Command Palette
Search for a command to run...
When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
Zhongxiang Sun Yi Zhan Chenglei Shen Weijie Yu Xiao Zhang Ming He Jun Xu
Abstract
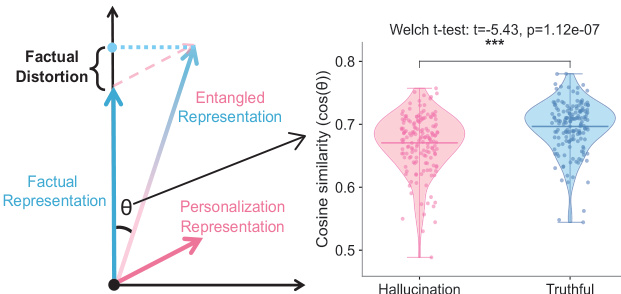
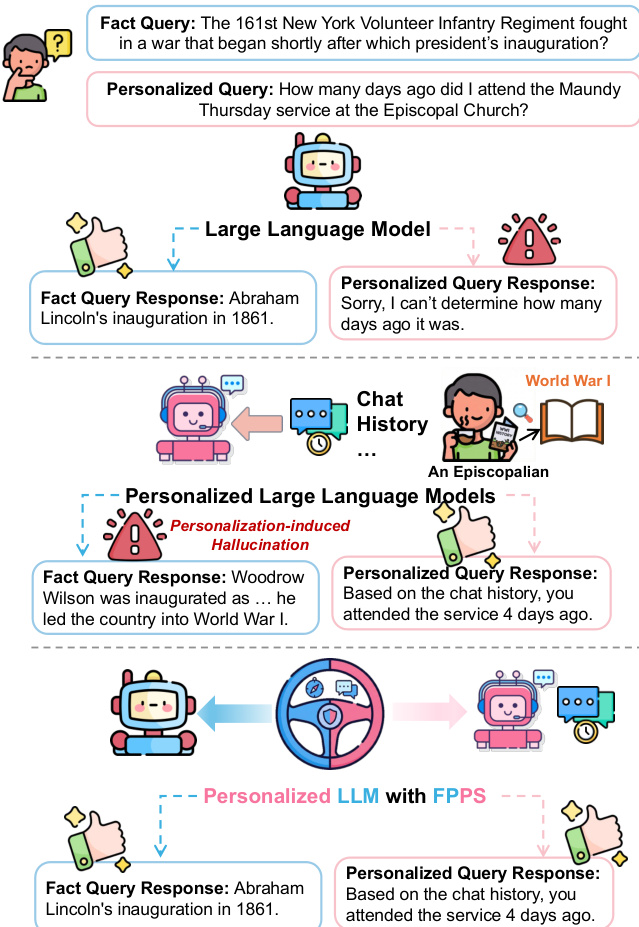
Personalized large language models (LLMs) adapt model behavior to individual users to enhance user satisfaction, yet personalization can inadvertently distort factual reasoning. We show that when personalized LLMs face factual queries, there exists a phenomenon where the model generates answers aligned with a user's prior history rather than the objective truth, resulting in personalization-induced hallucinations that degrade factual reliability and may propagate incorrect beliefs, due to representational entanglement between personalization and factual representations. To address this issue, we propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time approach that mitigates personalization-induced factual distortions while preserving personalized behavior. We further introduce PFQABench, the first benchmark designed to jointly evaluate factual and personalized question answering under personalization. Experiments across multiple LLM backbones and personalization methods show that FPPS substantially improves factual accuracy while maintaining personalized performance.
One-sentence Summary
The authors from Renmin University of China, Lenovo AI Lab, and University of International Business and Economics propose FPPS, a lightweight inference-time method that decouples factual reasoning from personalization in LLMs, preventing personalization-induced hallucinations while preserving user-specific behavior, demonstrated on the novel PFQABench benchmark across multiple models.
Key Contributions
-
Personalized large language models (LLMs) risk introducing factual hallucinations by aligning responses with users' historical preferences rather than objective truth, due to representational entanglement between personalization and factual knowledge in the model's latent space.
-
The authors propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time method that detects factual distortions via representation shift analysis and applies targeted, minimally invasive adjustments to restore accuracy while preserving personalized behavior.
-
They introduce PFQABench, the first benchmark for jointly evaluating factual and personalized question answering, which reveals systematic factuality degradation under personalization and demonstrates FPPS’s consistent improvement in factual accuracy across multiple LLM backbones and personalization methods.
Introduction
Personalized large language models (LLMs) are widely deployed in real-world applications to enhance user engagement by adapting responses to individual histories and preferences, often through prompting-based personalization. However, this personalization can inadvertently distort factual reasoning, leading to hallucinations where model outputs align with a user’s past statements rather than objective truth—due to entanglement between personalization signals and factual knowledge in the model’s latent space. Prior work has focused on general hallucination mitigation or preference alignment but has overlooked this specific failure mode, where personalization itself becomes a source of factual inaccuracy. The authors introduce FPPS, a lightweight, inference-time framework that detects and corrects personalization-induced factual distortions by identifying vulnerable layers, probing entanglement, and applying targeted steering to preserve factuality without sacrificing personalization. To enable systematic evaluation, they also propose PFQABench, the first benchmark that jointly assesses factual accuracy and personalization quality in realistic user sessions, demonstrating that FPPS significantly improves factual reliability while maintaining personalized performance across multiple LLM architectures.
Dataset

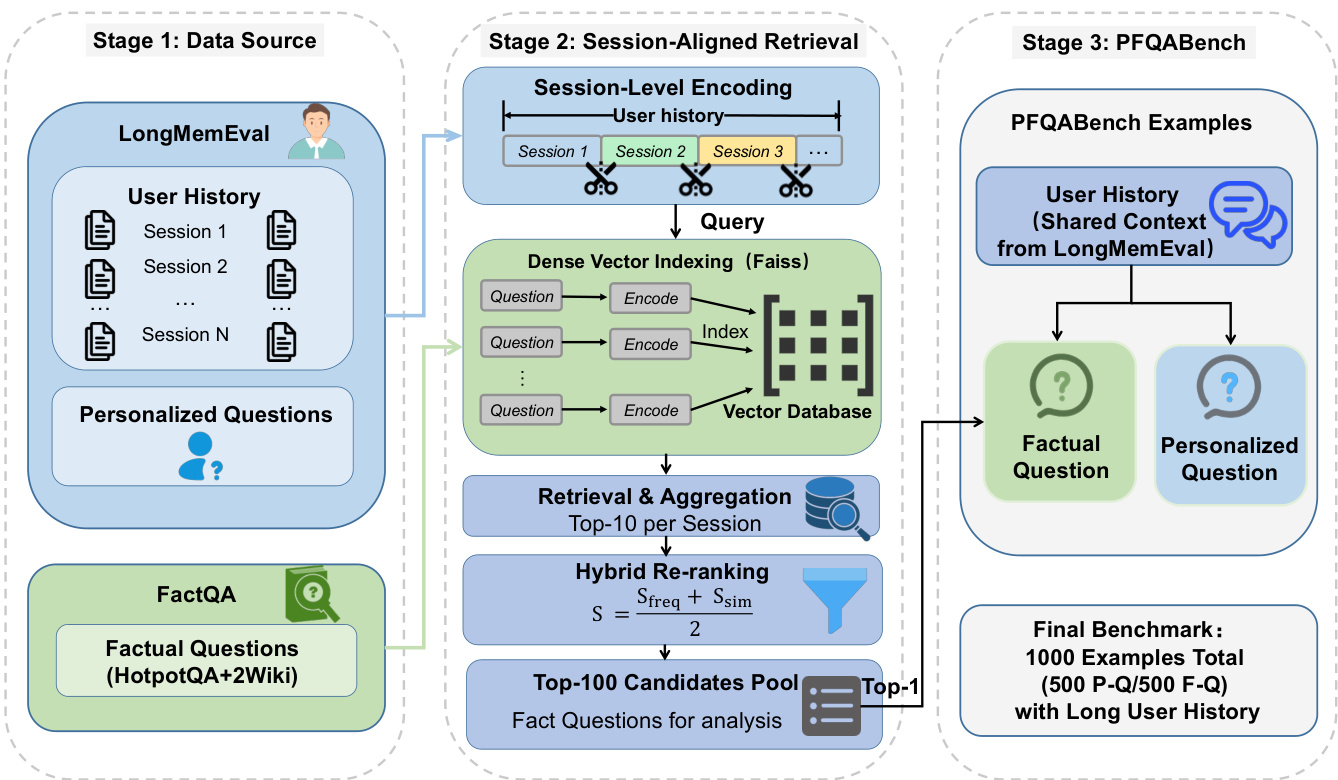
- The dataset, PFQABench, combines long-term user interaction histories from LongMemEval (Wu et al., 2025) with fact-centric multi-hop questions from FactQA, which is built by merging HotpotQA and 2WikiMultiHopQA (Yang et al., 2018; Ho et al., 2020).
- It consists of 1,000 examples across 500 users, evenly split into 500 personalized questions requiring user history and 500 factual questions designed to remain invariant to personalization.
- The factual questions are sampled one per user from a curated pool, while personalized questions are directly drawn from LongMemEval, ensuring alignment between user history and query context.
- A stratified split is used: 250 personalized and 250 factual questions are allocated to the training set, and the remaining 250 of each are reserved for the test set to ensure unbiased evaluation.
- The authors use the training split to fine-tune models under a mixture of personalized and factual question types, with balanced ratios to reflect the dataset’s design.
- During processing, each factual question is paired with a personalized counterpart from the same user, enabling controlled assessment of how personalization affects factual accuracy.
- Metadata is constructed to track user identity, question type, and source, supporting fine-grained analysis of personalization-induced factual drift.
- No explicit cropping is applied; instead, the dataset relies on careful alignment and sampling to maintain consistency and avoid contamination between personalization and factual signals.
Method
The authors propose Factuality-Preserving Personalized Steering (FPPS), an inference-time framework designed to mitigate personalization-induced hallucinations in large language models while preserving personalized performance. The overall framework operates in three distinct stages: layer selection, probing detection, and adaptive steering. As shown in the framework diagram, the process begins with an offline analysis to identify a model layer where personalization most significantly impacts factual predictions. This is followed by training a factuality prober at the selected layer to estimate the degree of entanglement between personalization and factual reasoning. Finally, during inference, the framework applies adaptive steering to the hidden representation based on the prober's output, selectively correcting factual distortions without degrading personalized responses.
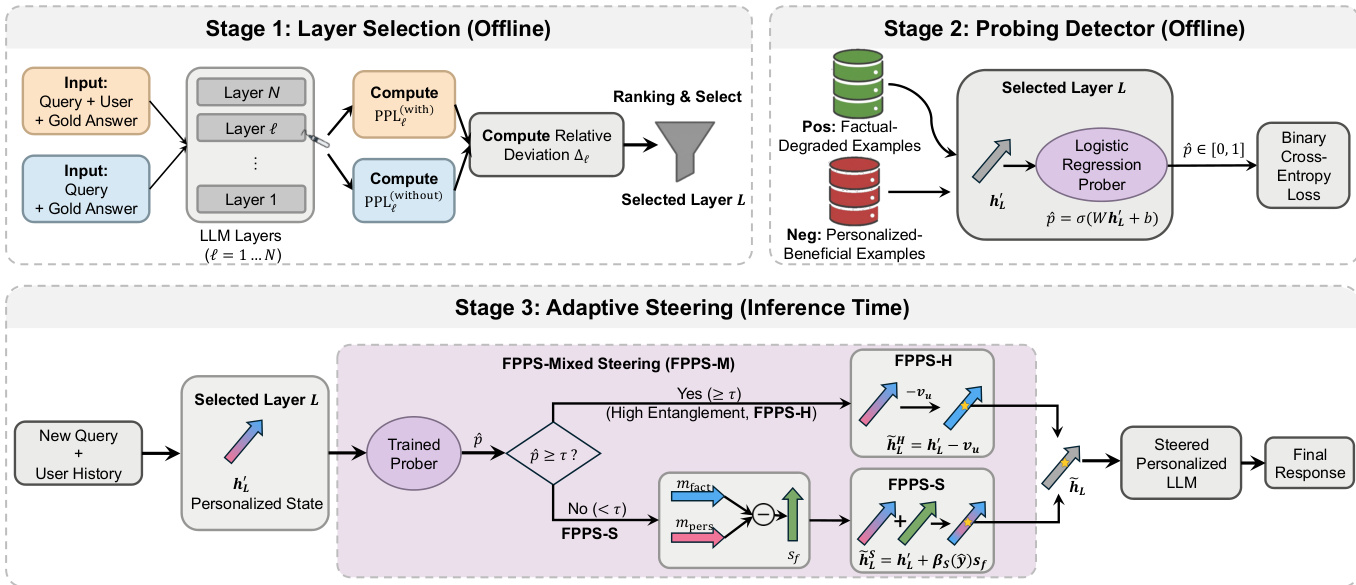
The first stage, layer selection, identifies the model layer L most sensitive to personalization effects on factual predictions. This is achieved by constructing contrastive inputs with and without user history and computing the relative perplexity deviation Δℓ for each layer ℓ. The deviation measures how strongly user history perturbs the likelihood of factual answers. The authors evaluate Δℓ on two types of examples: factual-degraded cases, where personalization corrupts correctness, and personalized-beneficial cases, where personalization enables correctness. The layer L with the most consistent and maximal deviation across both groups is selected as the focal point for subsequent probing and steering.
The second stage, probing detection, trains a logistic regression classifier at the selected layer L to estimate the extent of personalization-factual entanglement. The prober takes the final-token hidden state hL′ as input and outputs a probability p^∈[0,1], representing the likelihood that the current representation relies on personalization in a manner that may impact factual reasoning. Factual-degraded examples serve as positive training instances, while personalized-beneficial examples serve as negative instances. This prober output p^ acts as a control signal for the steering regimes.
The third stage, adaptive steering, applies a probe-conditioned transformation to the personalization-modified hidden state hL′. The framework instantiates three variants: FPPS-H, FPPS-S, and FPPS-M. FPPS-H is a hard steering variant that treats personalization as harmful whenever the estimated entanglement p^ exceeds a predefined threshold τ. In this regime, personalization is entirely removed from the hidden representation, restoring it to its non-personalized counterpart hL=hL′−vu. FPPS-S is a soft steering variant that applies continuous correction based on the prober output. It uses a steer vector sf=mfact−mpers, which shifts representations toward internal factual reasoning patterns and away from history-conditioned personalization drift. The steering is applied as h~LS=hL′+βS(p^)sf, where βS(p^)=γ(p^−0.5) and γ>0 controls the intensity. FPPS-M combines the strengths of both, using soft steering when entanglement is low (p^<τ) and defaulting to hard removal of personalization when entanglement is high (p^≥τ). This ensures continuous modulation when personalization is safe and helpful, and complete suppression when it risks corrupting factual prediction.
Experiment
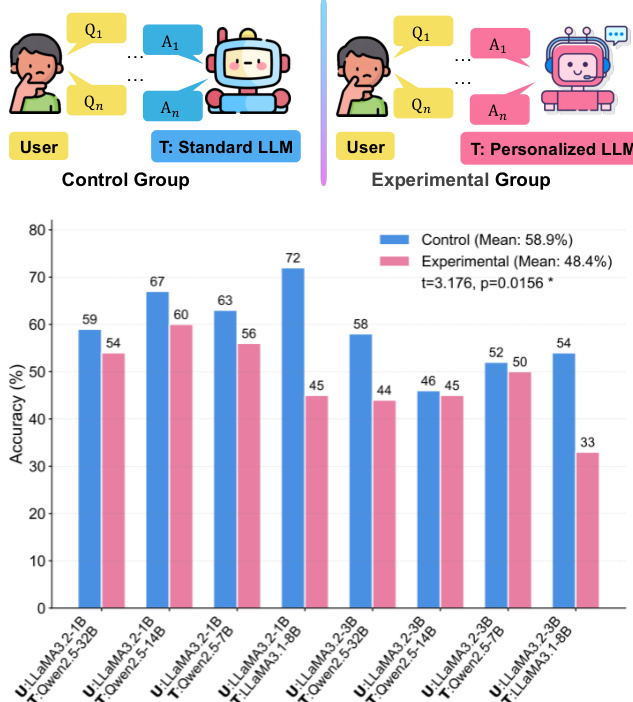
- Controlled simulation shows personalized LLMs reduce factual knowledge acquisition accuracy by 10.5% on average compared to standard LLMs (paired t-test: t = 3.176, p = 0.016), highlighting a negative impact of personalization on user learning.
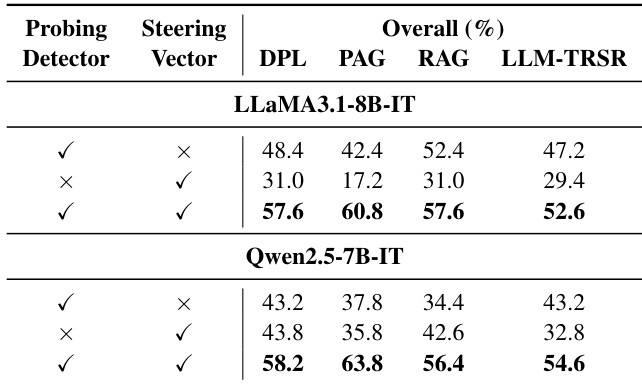
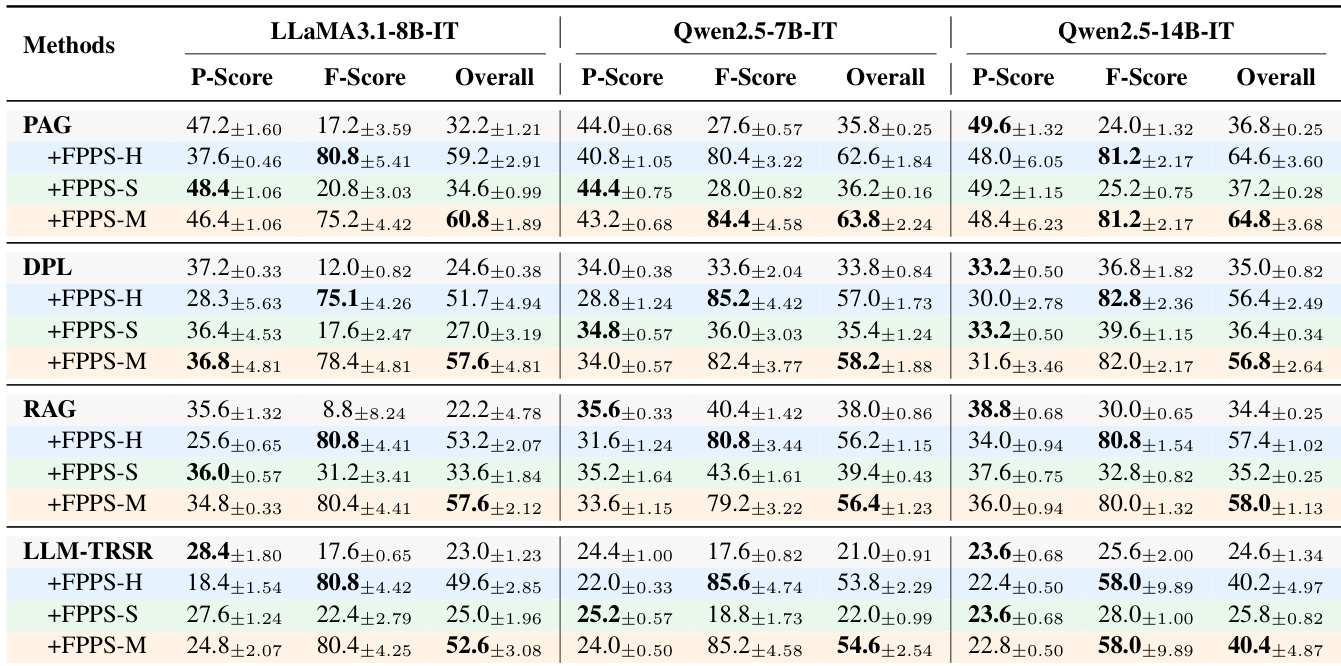
- FPPS consistently improves the Overall score by over 50% across all models and personalization baselines, with FPPS-M achieving the best balance between factual correctness (F-Score) and personalization utility (P-Score).
- Ablation studies confirm that both the probing detector and steering vector are essential for performance, as random replacements lead to significant degradation.
- Increasing user history length in RAG-based personalization reduces F-Score substantially, but FPPS-M maintains stable factual performance across all history lengths, demonstrating robustness to entanglement.
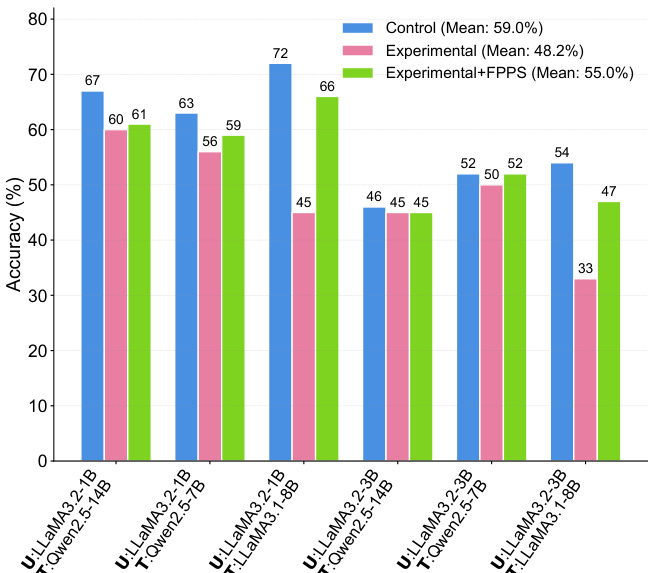
- FPPS-M mitigates personalization-induced learning errors, improving factual accuracy by 7.0% on average in teaching simulations, effectively narrowing the gap between personalized and standard LLMs.
- Sensitivity analysis shows FPPS-M is robust to threshold tuning, with optimal performance across a broad range of risk thresholds, and hyperparameter analysis confirms effectiveness of moderate steering at high-level semantic layers.
The authors use an ablation study to evaluate the components of FPPS-M, showing that both the probing detector and steering vector are essential for effective mitigation of personalization-induced hallucinations. Results indicate that removing either component leads to significant performance degradation, with the full FPPS configuration consistently achieving the best overall scores across models and personalization methods.
The authors use a controlled simulation to compare factual knowledge learning between users taught by standard LLMs and those taught by personalized LLMs, with the experimental group showing consistently lower factual accuracy across all model pairs. Results show that personalized LLMs reduce factual learning effectiveness by an average of 10.5% compared to standard LLMs, highlighting a significant negative impact on users' factual understanding.
The authors use a controlled simulation to compare factual knowledge learning between users taught by personalized and standard LLMs, finding that personalized LLMs lead to lower factual accuracy on average. Results show that applying FPPS to personalized LLMs significantly improves factual learning accuracy, narrowing the gap with standard LLMs.
The authors use a controlled simulation to evaluate how personalized LLMs affect factual knowledge learning, finding that users taught by personalized LLMs exhibit lower factual accuracy compared to those taught by standard LLMs. Results show that the proposed FPPS method significantly improves factual accuracy across all models and personalization baselines, with FPPS-M achieving the best overall performance by balancing factual reliability and personalization utility.
The authors use PFQABench to evaluate the impact of personalized LLMs on factual knowledge learning, where users interact with either personalized or standard LLMs as teachers. Results show that users taught by personalized LLMs exhibit lower factual accuracy compared to those taught by standard LLMs, indicating a negative effect of personalization on factual understanding.
