Command Palette
Search for a command to run...
Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
Abstract
We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
One-sentence Summary
Researchers from Shanghai Jiao Tong University, DP Technology, and collaborators propose Innovator-VL, a data-efficient, transparent multimodal LLM that achieves strong scientific and general vision performance using under 5M curated samples, challenging the need for massive domain-specific pretraining while enabling reproducible, scalable scientific AI.
Key Contributions
- Innovator-VL introduces a fully transparent, end-to-end reproducible training pipeline for scientific multimodal modeling, covering data curation, fine-tuning, reinforcement learning, and evaluation with detailed hyperparameter recipes to enable community replication and extension.
- The model achieves competitive scientific reasoning performance using fewer than five million curated samples, demonstrating that data efficiency and principled training design can substitute for large-scale domain-specific pretraining.
- Innovator-VL maintains strong generalization across general vision, multimodal reasoning, and scientific benchmarks, proving that scientific alignment can be integrated without sacrificing broad multimodal capabilities.
Introduction
The authors leverage a principled, transparent training pipeline to build Innovator-VL, a multimodal large language model that excels in scientific reasoning while retaining strong general vision capabilities. Prior scientific MLLMs often rely on massive domain-specific datasets and opaque training methods, limiting reproducibility and generalization—many also sacrifice broad multimodal performance for scientific gains. Innovator-VL addresses this by achieving competitive results across scientific and general benchmarks using fewer than five million curated samples, without scientific pretraining, and introduces structured visual encoding and reinforcement learning to enhance reasoning fidelity. Its unified design proves that scientific alignment and general-purpose utility can coexist, offering a reproducible, data-efficient foundation for future scientific AI research.
Dataset

The authors use a multi-stage, multimodal dataset pipeline to train and evaluate Innovator-VL, combining general instruction data, reasoning-focused corpora, scientific domain datasets, and RL-specific samples. Here’s a breakdown:
-
General Multimodal Instruction Data:
Uses LLaVA-OneVision-1.5-Instruct (~22M samples), curated across categories like Caption, Chart & Table, Code & Math, VQA, Grounding, and OCR. Designed for balanced coverage and validated by strong benchmark performance. -
Chain-of-Thought & Multi-step Reasoning Data:
Integrates Honey-Data-15M (~15M samples), a reasoning-oriented dataset spanning diverse domains. The authors remove explicit “think” tags to avoid templated noise, preserving natural reasoning structure while improving robustness. -
Scientific Understanding Data:
Synthesizes high-quality datasets across three domains via structured pipelines:- In-the-wild OCSR: Uses E-SMILES format (SMILES〈sep〉EXTENSION) for complex chemical structures. Combines 7M synthetic samples with real patent/paper PDFs via active learning, human-in-the-loop correction, and ensemble confidence scoring.
- Chemical Reaction Understanding: Extracts reaction schemes from PDFs with layout parsing and cropping. QA pairs are model-generated then expert-refined; includes adversarial distractors and “None of the Above” options to reduce hallucinations.
- Microstructural Characterization (EM): Aggregates real EM images, crops non-structural regions, and annotates with a 9D attribute schema. Uses iterative human-in-the-loop workflows for segmentation and description, with cross-validation and expert adjudication.
-
RL Training Data (Innovator-VL-RL-172K):
Curated via discrepancy-driven selection: retains samples where Pass@N is high but Pass@1 is low (indicating policy misalignment). Filters by reward score to keep medium-difficulty items. Standardizes all samples into unified reasoning format. Composition: 56.4% STEM & Code, 34.9% General multimodal, plus smaller subsets for Science (5.0%), Spatial (2.4%), Grounding (0.9%), Counting (0.2%), OCR & Diagram (0.2%). -
Processing & Metadata:
- Cropping applied to EM data (remove watermarks/text) and PDFs (retain titles/labels).
- E-SMILES format used for chemical structures, enabling RDKit compatibility and sequence modeling.
- Expert verification, ensemble scoring, and iterative retraining loops ensure data quality across scientific domains.
- All RL samples standardized for step-wise reasoning output to stabilize training.
-
Evaluation Benchmarks:
Tested across 3 dimensions:- General Vision: AI2D, OCRBench, ChartQA, MMMU, MMStar, VStar-Bench, MMBench, MME-RealWorld, DocVQA, InfoVQA, SEED-Bench, SEED-Bench-2-Plus, RealWorldQA.
- Math & Reasoning: MathVista, MathVision, MathVerse, WeMath.
- Science: ScienceQA, RxnBench, MolParse, OpenRxn, EMVista, SmolInstruct, SuperChem, ProteinLMBench, SFE, MicroVQA, MSEarth-MCQ, XLRS-Bench.
This structured, multi-source approach enables the model to develop broad multimodal capabilities while specializing in complex scientific and reasoning tasks.
Method
The authors leverage a three-stage architecture for Innovator-VL, following the established paradigm of vision encoder-projector-language model, which effectively bridges visual and textual modalities. The overall framework integrates a vision encoder, a projector, and a language model to enable multimodal understanding and reasoning. Refer to the framework diagram for a visual overview of the model's structure and data flow.
The vision encoder component is based on RICE-ViT, a Vision Transformer variant designed for region-aware representation learning. Unlike models that focus solely on global patch interactions, RICE-ViT incorporates a specialized Region Transformer layer to capture both holistic and localized visual cues. This capability is crucial for scientific imagery, which often contains fine-grained structures and spatially localized patterns. The region-aware cluster discrimination mechanism in RICE-ViT enhances semantic embedding by jointly optimizing object and OCR region representations, thereby improving performance on tasks such as grounding and dense prediction. By adopting RICE-ViT, Innovator-VL gains a robust visual representation capacity aligned with the demands of scientific multimodal understanding.
To bridge the visual encoder and the language model, Innovator-VL employs a learned token compression module called PatchMerger. This module addresses the quadratic computational cost associated with processing dense visual tokens from the Vision Transformer. By learning to merge a larger set of input patch embeddings into a smaller set of representative tokens, PatchMerger significantly reduces the sequence length that downstream components must process, leading to substantial reductions in computational complexity and memory usage. This compression facilitates more efficient cross-modal interaction with the language model without compromising the richness of visual representations, which is particularly beneficial when training on limited scientific datasets. The PatchMerger module is positioned between the vision encoder and the language model, as shown in the framework diagram.
For the language modeling and reasoning component, the authors adopt Qwen3-8B-Base, a large language model pretrained on a diverse corpus spanning multiple domains and languages. Qwen3-8B-Base demonstrates strong performance in STEM, logical reasoning, and long-context understanding, making it well-suited for scientific multimodal tasks that require integrating textual and visual information. Its open-source nature and mature tooling ecosystem also align with the goal of creating a fully transparent and reproducible scientific multimodal large language model.
The pre-training process for Innovator-VL consists of two stages. The first stage, Language-Image Alignment, involves pretraining the projector to align visual features with the word embedding space of the LLM. This stage uses the LLaVA-1.5 558k dataset. The second stage, High-quality Mid-Training, transitions to full-parameter training across all modules. This stage utilizes the LLaVA-OneVision-1.5-Mid-Training dataset, a large-scale multimodal corpus of approximately 85 million high-quality image-text pairs. The dataset is curated from diverse sources and employs a feature-based concept-balanced sampling strategy to ensure semantic diversity and balance, which facilitates robust visual-language alignment.
Following pre-training, Innovator-VL undergoes staged post-training to refine its capabilities. This includes supervised fine-tuning and reinforcement learning. The supervised fine-tuning stage aims to enhance the model's instruction-following ability, multi-step reasoning, and scientific understanding. The reinforcement learning stage further strengthens the model's multimodal reasoning and its capacity to tackle complex scientific problems. The training pipeline is supported by a high-performance distributed training framework, which employs advanced optimization strategies to maximize computational throughput and memory efficiency.
Experiment
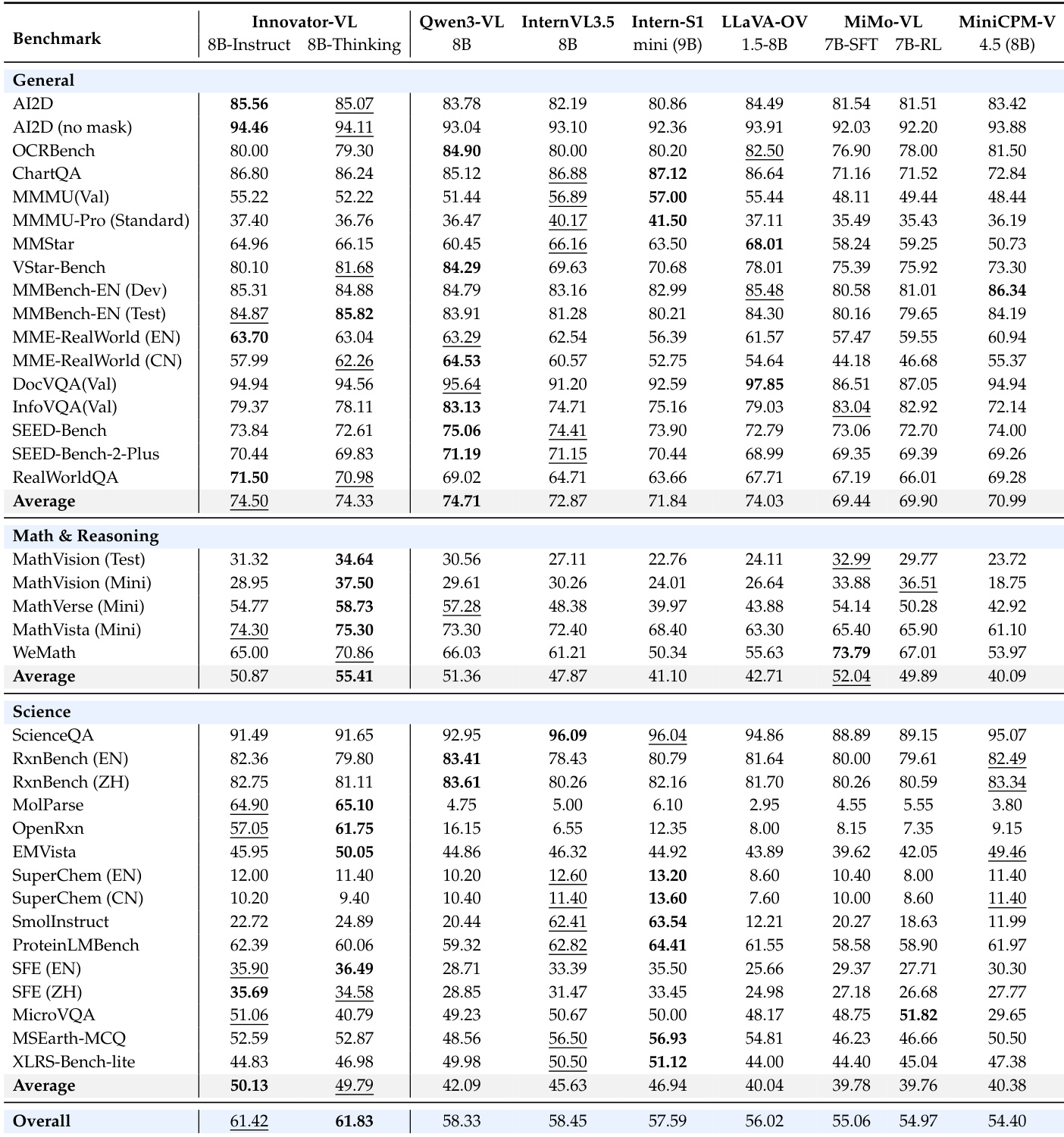
- Innovator-VL-8B-Thinking achieves SOTA average score of 61.83% across 37 benchmarks, outperforming comparable 7B–9B models including Qwen3-VL-8B, InternVL3.5-8B, and MiMo-VL-7B.
- Innovator-VL-8B-Instruct scores 74.50% on general multimodal tasks, matching Qwen3-VL-8B and leading on MME-RealWorld, AI2D, and RealWorldQA.
- Innovator-VL-8B-Thinking excels in math & reasoning (55.41%), a 4.54% gain over its instruct variant, surpassing all peers via RL-enhanced reasoning.
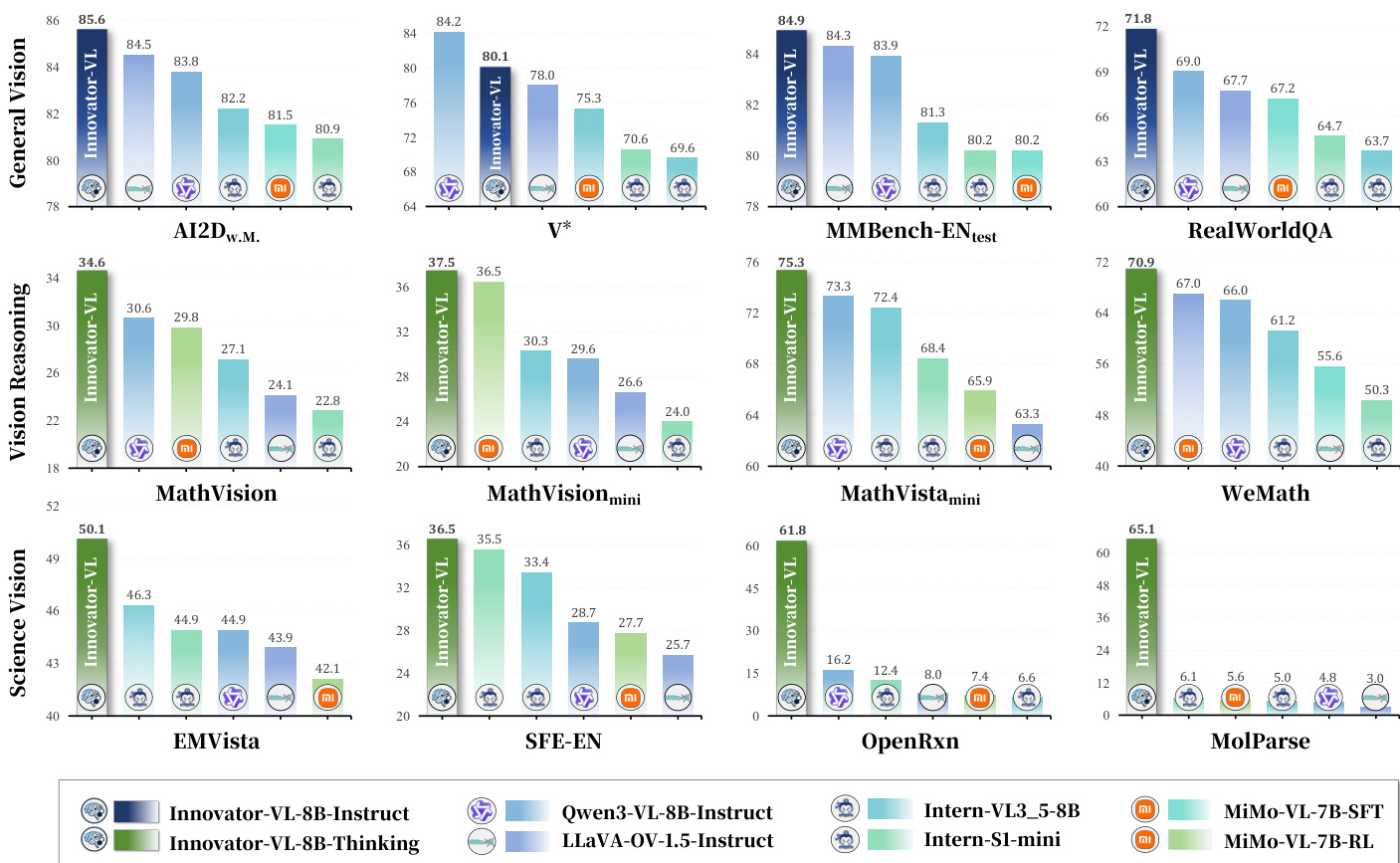
- In scientific domains, Innovator-VL secures top two average scores (50.13%, 49.79%), with standout performance on chemistry tasks (e.g., 57% on OpenRxn, 64% on MolParse vs. <17% for others).
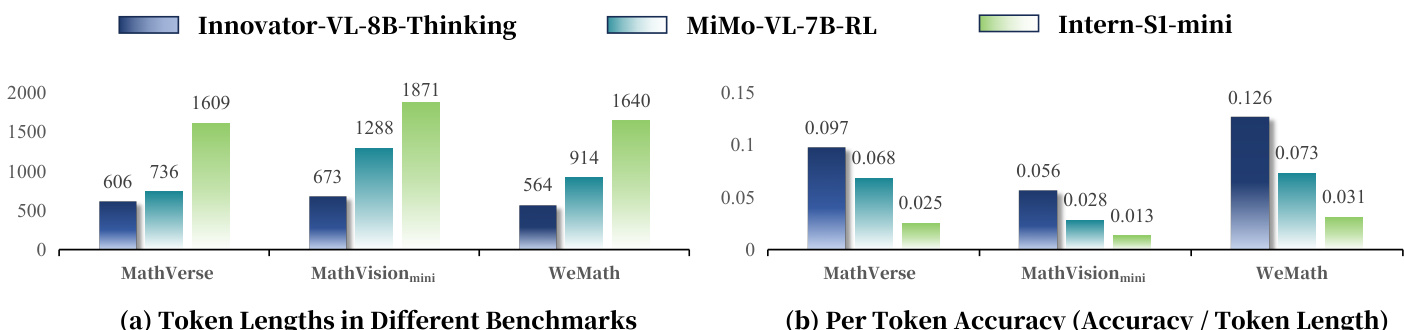
- Innovator-VL-8B-Thinking generates 62–66% fewer tokens than Intern-S1-mini and 18–48% fewer than MiMo-VL-7B-RL, while achieving 1.4–4.3× higher accuracy-to-token ratios, demonstrating superior reasoning efficiency.
- Qualitative cases confirm robustness: correct answers on visual QA, complex geometry, chemistry notation, and scientific diagnostics where baselines fail.
The authors use a multi-stage training process for Innovator-VL, starting with language-image alignment using a projector and LLaVA-1.5 dataset, followed by high-quality mid-training on a large-scale dataset, supervised fine-tuning, and finally reinforcement learning with a reasoning-focused dataset. This structured approach enables the model to achieve strong performance across general, mathematical, and scientific benchmarks while maintaining high reasoning efficiency.

The authors use Innovator-VL-8B-Thinking to achieve state-of-the-art performance across general, mathematical, and scientific benchmarks, with an overall average score of 61.83%, surpassing all comparable models. Results show that Innovator-VL-8B-Thinking significantly outperforms other models in scientific domains, particularly in chemistry tasks like OpenRxn and MolParse, while also demonstrating superior reasoning efficiency with shorter reasoning chains and higher accuracy-to-token ratios.
The authors use Innovator-VL-8B-Thinking to achieve state-of-the-art performance across multiple benchmarks, with the model attaining the highest scores in general vision, mathematical reasoning, and scientific domains. Results show that Innovator-VL-8B-Thinking outperforms all compared models, particularly excelling in specialized scientific tasks such as OpenRxn and MolParse, where it achieves scores exceeding 57% and 64% respectively, while other models fail to surpass 17%.
The authors use the table to compare the token efficiency of Innovator-VL-8B-Thinking, MiMo-VL-7B-RL, and Intern-S1-mini across vision reasoning benchmarks. Results show that Innovator-VL-8B-Thinking generates significantly shorter reasoning chains, consuming approximately 62% to 66% fewer tokens than Intern-S1-mini and 18% to 48% fewer than MiMo-VL-7B-RL, while achieving a higher accuracy-to-token ratio, indicating superior reasoning efficiency.