Command Palette
Search for a command to run...
A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces
A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces
Mingxuan Du Benfeng Xu Chiwei Zhu Shaohan Wang Pengyu Wang Xiaorui Wang Zhendong Mao
Abstract
Frontier language models have demonstrated strong reasoning and long-horizon tool-use capabilities. However, existing RAG systems fail to leverage these capabilities. They still rely on two paradigms: (1) designing an algorithm that retrieves passages in a single shot and concatenates them into the model's input, or (2) predefining a workflow and prompting the model to execute it step-by-step. Neither paradigm allows the model to participate in retrieval decisions, preventing efficient scaling with model improvements. In this paper, we introduce A-RAG, an Agentic RAG framework that exposes hierarchical retrieval interfaces directly to the model. A-RAG provides three retrieval tools: keyword search, semantic search, and chunk read, enabling the agent to adaptively search and retrieve information across multiple granularities. Experiments on multiple open-domain QA benchmarks show that A-RAG consistently outperforms existing approaches with comparable or lower retrieved tokens, demonstrating that A-RAG effectively leverages model capabilities and dynamically adapts to different RAG tasks. We further systematically study how A-RAG scales with model size and test-time compute. We will release our code and evaluation suite to facilitate future research. Code and evaluation suite are available at https://github.com/Ayanami0730/arag.
One-sentence Summary
Researchers from USTC and Metastone Technology propose A-RAG, an agentic RAG framework with hierarchical retrieval tools (keyword_search, semantic_search, chunk_read) that enable LLMs to autonomously adapt search strategies across granularities, outperforming prior methods on multi-hop QA benchmarks while using fewer tokens and scaling efficiently with model size and test-time compute.
Key Contributions
- A-RAG addresses the limitation of static RAG systems by enabling LLMs to dynamically control retrieval through hierarchical tools—keyword_search, semantic_search, and chunk_read—allowing adaptive, multi-granularity information gathering aligned with the model’s reasoning process.
- Evaluated on open-domain QA benchmarks, A-RAG consistently outperforms prior methods while using comparable or fewer retrieved tokens, validating that agent-driven retrieval leverages model capabilities more effectively than predefined workflows or single-shot retrieval.
- Systematic scaling experiments show A-RAG’s performance improves with larger models and increased test-time compute, demonstrating its efficiency in scaling alongside advances in LLM capabilities and computational resources.
Introduction
The authors leverage the growing reasoning and tool-use capabilities of frontier LLMs to rethink Retrieval-Augmented Generation (RAG), which has historically relied on static, algorithm-driven retrieval or rigid, predefined workflows that limit model autonomy. Prior approaches—including Graph RAG and Workflow RAG—fail to let the model dynamically adapt its retrieval strategy based on context or task complexity, preventing efficient scaling with model improvements. The authors’ main contribution is A-RAG, an agentic framework that exposes hierarchical retrieval tools (keyword_search, semantic_search, chunk_read) directly to the model, enabling it to autonomously navigate information at multiple granularities. Experiments show A-RAG outperforms existing methods with fewer retrieved tokens and scales effectively with model size and test-time compute, proving that agent-driven retrieval interfaces are more powerful than fixed retrieval algorithms.
Dataset

- The authors use only publicly available benchmarks previously curated and processed by prior research, ensuring ethical compliance.
- No new data is collected, and no human subjects are involved in this work.
- The focus is on advancing retrieval-augmented generation (RAG) in large language models, with no added ethical risks beyond those already present in the base models.
- Dataset composition and processing follow established practices from prior studies, without introducing novel filtering, cropping, or metadata construction steps.
Method
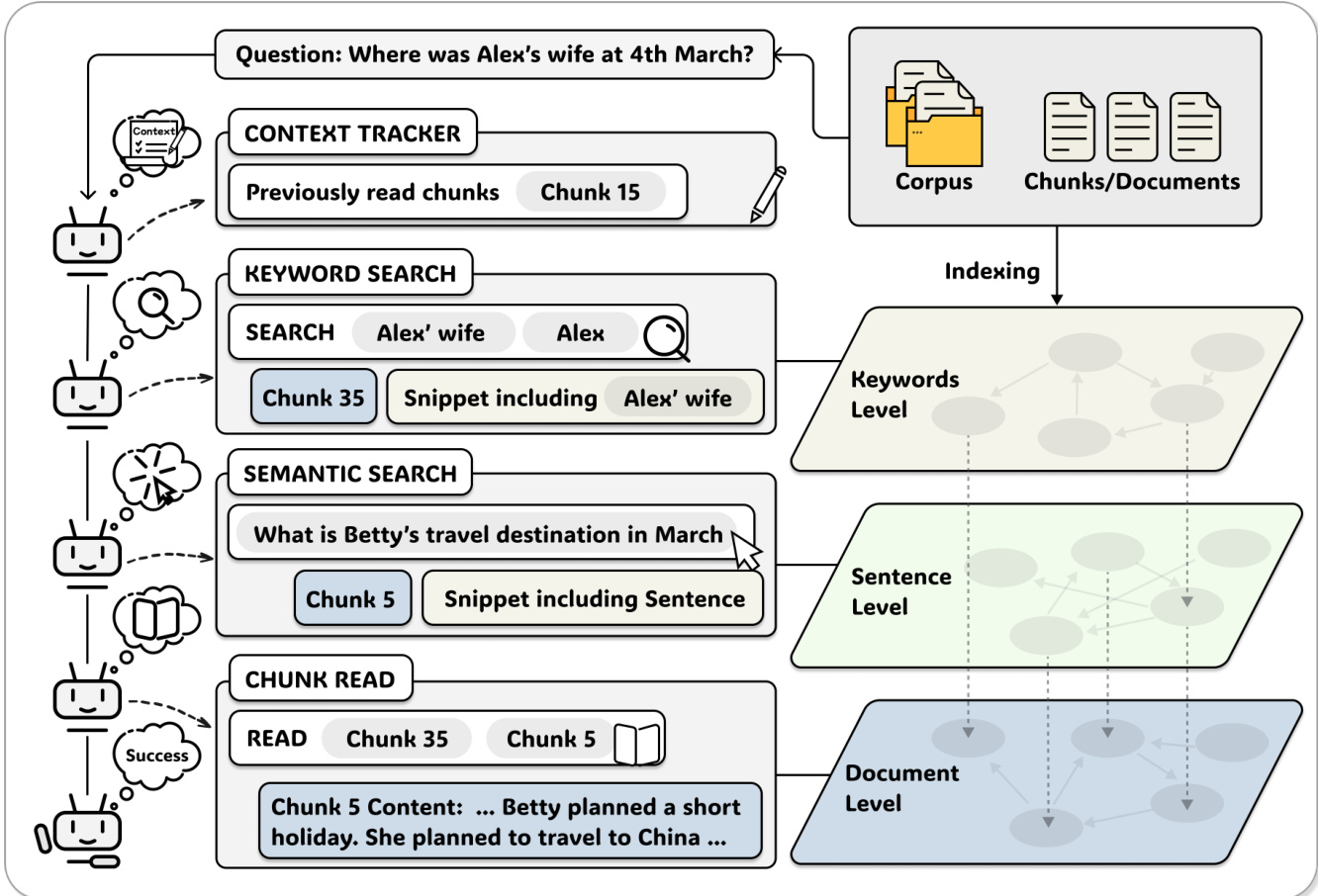
The authors leverage a minimalist yet powerful agent-centric architecture called A-RAG, which exposes hierarchical retrieval interfaces to enable autonomous, iterative information gathering. The framework is built around three core components: a lightweight hierarchical index, a suite of granular retrieval tools, and a simple ReAct-style agent loop that facilitates dynamic strategy selection and interleaved tool use.
The hierarchical index is constructed in two stages: chunking and embedding. The corpus is partitioned into approximately 1,000-token chunks aligned with sentence boundaries to preserve semantic coherence. Each chunk is then decomposed into constituent sentences, and each sentence is embedded using a pre-trained encoder femb, yielding vector representations vi,j=femb(si,j). This sentence-level embedding enables fine-grained semantic matching while preserving the mapping to parent chunks. Crucially, keyword-level retrieval is handled at query time via exact text matching, avoiding costly offline indexing. This yields a three-tiered representation: implicit keyword-level for precise entity matching, sentence-level for semantic search, and chunk-level for full content access.
To interface with this index, the authors design three retrieval tools operating at different granularities. The keyword search tool accepts a list of keywords K={k1,k2,…,km} and returns top-k chunks ranked by a weighted frequency score:
Scorekw(ci,K)=k∈K∑count(k,Ti)⋅∣k∣where longer keywords are weighted higher for specificity. For each matched chunk, it returns an abbreviated snippet containing only sentences that include at least one keyword:
Snippet(ci,K)={s∈Sent(ci)∣∃k∈K,k⊆s}The semantic search tool encodes the natural language query q into a vector vq=femb(q) and computes cosine similarity with all sentence embeddings:
Scoresem(si,j,q)=∥vi,j∥∥vq∥vi,jTvqIt aggregates results by parent chunk, returning the top-k chunks along with their highest-scoring sentences as snippets. Finally, the chunk read tool allows the agent to access the full text of any chunk identified via prior searches, including adjacent chunks for context expansion.
The agent loop is intentionally kept simple to isolate the impact of the interface design. It follows a ReAct-like pattern: at each iteration, the LLM receives the message history and available tools, then decides whether to call a tool or produce a final answer. A context tracker maintains a set Cread of previously accessed chunks; if the agent attempts to re-read a chunk, the tool returns a zero-token notification to prevent redundancy and encourage exploration. The loop terminates when an answer is produced or a maximum iteration budget is reached, at which point the agent is prompted to synthesize a response from accumulated evidence.
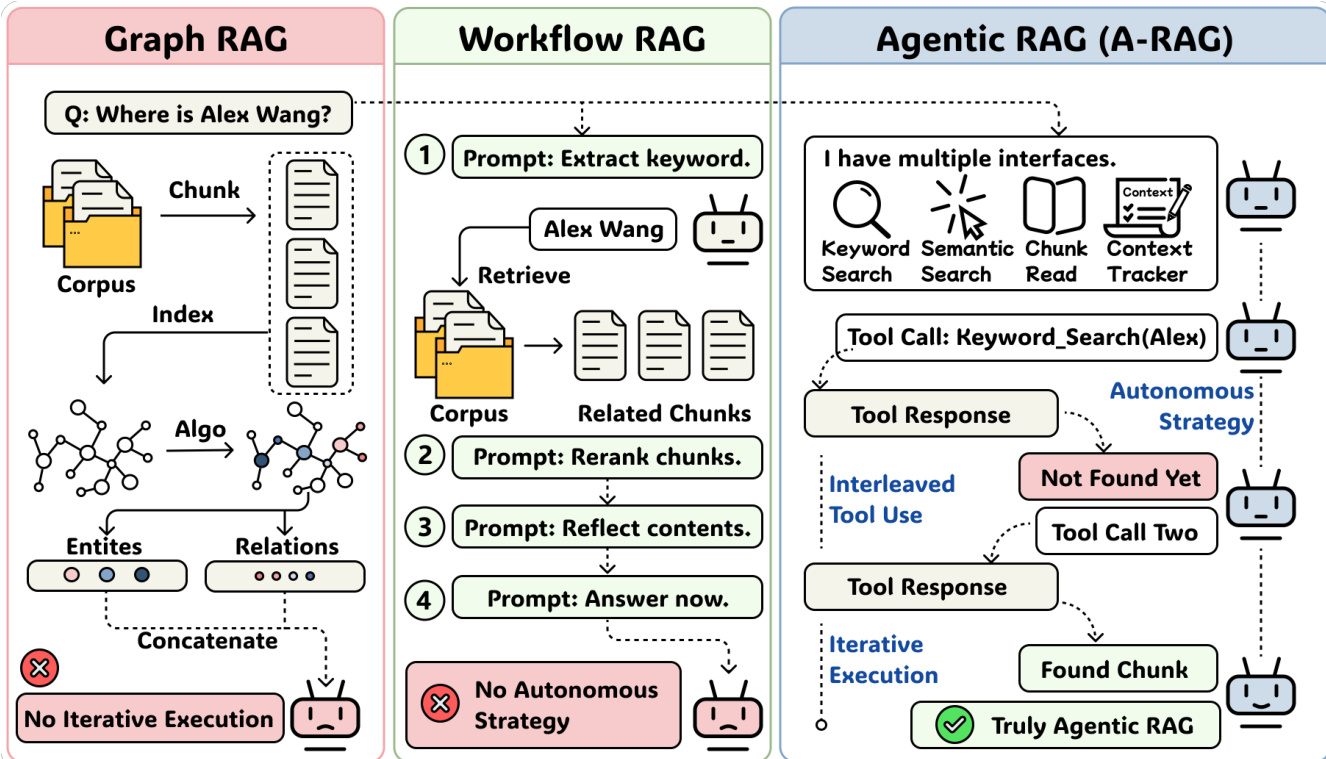
This architecture enables true agentic behavior: the agent autonomously selects retrieval strategies, iterates based on intermediate results, and conditions each tool call on prior observations. Unlike fixed workflows or graph-based systems, A-RAG does not prescribe a rigid sequence of operations. Instead, it provides a flexible interface that allows the agent to dynamically decompose questions, verify findings, and re-plan as needed — all while minimizing context overhead through on-demand, incremental retrieval.
Experiment
- A-RAG is validated as the only RAG paradigm satisfying all three principles of true agentic autonomy, distinguishing it from Graph RAG and Workflow RAG.
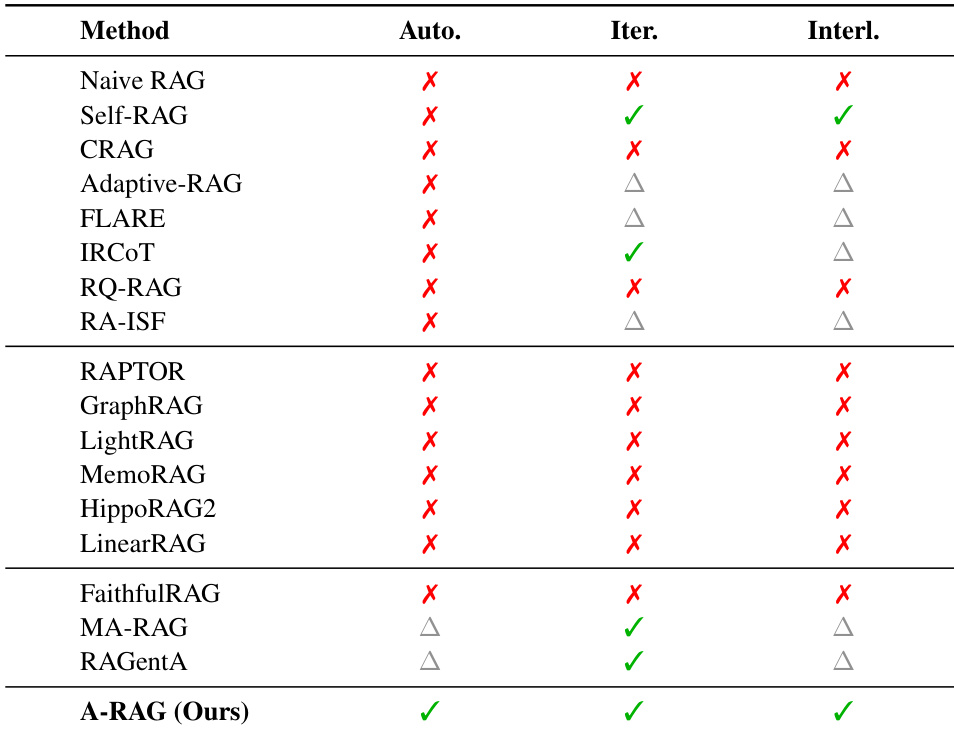
- Across four multi-hop QA benchmarks, A-RAG (Full) consistently outperforms vanilla, graph-based, and workflow-based RAG methods, especially when paired with stronger LLMs like GPT-5-mini.
- Ablation studies confirm that A-RAG’s hierarchical retrieval tools—semantic search, keyword search, and chunk read—are interdependent; removing any degrades performance, underscoring the value of multi-granularity and progressive information access.
- Test-time scaling experiments show A-RAG effectively leverages increased computational budget (steps and reasoning effort), with stronger models benefiting more, positioning it as a scalable paradigm.
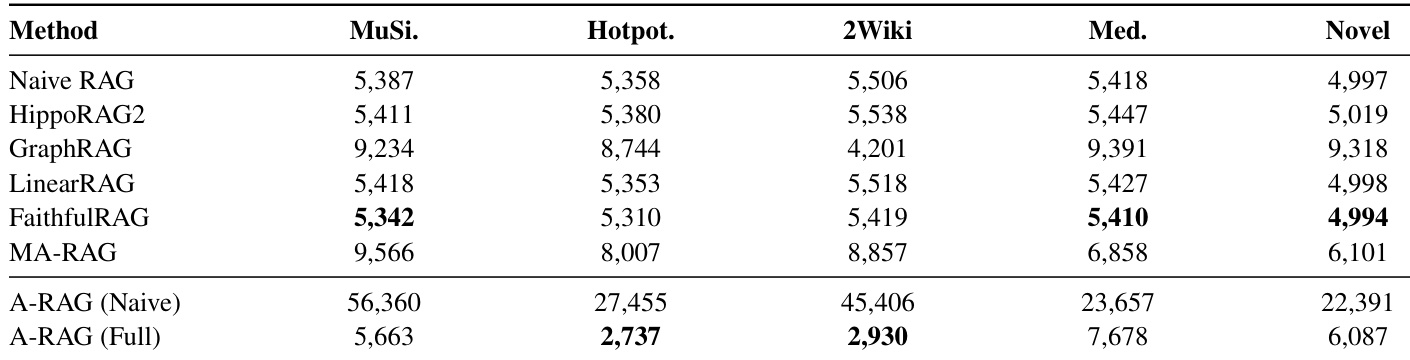
- A-RAG achieves higher accuracy while retrieving fewer tokens than traditional RAG methods, demonstrating superior context efficiency enabled by its hierarchical interface design.
- Failure analysis reveals a paradigm shift: while Naive RAG fails primarily due to retrieval limitations, A-RAG’s main bottleneck is reasoning chain errors—particularly entity confusion—indicating future work should focus on improving reasoning fidelity over retrieval coverage.
The authors evaluate A-RAG’s ablation variants and find that removing any retrieval tool—keyword search, semantic search, or chunk read—consistently degrades performance, confirming that multi-granularity access and progressive information disclosure are critical for effective multi-hop reasoning. A-RAG (Full) achieves the highest scores across most metrics, demonstrating that hierarchical tool interfaces enable models to autonomously select and refine relevant context while avoiding noise from irrelevant content.

The authors use A-RAG to evaluate context efficiency across methods, measuring retrieved tokens under a GPT-5-mini backbone. Results show A-RAG (Full) achieves higher accuracy while retrieving fewer or comparable tokens than traditional RAG methods, indicating superior context utilization. The hierarchical interface design enables more selective and efficient retrieval, reducing noise from irrelevant content.
The authors use a unified evaluation framework to compare A-RAG against multiple RAG paradigms across four multi-hop QA benchmarks, finding that A-RAG consistently outperforms both vanilla and structured RAG methods, especially when paired with stronger reasoning models like GPT-5-mini. Results show that granting models autonomy to dynamically select retrieval tools leads to better performance than fixed retrieval pipelines, even with minimal tooling. The full A-RAG configuration further improves outcomes by enabling progressive, multi-granularity information access, demonstrating that hierarchical interfaces enhance both accuracy and context efficiency.
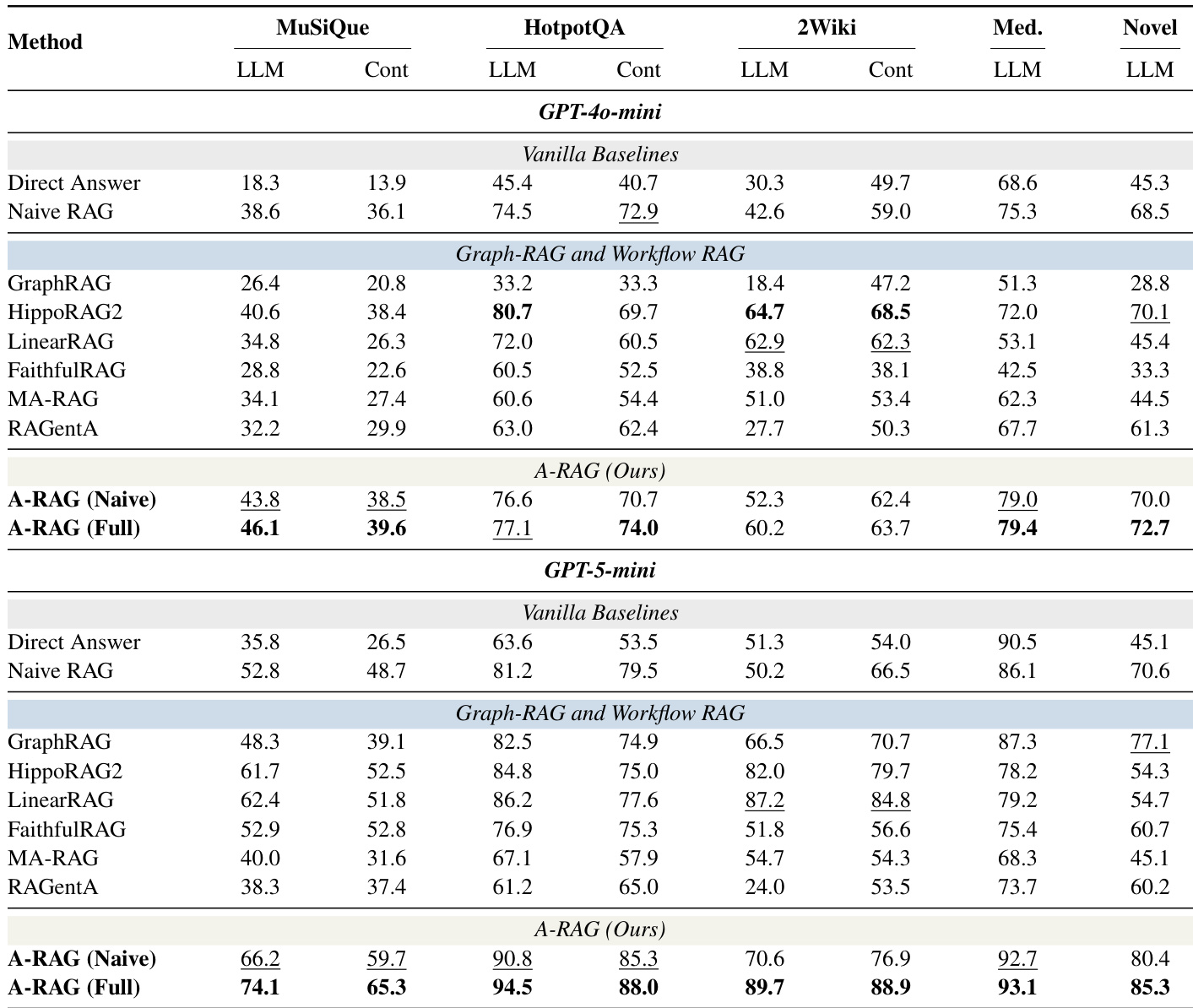
The authors use a comparative table to position their proposed A-RAG method against existing RAG approaches, highlighting its unique support for autonomy, iterative reasoning, and interleaved tool use. Results show that A-RAG is the only method satisfying all three principles of true agentic autonomy, distinguishing it from prior paradigms that lack one or more of these capabilities. This structural advantage enables A-RAG to dynamically adapt retrieval strategies, contributing to its superior performance across benchmarks.
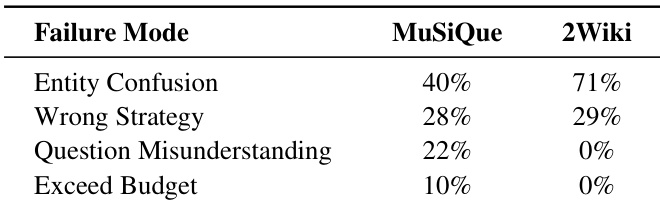
The authors analyze failure modes in A-RAG and find that reasoning chain errors dominate, with entity confusion being the most frequent subcategory—accounting for 40% of errors on MuSiQue and 71% on 2WikiMultiHopQA. This indicates that while A-RAG successfully retrieves relevant documents, the model often struggles to correctly interpret or disambiguate entities within them. The distribution of errors also varies by dataset, suggesting task-specific challenges in question understanding and strategy selection.