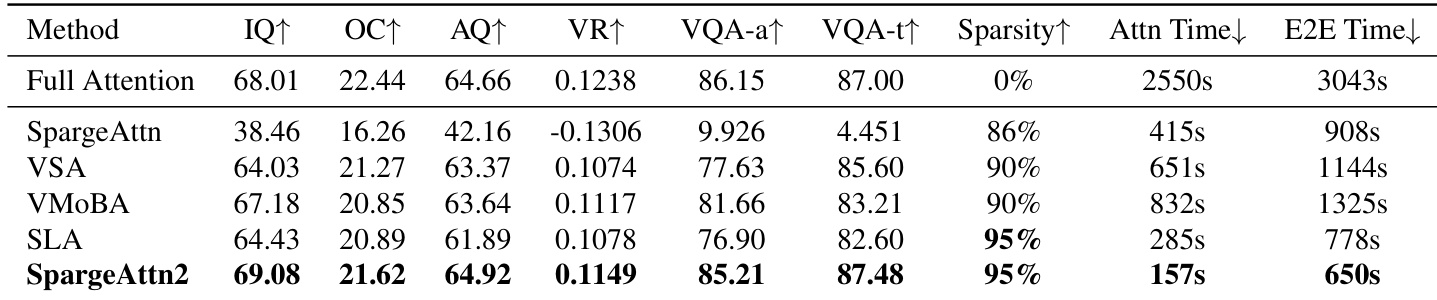
The authors evaluate SpargeAttention2 against prior sparse attention methods under high sparsity, showing it achieves the highest generation quality metrics while reducing attention latency by up to 16.2x and end-to-end time by up to 4.7x. Results indicate that SpargeAttention2 maintains or exceeds full-attention performance even at 95% sparsity, outperforming baselines in both efficiency and output quality. The hybrid Top-k+Top-p masking and velocity distillation training strategy contribute to its robustness and effectiveness across model scales.
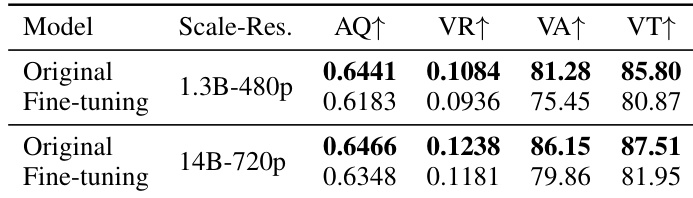
The authors evaluate fine-tuning effects on two model scales under diffusion loss, observing consistent degradation in aesthetic quality, vision reward, and VQA accuracy compared to original pre-trained models. This decline occurs even with full attention, indicating the issue stems from dataset mismatch rather than attention sparsity. The results underscore the need for alternative training objectives when fine-tuning data diverges from pre-training data quality.
The authors evaluate SpargeAttention2 against ablated variants and find that combining Top-k and Top-p masking with trainable adaptation yields the best generation quality and alignment across model sizes. Disabling training or using only one masking strategy leads to significant performance drops, confirming the necessity of both components. Replacing velocity distillation with standard diffusion loss also reduces effectiveness, highlighting the importance of the proposed training objective.