Command Palette
Search for a command to run...
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Abstract
Recent video generation models demonstrate remarkable ability to capture complex physical interactions and scene evolution over time. To leverage their spatiotemporal priors, robotics works have adapted video models for policy learning but introduce complexity by requiring multiple stages of post-training and new architectural components for action generation. In this work, we introduce Cosmos Policy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications. Cosmos Policy learns to directly generate robot actions encoded as latent frames within the video model's latent diffusion process, harnessing the model's pretrained priors and core learning algorithm to capture complex action distributions. Additionally, Cosmos Policy generates future state images and values (expected cumulative rewards), which are similarly encoded as latent frames, enabling test-time planning of action trajectories with higher likelihood of success. In our evaluations, Cosmos Policy achieves state-of-the-art performance on the LIBERO and RoboCasa simulation benchmarks (98.5% and 67.1% average success rates, respectively) and the highest average score in challenging real-world bimanual manipulation tasks, outperforming strong diffusion policies trained from scratch, video model-based policies, and state-of-the-art vision-language-action models fine-tuned on the same robot demonstrations. Furthermore, given policy rollout data, Cosmos Policy can learn from experience to refine its world model and value function and leverage model-based planning to achieve even higher success rates in challenging tasks. We release code, models, and training data at https://research.nvidia.com/labs/dir/cosmos-policy/
One-sentence Summary
Researchers from NVIDIA and Stanford introduce Cosmos Policy, a robot policy fine-tuned from Cosmos-Predict2-2B via single-stage training, generating actions, future states, and values as latent frames without architectural changes, achieving state-of-the-art results in simulation and real-world bimanual tasks.
Key Contributions
- Cosmos Policy adapts the pretrained video model Cosmos-Predict2 into a robot policy via a single-stage fine-tuning on robot demonstration data, requiring no architectural changes and directly encoding actions as latent frames within the model’s diffusion process to leverage its spatiotemporal priors.
- It jointly predicts robot actions, future state images, and expected cumulative rewards as latent frames, enabling test-time planning through best-of-N sampling that selects high-value action trajectories, improving task success rates in both simulation and real-world bimanual manipulation.
- Evaluated on LIBERO (98.5% avg success) and RoboCasa (67.1% avg success) benchmarks and real-world tasks (93.6% avg success), it outperforms diffusion policies, video-based policies, and fine-tuned vision-language-action models, with further gains from model-based planning and experience-driven refinement.
Introduction
The authors leverage pretrained video generation models—which capture spatiotemporal dynamics and implicit physics—to build robot policies without modifying the model’s architecture. Prior approaches either require multiple training stages with custom action modules or train unified models from scratch, missing the benefit of pretrained video priors. Cosmos Policy fine-tunes a single video model in one stage to jointly generate robot actions, future states, and value predictions—all encoded as latent frames—enabling both direct control and model-based planning via best-of-N sampling. It achieves state-of-the-art performance across simulation and real-world bimanual tasks, and further improves with experience-driven refinement of its world model and value function.
Dataset

-
The authors use three distinct datasets: LIBERO (simulation), RoboCasa (simulation), and ALOHA (real-world), each targeting different robotic manipulation challenges.
-
LIBERO includes four task suites (Spatial, Object, Goal, Long) with 500 demonstrations total (10 tasks × 50 demos). For policy training, only successful demos are used; world model and value function training use all demos, filtered or not.
-
RoboCasa features 24 kitchen tasks with 50 human teleoperated demos per task. The authors train exclusively on these 50 human demos per task to evaluate data efficiency, filtering failures for policy training but retaining all for world model/value function training.
-
ALOHA comprises four bimanual real-world tasks: “put X on plate” (80 demos), “fold shirt” (15 demos), “put candies in bowl” (45 demos), and “put candy in ziploc bag” (45 demos). Policies receive proprioception, three camera views, and task descriptions, outputting 50-timestep action chunks.
-
All evaluations use fixed initial states for fair comparison. LIBERO results average 6000 trials (3 seeds × 10 tasks × 50 episodes); RoboCasa averages 3600 trials (24 tasks × 5 scenes × 10 trials × 3 seeds); ALOHA uses 101 total trials across tasks.
-
The authors reduce ALOHA’s control frequency from 50 Hz to 25 Hz for efficiency. No cropping is mentioned; metadata includes task descriptions, camera images, and joint states. Training splits follow benchmark protocols, with no additional data mixing or augmentation described.
Method
The authors leverage the pretrained Cosmos-Predict2-2B-Video2World model, a latent video diffusion model, as the foundation for Cosmos Policy. This model is initialized with a diffusion transformer architecture that operates over continuous tokens encoded by the Wan2.1 spatiotemporal VAE tokenizer. The core training objective for the denoiser network Dθ is formulated as an EDM denoising score matching problem, where the network learns to recover a clean VAE-encoded image sequence x0 from a corrupted version x0+n, conditioned on a textual description c and the noise level σ. The network conditions on the text via cross-attention and on the noise level via adaptive layer normalization. The Wan2.1 tokenizer compresses a video sequence of size (1+T)×H×W×3 into a latent sequence of size (1+T′)×H′×W′×16, where T′=T/4, H′=H/8, and W′=W/8. The first frame is preserved without temporal compression to allow conditioning on a single input image, and a conditioning mask ensures this initial frame remains clean during training.
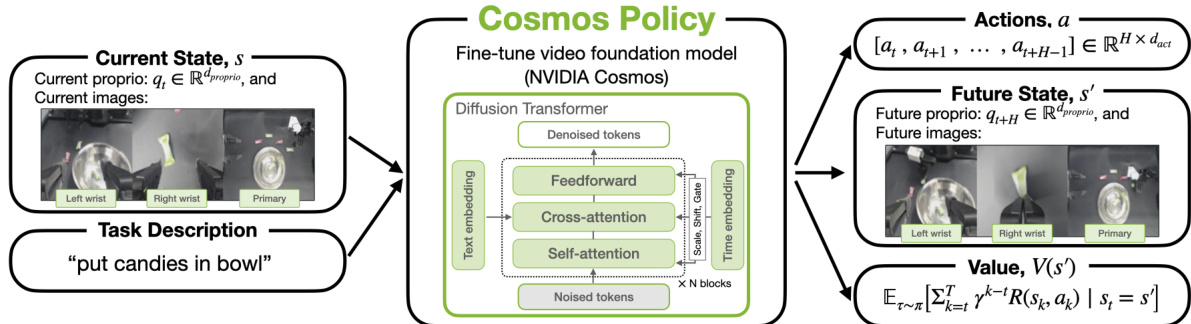
To adapt this video model for robotic control, the authors introduce a novel mechanism called latent frame injection, which allows the model to incorporate new modalities without architectural changes. This process involves inserting additional latent frames directly into the video model's latent diffusion sequence. For a robotic platform with multiple camera views and robot-specific data, the latent sequence is structured to include both image frames and non-image modalities. For instance, in a setup with two third-person cameras and a wrist-mounted camera, the sequence contains 11 latent frames: a blank placeholder, robot proprioception, wrist camera image, first third-person camera image, second third-person camera image, action chunk, future robot proprioception, future wrist camera image, future first third-person camera image, future second third-person camera image, and future state value. The new modalities—robot proprioception, action chunk, and state value—are encoded as latent frames by filling each H′×W′×C′ latent volume with normalized and duplicated copies of the respective modality data. This ordering of modalities in the sequence represents (s,a,s′,V(s′)), enabling autoregressive decoding of actions, future states, and future state values from left to right.
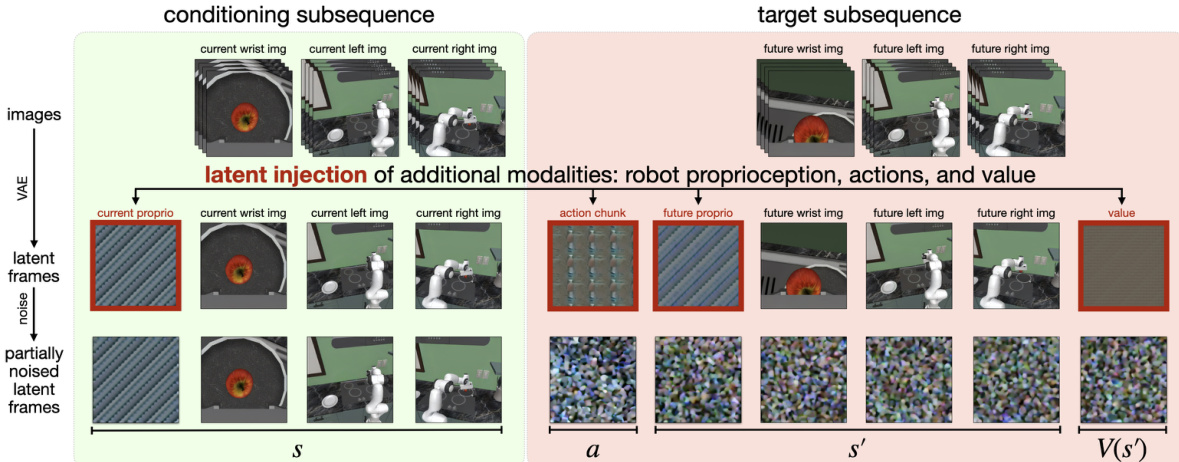
The model is trained on robot data to jointly learn a policy, a world model, and a value function. For each training step, a batch of (s,a,s′,V(s′)) tuples is sampled. Half of the batch is drawn from expert demonstrations to train the policy, which learns to predict the joint distribution p(a,s′,V(s′)∣s). The other half is sampled from a rollouts dataset and split to train the world model p(s′,V(s′)∣s,a) and the value function p(V(s′)∣s,a,s′). The conditioning scheme, which determines which parts of the latent sequence are used as input and which are the targets, dictates which function is being trained. The policy and world model training involve auxiliary targets, which improve performance. During initial training, the value function predictions are conditioned on the full latent prefix (s,a,s′). However, when fine-tuning on rollout data, the value generation can be conditioned on a subset of (s,a,s′) via input masking, allowing the value function to represent either the state value V(s′) or the state-action value Q(s,a).

The authors also modify the noise distribution used during training and inference to improve the accuracy of action predictions. The base model's log-normal noise distribution, which concentrates training weight at lower noise levels, is insufficient for the precise action generation required in robotics. To address this, they use a hybrid log-normal-uniform distribution that assigns greater weight to higher noise levels. This is implemented by sampling from the original log-normal distribution with probability 0.7 and from a uniform distribution over [1.0, 85.0] with probability 0.3. At inference time, they set a higher lower bound for the noise level, σmin=4, to avoid the low signal-to-noise ratio at very small noise levels, which empirically improves prediction accuracy for actions, future states, and values.
Experiment
- Cosmos Policy outperforms state-of-the-art imitation learning methods on LIBERO (98.5% success rate), RoboCasa (67.1% success rate with only 50 demonstrations), and real-world ALOHA tasks (highest overall score across four tasks), despite using fewer training samples than most comparators.
- Ablation studies confirm that auxiliary training objectives (joint prediction of actions, next states, and values) and video model priors are critical: removing them causes 1.5% and 3.9% absolute drops in success rate, respectively; training from scratch yields jerky, unsafe motions and 18.7-point lower score on “fold shirt.”
- With model-based planning using refined world models and V(s’) value functions, Cosmos Policy achieves a 12.5-point average score gain on challenging ALOHA tasks (“put candies in bowl” and “put candy in ziploc bag”), outperforming model-free Q(s,a) planning variants due to better leveraging of learned dynamics.
- Planning requires 4.9 seconds per action on 8 H100 GPUs, limiting real-time applicability; inference latency can be reduced to 0.16s per action chunk with only 0.5% success rate drop using 1 denoising step.
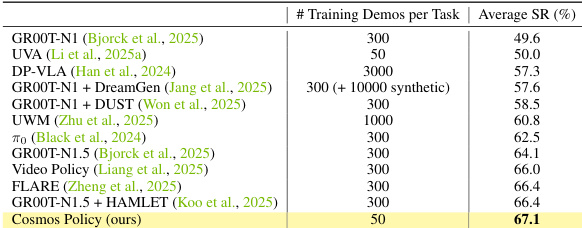
Results show that Cosmos Policy achieves the highest average success rate of 67.1% across 24 kitchen manipulation tasks in the RoboCasa benchmark, outperforming all compared methods while using significantly fewer training demonstrations (50 per task). The authors use this result to demonstrate that their approach establishes a new state of the art in multi-task manipulation performance with efficient data usage.
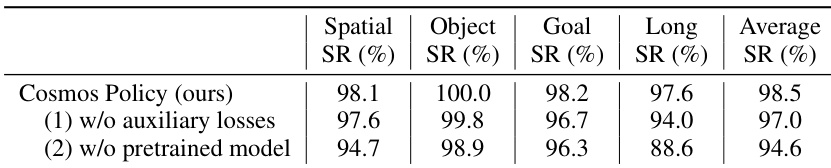
The authors use the table to evaluate the impact of auxiliary losses and pretrained models on Cosmos Policy's performance. Results show that removing auxiliary losses leads to a 1.5% drop in average success rate, while training without a pretrained model results in a 3.9% drop, indicating both components are important for optimal performance.
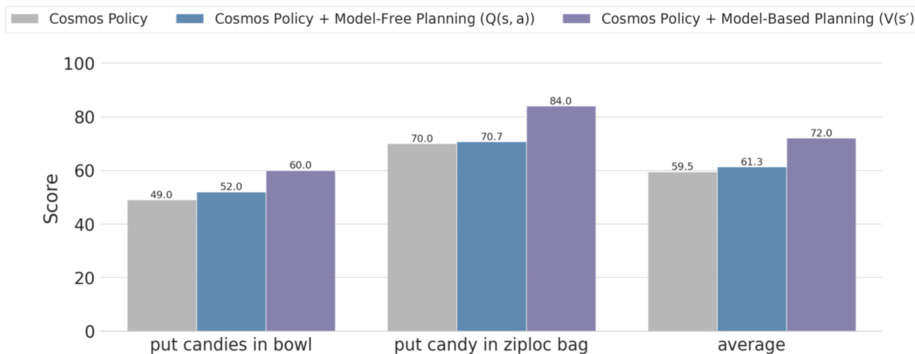
The authors evaluate Cosmos Policy with model-based planning on challenging ALOHA robot tasks, comparing model-based planning using a state value function V(s′) against model-free planning using a Q-value function Q(s,a). Results show that model-based planning with V(s′) achieves higher scores than both the base policy and the model-free variant, with an average score of 84.0 compared to 70.7 for model-free planning.
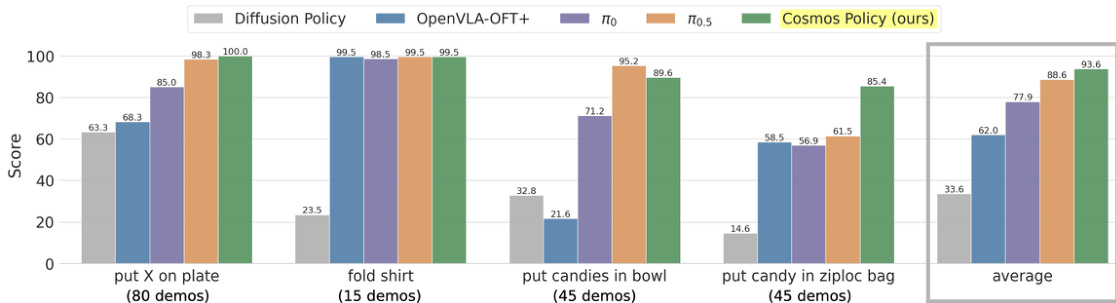
Results show that Cosmos Policy achieves the highest average score across all four ALOHA robot tasks, outperforming all compared methods in three of the four tasks. It attains the highest overall score of 93.6, significantly surpassing Diffusion Policy and OpenVLA-OFT+ in the "fold shirt" and "put candy in ziploc bag" tasks, while also achieving strong performance on the other two tasks.
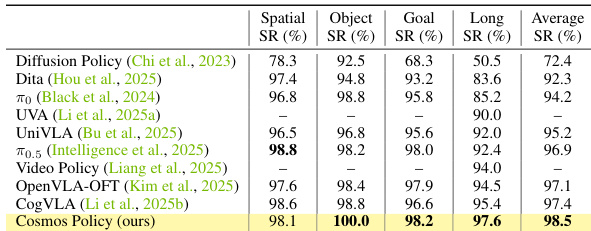
Results show that Cosmos Policy achieves the highest average success rate of 98.5% across all tasks in the LIBERO benchmark, outperforming all compared methods, including Diffusion Policy, Dita, and UVA, with particularly strong performance in the Object and Goal SR metrics. The authors use this table to demonstrate that Cosmos Policy sets a new state-of-the-art in imitation learning for multi-task manipulation tasks.