Command Palette
Search for a command to run...
PROPELLA-1: MULTI-PROPERTY DOCUMENT ANNOTATION FOR LLM DATA CURATION AT SCALE
PROPELLA-1: MULTI-PROPERTY DOCUMENT ANNOTATION FOR LLM DATA CURATION AT SCALE
Maximilian Idahl Benedikt Droste Björn Plüster Jan Philipp Harries
Abstract
Since FineWeb-Edu, data curation for LLM pretraining has predominantly relied on single scalar quality scores produced by small classifiers. A single score conflates multiple quality dimensions, prevents flexible filtering, and offers no interpretability. We introduce propella-1, a family of small multilingual LLMs (0.6B, 1.7B, 4B parameters) that annotate text documents across 18 properties organized into six categories: core content, classification, quality and value, audience and purpose, safety and compliance, and geographic relevance. The models support 57 languages and produce structured JSON annotations conforming to a predefined schema. Evaluated against a frontier commercial LLM as a reference annotator, the 4B model achieves higher agreement than much larger general-purpose models. We release propella-annotations, a dataset of over three billion document annotations covering major pretraining corpora including data from FineWeb-2, FinePDFs, HPLT 3.0, and Nemotron-CC. Using these annotations, we present a multi-dimensional compositional analysis of widely used pretraining datasets, revealing substantial differences in quality, reasoning depth, and content composition that single-score approaches cannot capture. All model weights and annotations are released under permissive, commercial-use licenses.
One-sentence Summary
The authors introduce PROPELLA-1, a family of small multilingual LLMs with 0.6B, 1.7B, and 4B parameters that replace single scalar scores with multi-property document annotations across 18 properties and 57 languages to generate structured JSON, demonstrating that the 4B model achieves higher agreement than much larger general-purpose models against a frontier commercial LLM reference annotator while releasing over three billion annotations covering major pretraining corpora including FineWeb-2, FinePDFs, HPLT 3.0, and Nemotron-CC under permissive commercial-use licenses.
Key Contributions
- propella-1 is a family of small multilingual LLMs (0.6B, 1.7B, 4B parameters) that annotate text documents across 18 properties organized into six categories: core content, classification, quality and value, audience and purpose, safety and compliance, and geographic relevance. These models support 57 languages and produce structured JSON annotations conforming to a predefined schema.
- Evaluated against a frontier commercial LLM as a reference annotator, the 4B parameter model achieves higher agreement than much larger general-purpose models.
- propella-annotations is released as a dataset of over three billion document annotations covering major pretraining corpora including data from FineWeb-2, FinePDFs, HPLT 3.0, and Nemotron-CC. Multi-dimensional compositional analysis using these annotations reveals substantial differences in quality and reasoning depth that single-score approaches cannot capture.
Introduction
Data quality serves as a high-leverage factor in Large Language Model pretraining, where rigorous curation can yield multiplicative efficiency gains over raw token volume. Existing pipelines typically rely on single scalar scores that conflate distinct quality dimensions and often lack multilingual support. The authors introduce PROPELLA-1, a family of small multilingual models that enable structured multi-property annotation across 18 distinct quality dimensions. This framework supports 57 languages and releases over three billion document annotations to facilitate flexible, composable filtering strategies for LLM training.
Dataset
-
Dataset Composition and Sources
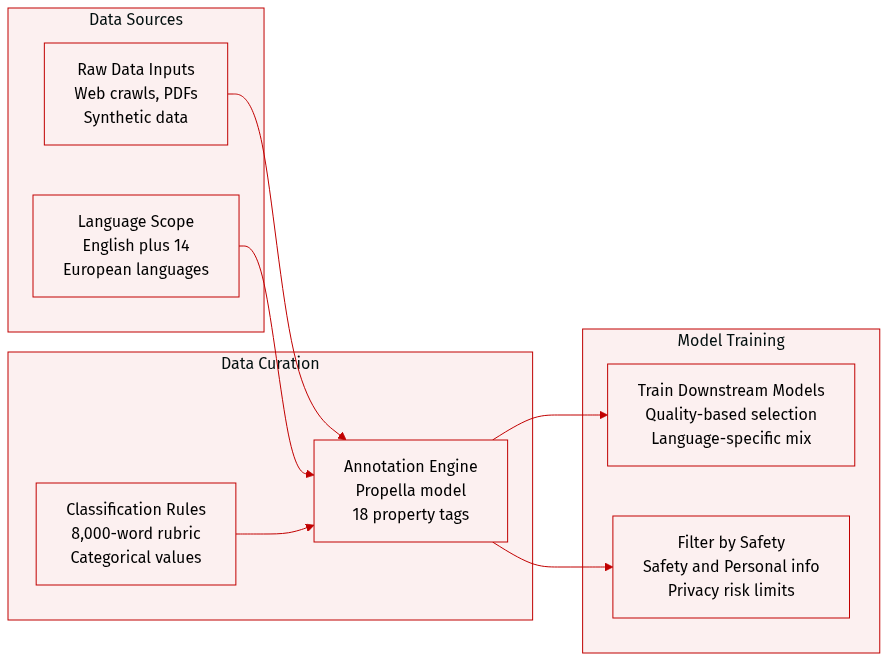
- The authors release propella-annotations, a dataset of over three billion document annotations hosted on the Hugging Face Hub under a CC-BY-4.0 license.
- The data spans diverse pretraining sources including web crawls (FineWeb-2, HPLT 3.0, Nemotron-CC, German Commons), extracted PDFs (FinePDFs), encyclopedic text (finewiki), and synthetic instruction-following data (SYNTH).
- Although the annotation model supports 57 languages, the public release currently covers English and 14 European languages with the largest volumes in German, Spanish, French, and Italian.
-
Annotation Structure and Properties
- Each record contains 18 structured categorical properties organized into six categories such as content quality, safety, and business sector.
- Annotations are keyed by the document identifier from the source dataset to enable direct joining without redistributing the original text.
- The schema includes multi-select fields for business sectors and technical content, as well as ordinal ratings for quality and integrity.
- A comprehensive 8,000-word rubric guides the classification process, providing detailed definitions and examples for each property value.
-
Processing and Model Training
- All annotations were produced using the propella-1-4b model via distributed inference on 3,936 A100 GPUs.
- The underlying annotation model was trained on a diverse sample covering 57 languages with approximately 35% English content.
- To address API content filter limitations, a small subset of the training data was annotated manually.
- The inference pipeline scaled to annotate approximately 500 million documents from FineWeb-2 in roughly 3.5 hours.
-
Usage and Application
- The authors use the dataset to analyze content profiles across different languages and sources, revealing significant variations in quality and commercial bias.
- Practitioners can use the metadata to construct flexible filtering predicates, such as selecting documents with high educational value and low commercial bias simultaneously.
- The structured labels support language-specific filtering strategies rather than applying uniform quality thresholds across all languages.
- Safety and PII annotations allow for compliance-aware filtering while limiting privacy risks by storing only categorical labels rather than source text.
Method
The propella-1 family introduces a methodological shift from single scalar quality scores to structured multi-dimensional annotation. The system employs a family of small multilingual large language models to annotate text documents across 18 properties. These properties are organized into six categories covering core content, classification, quality and value, audience and purpose, safety and compliance, and geographic relevance.
The underlying architecture consists of three models based on the Qwen-3 framework with sizes of 0.6B, 1.7B, and 4B parameters. The authors selected decoder-only models over encoder-based classifiers to leverage native handling of long documents up to 64K context windows. This design choice also enables the production of all 18 annotations as structured JSON output which removes the need for per-property classifier training. Through fine-tuning, the models internalize detailed annotation guidelines to achieve strong performance with a compact prompt.
Prompt design utilizes a system prompt of approximately 800 tokens that lists all properties with enumerated values and brief descriptions. This is significantly shorter than the full annotation prompt used during training data creation. The models support 57 languages and produce structured JSON annotations conforming to a predefined schema.
Evaluation logic covers several key dimensions. Information density measures the ratio of valuable information to redundancy. Content ranges from dense where every sentence adds new information to empty where content is dominated by repetition. Reasoning depth is assessed using thinking-trace signals such as stepwise structure and hypothesis testing. Automation heuristics count lexical cues like therefore or thus and structure cues like proof blocks. Thresholding determines the classification where ≥2 structural cues or ≥5 lexical cues indicate at least explanatory content.
Safety assessment guidelines prioritize context and intent. Medical or educational discussions of sensitive topics may be appropriate depending on the audience. Regional identification relies on primary indicators including geographic references, institutional references, and cultural markers. Language context provides hints but remains non-determinative.
Experiment
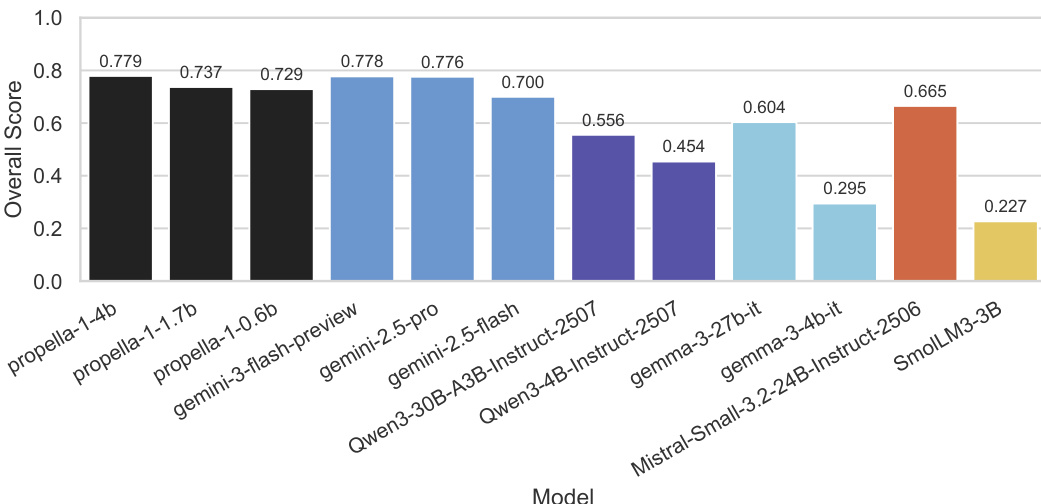
The evaluation compares specialized Propella-1 models against general-purpose baselines using a test set annotated by Gemini-3-Pro as a high-quality reference standard. Experiments validate that small, fine-tuned models can match the annotation quality of significantly larger models while maintaining high inference efficiency through optimized precision and structured output. Additionally, qualitative case studies demonstrate that multi-property annotation uncovers nuanced data characteristics and heterogeneity that single-score quality classifiers overlook.
The the the table compares the annotation quality of two propella-1 model variants under bf16 and fp8 inference precisions. Results demonstrate that fp8 precision maintains performance comparable to bf16, with only marginal variations observed between the two settings across different model sizes. The larger 4B model achieves slightly better performance with fp8 precision than with bf16. The smaller 1.7B model exhibits a negligible decrease in performance when switching to fp8. The overall difference in scores between the two precision modes is minimal across both model sizes.

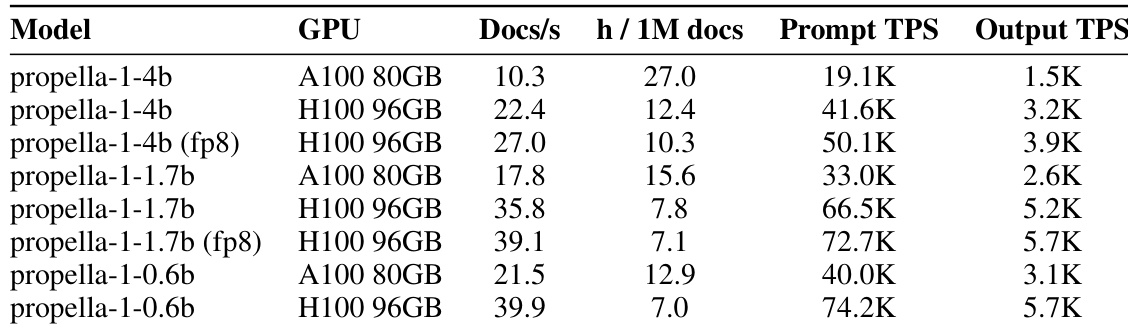
The authors evaluate the serving infrastructure and throughput of the propella-1 model family across different hardware configurations and precisions. Results show that newer H100 GPUs and fp8 precision significantly boost processing speeds compared to A100 GPUs and standard precision. Additionally, the benchmarks reveal that the system is prefill-bound, with prompt processing speeds far exceeding output generation rates. H100 GPUs provide higher throughput compared to A100 GPUs for all model variants. Enabling fp8 precision further accelerates inference speeds on H100 hardware. Inference performance is dominated by prompt processing, with prompt TPS significantly higher than output TPS.
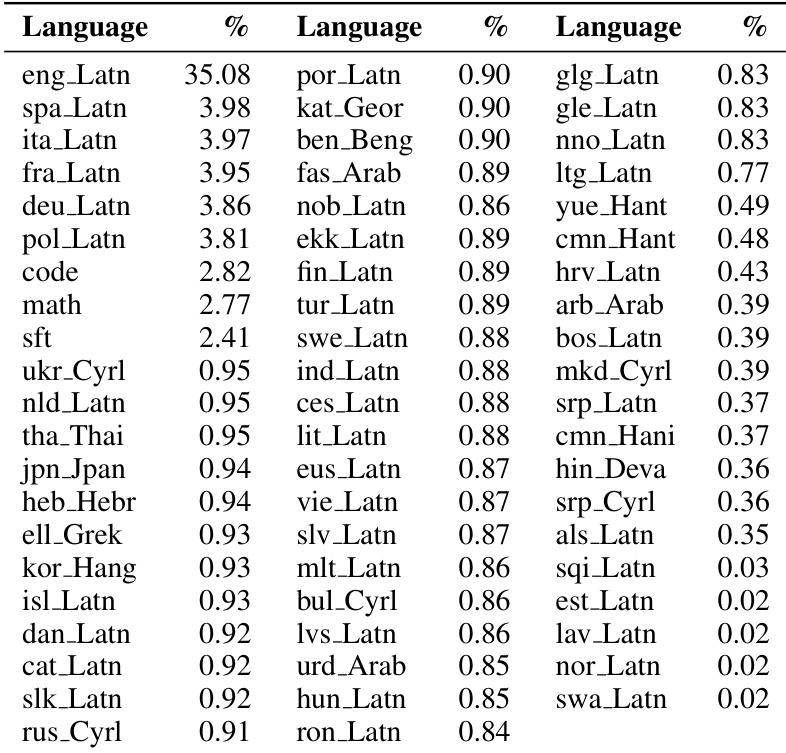
The the the table outlines the language distribution across the annotated dataset, confirming coverage of 57 distinct languages. English is the predominant language, representing a substantial majority of the data, while the remaining languages exhibit a long-tail distribution with significantly lower representation. English is the most represented language, holding the largest share of the dataset. The dataset includes a diverse set of 57 languages spanning multiple writing systems. Many languages appear in the long tail with minimal representation, comprising a negligible fraction of the total.
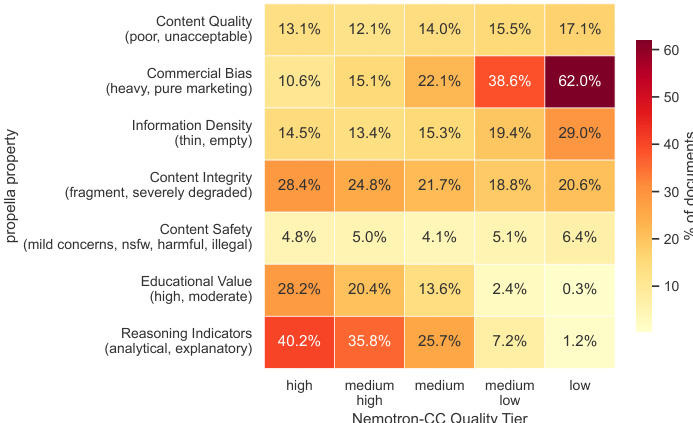
The authors audit documents across five Nemotron-CC quality tiers to examine multi-dimensional quality profiles using propella-1 annotations. The analysis reveals that while higher tiers generally exhibit better content quality, the high tier still contains a significant portion of documents with specific issues like commercial bias and fragmented integrity that single-score classification fails to capture. Documents in lower tiers exhibit significantly higher commercial bias and lower educational value compared to high tiers. Reasoning indicators are prevalent in the high tier but diminish drastically in lower quality tiers. Surprisingly, the high quality tier contains the highest rate of fragmented content integrity issues among all tiers.
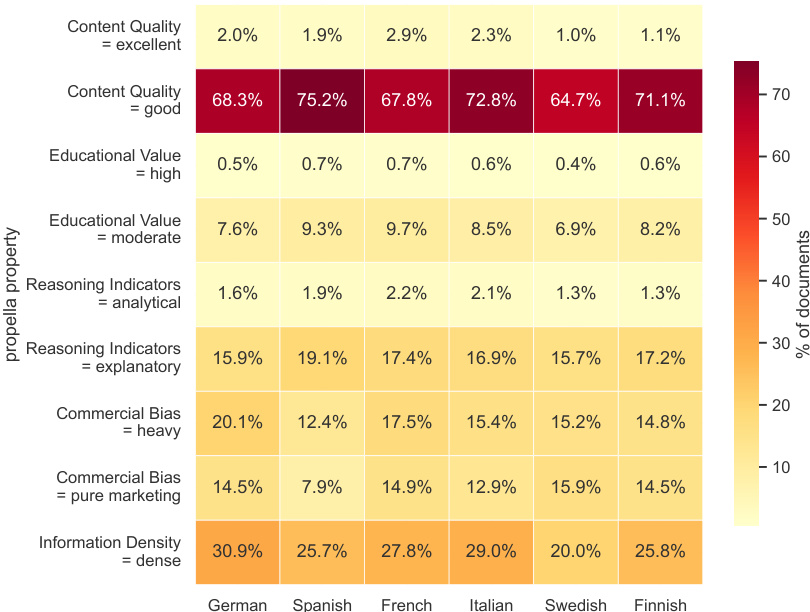
The heatmap visualizes the distribution of annotated document properties across six languages, demonstrating the system's multilingual consistency. The data reveals that "good" content quality is the overwhelming majority category, while other properties like commercial bias and information density show distinct distribution patterns across different languages. Content quality rated as "good" is the dominant category across all languages, significantly exceeding "excellent" ratings. Information density classified as "dense" represents a larger share of documents than moderate educational value. Commercial bias labeled as "heavy" is generally more prevalent than bias labeled as "pure marketing".
The experiments evaluate the propella-1 model family's annotation quality and serving efficiency across different precisions and hardware configurations. Results indicate that fp8 precision maintains performance comparable to bf16 while significantly boosting throughput on H100 GPUs, and the annotated dataset covers 57 languages with English as the predominant category. Additionally, quality audits reveal that higher data tiers generally exhibit better content but still contain specific issues like commercial bias and fragmented integrity that single-score classifications fail to capture, while consistency checks confirm good content quality is the dominant category across languages.