Command Palette
Search for a command to run...
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Abstract
The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
One-sentence Summary
The authors from Fudan University, Shanghai Qiji Zhifeng Co., Ltd., and Shanghai Innovation Institute propose ABC-Bench, a novel benchmark evaluating agentic back-end coding through end-to-end, executable workflows that require full lifecycle management from code exploration to containerized service deployment across 8 languages and 19 frameworks, revealing significant gaps in current LLMs' real-world engineering capabilities despite state-of-the-art performance in static code tasks.
Key Contributions
- Current benchmarks for AI coding agents focus on static, localized code edits and fail to capture the dynamic, end-to-end requirements of real-world back-end development, which involves environment configuration, service deployment, and integration testing.
- ABC-Bench introduces a scalable, automated pipeline to generate 224 realistic backend tasks across 8 languages and 19 frameworks, requiring agents to complete the full development lifecycle—from repository exploration to deploying containerized services and passing external API tests.
- Evaluation shows even top-performing models achieve only a 63.2% pass@1 rate, with environment setup and deployment emerging as critical bottlenecks, revealing a significant gap between current agent capabilities and practical engineering demands.
Introduction
The authors leverage the growing trend of LLMs as autonomous agents in software engineering to address a critical gap in evaluating backend development capabilities. While prior benchmarks focus on isolated code edits within static or sandboxed environments, they fail to capture the full, dynamic workflow of real-world backend engineering—where code changes must be integrated with environment setup, containerization, deployment, and end-to-end API validation. This disconnect limits the reliability of current evaluations, as models often succeed in logic but fail in execution due to misconfigurations or deployment issues. To bridge this gap, the authors introduce ABC-Bench, a scalable, production-like benchmark that requires agents to complete the entire backend development lifecycle—from repository analysis to running containerized services and passing external API tests. Built via an automated pipeline from 2,000 real open-source repositories, ABC-Bench includes 224 tasks across 8 languages and 19 frameworks, ensuring realistic diversity. Evaluation reveals that even top models achieve only a 63.2% pass rate, with environment configuration and deployment emerging as dominant failure points, highlighting a substantial capability gap between current agents and practical engineering demands.
Dataset

- ABC-Bench consists of 224 tasks derived from 127 public GitHub repositories licensed under the MIT license, ensuring compliance with open-source terms and avoiding proprietary or unclear-licensed code.
- The dataset spans 8 programming languages and 19 backend frameworks, with tasks covering real-world domains such as data analytics, search systems, commerce platforms, payment gateways, and developer tooling.
- Of the 224 tasks, 132 focus on logic implementation within a pre-provisioned runtime, while 92 require autonomous environment configuration and containerized service startup, testing end-to-end operational capability.
- Tasks were initially generated as 600 candidates and filtered to ensure balanced representation across languages, frameworks, and task types, resulting in a high-quality, diverse benchmark.
- During construction, automated pipelines process repository snapshots, with sensitive credentials (e.g., API keys, tokens, private keys) detected and redacted to protect privacy. Personal or demographic data, logs, and offensive content are excluded.
- The dataset is constructed without human annotation or crowdwork; only internal manual verification by the research team was performed on task titles and descriptions for quality assurance.
- The authors use the dataset in a training and evaluation setup where tasks are split into training and test sets, with mixture ratios designed to reflect the distribution of languages, frameworks, and task types.
- For tasks requiring containerization, the model must generate a Dockerfile in the project root directory that successfully builds and runs the application, with specific requirements including dependency installation and correct file structure.
- Metadata is constructed automatically from repository and task-level information, with no external human involvement, and all data processing is designed to preserve technical fidelity while ensuring privacy and ethical compliance.
Method
The authors leverage the ABC-Pipeline, an automated workflow designed to generate realistic backend development tasks at scale by transforming open-source repositories into full-lifecycle benchmark tasks. The pipeline operates in three distinct phases: Repository Exploration, Environment Setup & Verification, and Task Instantiation.
In the first phase, Repository Exploration, the pipeline begins by filtering a pool of 2,000 open-source, MIT-licensed repositories to identify high-quality backend candidates. An autonomous agent then explores each repository to identify functional API groups, avoiding reliance on potentially incomplete or outdated existing tests. Instead, the agent proactively generates dedicated verification suites that assess both service connectivity and functional logic, which are later used to validate the model's solution. This phase also involves generating API test scripts, such as test_connect.py and test_func.py, to ensure the correctness of the service endpoints.
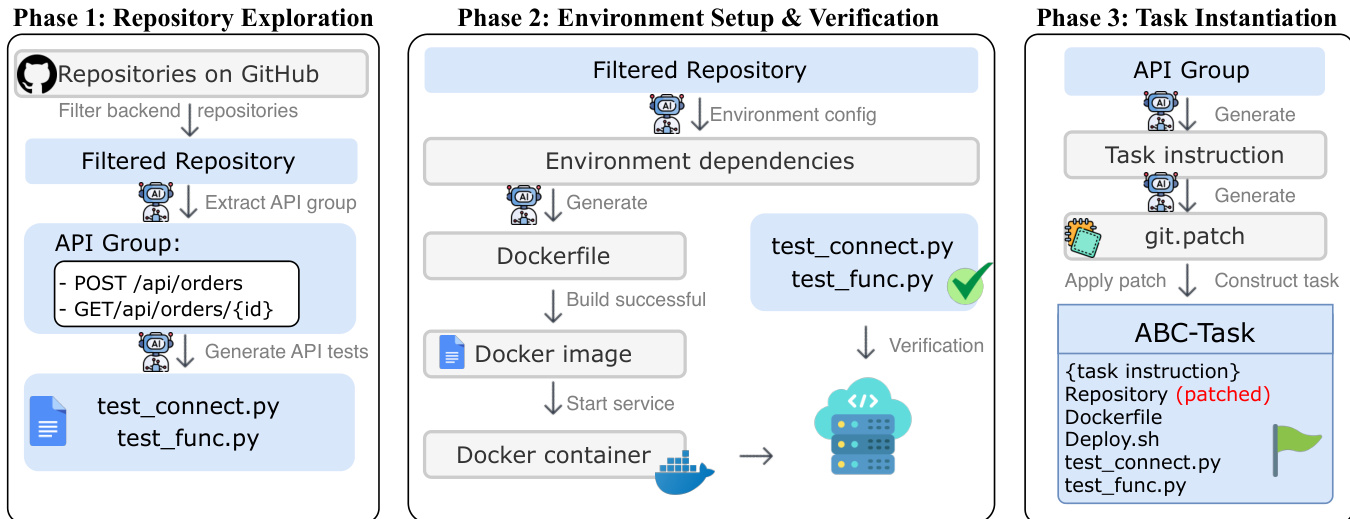
As shown in the figure below, the second phase, Environment Setup & Verification, focuses on synthesizing a deployable runtime environment. The agent analyzes the repository structure to resolve dependencies and generates the necessary container configuration files, including a Dockerfile. It then attempts to build the runtime image and launch the service within an isolated container. This phase ensures that the service can start up and listen on the expected ports, establishing a functional infrastructure for subsequent validation. The pipeline verifies the environment by executing a series of end-to-end API tests, such as health checks, to confirm that the service is operational and responsive.
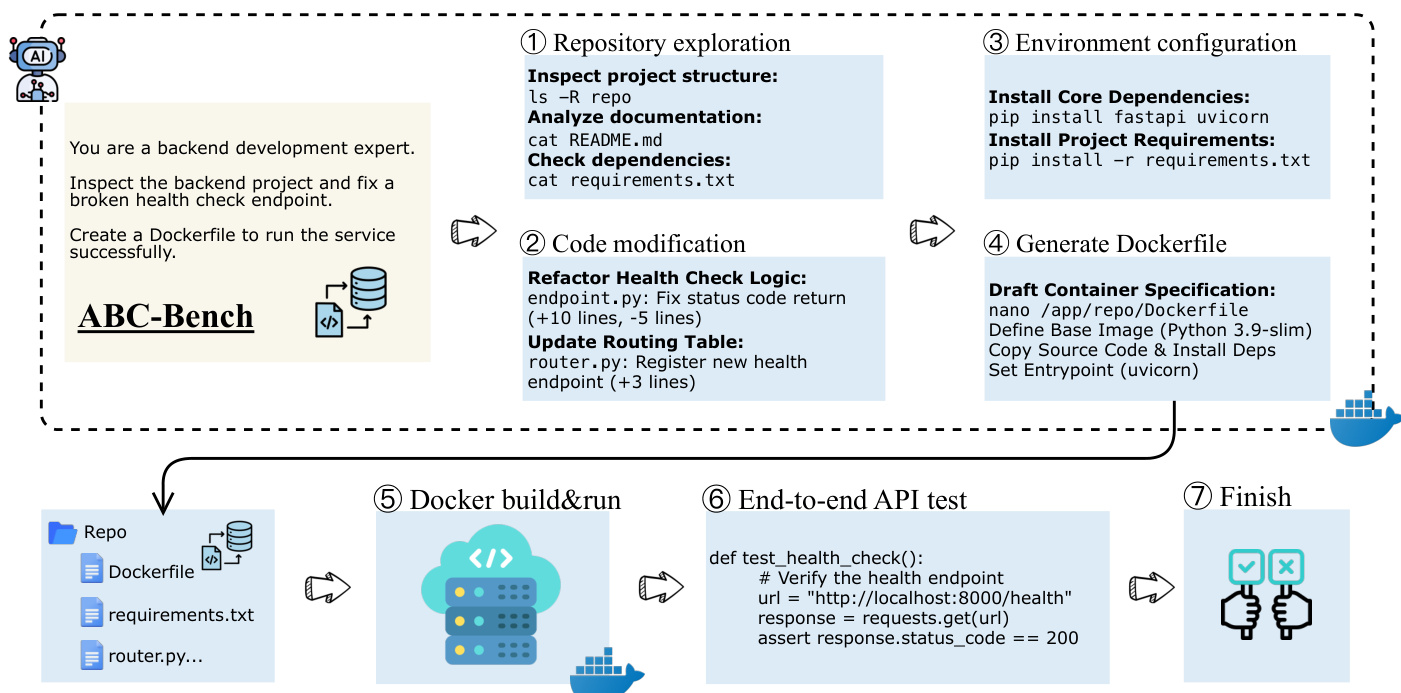
In the final phase, Task Instantiation, the pipeline constructs the benchmark task using a masking-based strategy. For a selected API group, the agent formulates a natural language task instruction and synthesizes a solution patch representing the correct implementation. The pipeline then applies a reverse operation, selectively masking the implementation logic of the target endpoint to simulate a pre-implementation state. The resulting ABC-Task package encapsulates the masked repository, the task instructions, the environment setup files, and the verification suite. For tasks designated as environment configuration challenges, the pipeline removes all synthesized environment setup files from the final package and supplements the task instructions with explicit requirements for the model to autonomously configure the runtime environment. This ensures that the benchmark evaluates both code implementation and environment setup capabilities.
Experiment
- ABC-Bench evaluates 224 full-lifecycle backend tasks, validating autonomous repository exploration, environment configuration, deployment, and API-based verification; ABC-Pipeline enables scalable task extraction from GitHub, lowering barriers to realistic dataset construction.
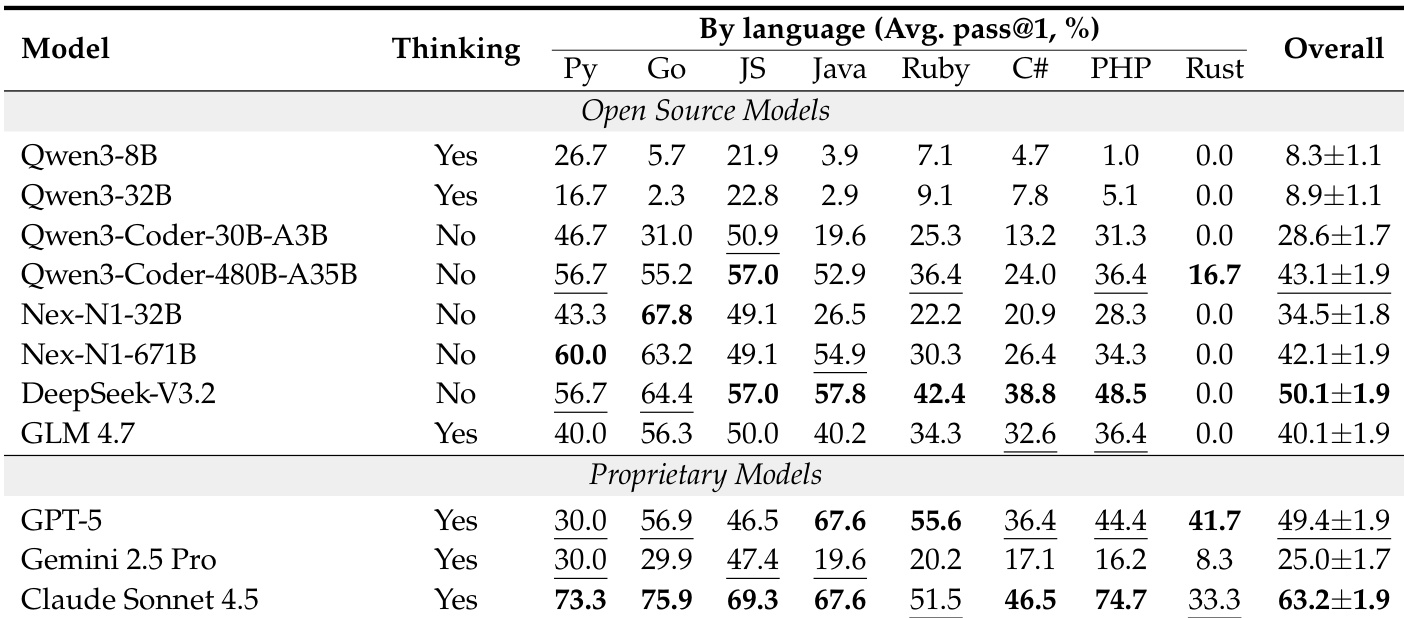
- On ABC-Bench, Claude Sonnet 4.5 achieves 63.2% pass@1 across 224 tasks, while smaller models like Qwen3-8B score below 10%, highlighting the challenge of end-to-end software engineering.
- Environment configuration is the primary bottleneck: models like GPT-5 and DeepSeek-V3.2 achieve S₁ (build success) below 50% despite strong S₂ (functional execution) scores above 80%, indicating a critical gap in setup and dependency management.
- Performance varies significantly by language stack: Rust tasks are particularly challenging, with most models failing (e.g., DeepSeek-V3.2 at 0.0%), while only top proprietary models (Claude Sonnet 4.5, GPT-5) exceed 30% success.
- A strong positive correlation (r = 0.87) exists between interaction depth and success, with top models averaging over 60 turns versus under 10 for weaker models, underscoring the need for sustained, iterative reasoning.
- Agent framework choice significantly impacts performance: OpenHands enables peak performance (~50%) for DeepSeek-V3.2 and GPT-5, while mini-SWE-agent reduces GPT-5’s success to below 20%.
- Agentic post-training via supervised fine-tuning on Nex-N1 data boosts pass@1 from 8.3% to 13.9% (Qwen3-8B) and from 8.9% to 33.8% (Qwen3-32B), demonstrating the value of high-quality agentic training data.
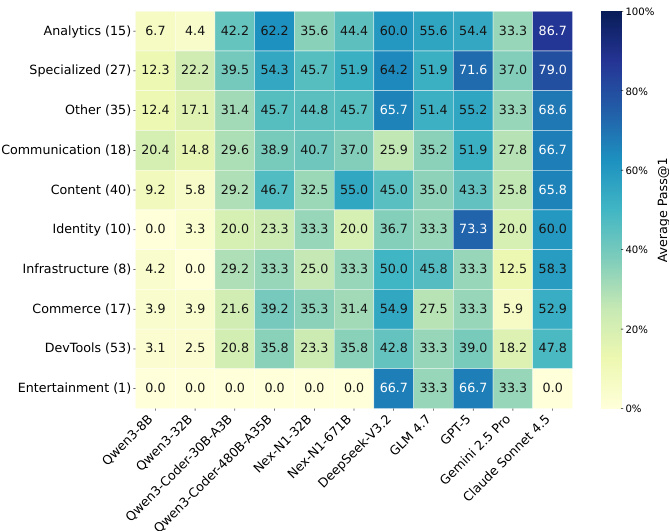
- Task category analysis reveals domain-specific challenges: DevTools tasks are consistently difficult (top model at 47.8%), while Analytics and Specialized tasks are easier (Claude Sonnet 4.5 at 86.7%).
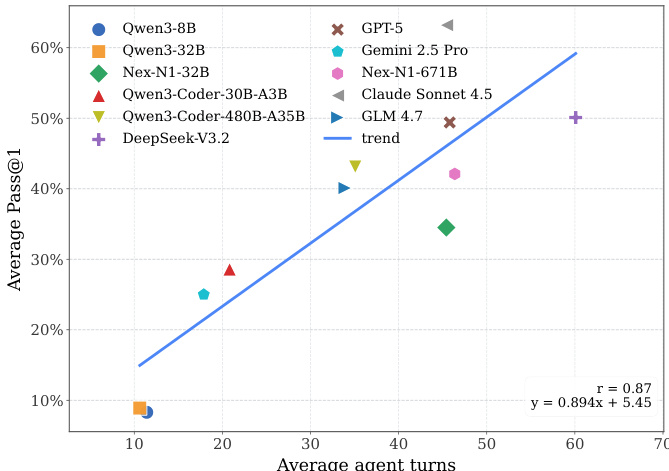
- Error analysis shows environment-related failures (e.g., Path Missing, Dependency Missing) dominate, especially for smaller models; larger models exhibit more Logic Errors, indicating a shift in failure mode from syntax to high-level reasoning.
The authors use a standardized evaluation framework to assess models on ABC-Bench, measuring performance across programming languages and identifying environment configuration as a primary bottleneck. Results show that while proprietary models like Claude Sonnet 4.5 achieve high overall pass rates, open-source models struggle significantly, particularly in Rust and with smaller parameter scales, highlighting persistent challenges in full-lifecycle software development.
The authors analyze error types across models, revealing that smaller models like Qwen3-8B primarily fail due to basic issues such as syntax and path errors, while larger models like GPT-5 and Qwen3-Coder exhibit more complex logic errors, indicating a shift in failure modes as model scale increases.
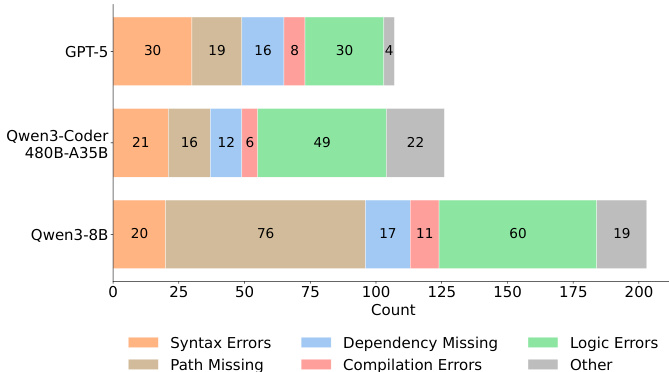
Results show a strong positive correlation between the average number of agent interaction turns and the average pass@1 performance across models, with a correlation coefficient of 0.87. The authors use this relationship to highlight that successful full-lifecycle software development requires sustained, iterative interaction, as top-performing models like Claude Sonnet 4.5 exhibit significantly longer execution trajectories compared to weaker models.
The authors introduce ABC-Bench, a benchmark that evaluates models on full-lifecycle backend tasks, including exploration, code generation, environment configuration, deployment, and end-to-end verification. Unlike existing benchmarks, ABC-Bench covers all these stages comprehensively, as demonstrated by the inclusion of all four phases—Exploration, Code, Environment, and Deployment—in its evaluation framework.

The authors evaluate models on ABC-Bench, a benchmark of full-lifecycle backend tasks, using a standardized sandbox environment that requires agents to autonomously configure environments, deploy services, and pass functional API tests. Results show that environment configuration is the primary bottleneck, with models like GPT-5 and DeepSeek-V3.2 achieving high functional success rates but failing at the initial build stage, while smaller models like Qwen3-8B struggle significantly at both stages.