Command Palette
Search for a command to run...
Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text
Zhihao Xu Rumei Li Jiahuan Li Rongxiang Weng Jingang Wang Xunliang Cai Xiting Wang
Abstract
Enabling Large Language Models (LLMs) to effectively utilize tools in multi-turn interactions is essential for building capable autonomous agents. However, acquiring diverse and realistic multi-turn tool-use data remains a significant challenge. In this work, we propose a novel text-based paradigm. We observe that textual corpora naturally contain rich, multi-step problem-solving experiences, which can serve as an untapped, scalable, and authentic data source for multi-turn tool-use tasks. Based on this insight, we introduce GEM, a data synthesis pipeline that enables the generation and extraction of multi-turn tool-use trajectories from text corpora through a four-stage process: relevance filtering, workflow & tool extraction, trajectory grounding, and complexity refinement. To reduce the computational cost, we further train a specialized Trajectory Synthesizer via supervised fine-tuning. This model distills the complex generation pipeline into an efficient, end-to-end trajectory generator. Experiments demonstrate that our GEM-32B achieve a 16.5% improvement on the BFCL V3 Multi-turn benchmark. Our models partially surpass the performance of models trained on τ - bench (Airline and Retail) in-domain data, highlighting the superior generalization capability derived from our text-based synthesis paradigm. Notably, our Trajectory Synthesizer matches the quality of the full pipeline while significantly reducing inference latency and costs.
One-sentence Summary
The authors from Renmin University of China and Meituan propose GEM, a text-based data synthesis framework that generates realistic multi-turn tool-use trajectories from corpora via a four-stage pipeline, enabling efficient training of a distilled Trajectory Synthesizer that matches full-pipeline performance with lower latency, achieving state-of-the-art results on BFCL V3 and outperforming in-domain models on airline and retail tasks.
Key Contributions
-
Existing methods for training multi-turn tool-use agents rely on predefined APIs and simulation, which limits data diversity and realism due to the high cost and difficulty of acquiring comprehensive tool sets; this work introduces a text-based paradigm that leverages unstructured textual corpora—rich in real-world, multi-step problem-solving narratives—as a scalable and authentic source for generating tool-use trajectories.
-
The proposed GEM pipeline systematically extracts and transforms textual workflows into structured, multi-turn tool-use trajectories through four stages: relevance filtering, workflow and tool extraction, trajectory grounding, and complexity refinement, enabling the synthesis of high-quality, domain-diverse data without requiring predefined tools.
-
Experiments show that models trained on GEM-synthesized data achieve a 14.9% improvement on the BFCL V3 Multi-turn benchmark and match the performance of models trained on in-domain τ-bench data, while a distilled Trajectory Synthesizer delivers equivalent quality with significantly reduced inference cost and latency.
Introduction
The authors address the challenge of training autonomous agents for real-world tool use, where prior methods rely on predefined APIs to simulate interactions, limiting diversity and scalability. This approach suffers from data scarcity and narrow domain coverage, hindering generalization. To overcome this, they propose a novel "text-to-trajectory" paradigm that extracts multi-turn tool-use workflows directly from unstructured, real-world text corpora—such as procedural documents—leveraging the inherent richness of human problem-solving narratives. Their GEM pipeline systematically selects, extracts, generates, and refines high-quality trajectories by transforming textual workflows into structured agent interactions with realistic constraints, ambiguity, and complex dependencies. Experiments show that models trained on GEM-synthesized data achieve significant gains on benchmark tasks, including a 14.9% improvement on BFCL V3 Multi-Turn, and demonstrate strong out-of-domain generalization, rivaling models trained on in-domain data. The approach enables scalable, cost-effective, and authentic data generation, paving the way for more robust and generalizable agentic systems.
Dataset

- The dataset is synthesized through a four-stage pipeline that transforms raw text into high-quality, multi-turn tool-use trajectories, leveraging real-world text segments as source material.
- Raw text segments are filtered in Stage 1 to retain only those describing multi-step operations, using the same annotation prompt and model from Section 3.1 to ensure realism and quality.
- In Stage 2, the pipeline extracts abstract workflows and synthesizes functional tools based on the text, with each tool adhering to OpenAI schema standards—designed for single, coherent functions with clear parameter names and data types.
- Stage 3 generates full multi-turn trajectories using a strong teacher model (GLM-4.6), producing structured outputs including system prompts, user requests, assistant responses, and realistic tool responses across multiple conversational turns.
- Trajectories are refined in Stage 4 to increase complexity, diversity, and realism—expanding tool variety, enhancing environmental feedback, introducing ambiguous or complex user queries, and ensuring non-trivial tool-call chains.
- Validation is performed in two stages: first, rule-based checks ensure structural correctness (valid tool definitions, proper formatting, and closed role tags); second, an LLM-based judge (Qwen3-32B) verifies that all tool parameters are contextually grounded and free of hallucinations.
- Only trajectories passing both validation stages are retained as Tfinal for supervised fine-tuning (SFT).
- A data synthesizer is trained via SFT to learn an end-to-end mapping from raw text to multi-turn tool-use trajectories, enabling cost-effective, scalable data generation.
- The dataset is used in training with a mixture of trajectories from diverse domains, as revealed by domain analysis in Figure 9, ensuring broad coverage and real-world relevance.
- Processing includes metadata construction such as tool definitions, role tags, and structured conversation components, with no cropping applied—full trajectories are preserved as generated.
Method
The authors leverage a novel data synthesis pipeline, GEM, designed to generate multi-turn tool-use trajectories directly from large-scale text corpora. This approach contrasts with conventional methods that rely on predefined tools and synthetic simulations, which often lack the diversity and realism of authentic human problem-solving behaviors. The overall framework, as illustrated in the figure below, consists of a four-stage process: relevance filtering, workflow and tool extraction, trajectory grounding, and complexity refinement. The pipeline begins by processing raw text corpora to identify and retain segments that describe multi-step workflows. These segments are then used to extract functional tools and their corresponding workflows, which are subsequently transformed into executable trajectories. To enhance efficiency and scalability, the authors further train a specialized Trajectory Synthesizer via supervised fine-tuning. This model distills the complex multi-stage generation process into an end-to-end generator, enabling cost-effective and high-throughput data synthesis while maintaining the quality of the trajectories.

The methodology is structured into two main phases. Phase 1, titled "Tools & Workflow Extraction," encompasses the initial stages of text filtering and the extraction of abstract workflows and functional tools. Raw text corpora are first subjected to text filtering to remove non-multi-step operations, yielding retained segments that describe multi-step processes. From these segments, the pipeline extracts workflows and designs functional tools in JSON or OpenAI schema format. This phase is critical for establishing the foundational components of the trajectories, ensuring that the tools and their interactions are grounded in realistic, real-world logic. The extracted tools are designed to be semantically clear, reusable, and to implement single, coherent capabilities, with parameters explicitly defined to mirror real-world constraints.

Phase 2, "Trajectory Generation," involves the creation and refinement of the actual trajectories. This phase begins with an initial trajectory generation step, where a system prompt and a user task are used to generate a preliminary trajectory. The trajectory is then refined to enhance its complexity and diversity, encouraging the inclusion of various interaction patterns such as clarification, error recovery, and adherence to domain rules. The refined trajectory undergoes a final validation process, which includes a rule-based check to ensure valid format and tool calls, and an LLM-based judge to assess the quality of the agent's communication skills, robust tool-calling capability, and reasoning and execution ability. This validation ensures that the final output is high-quality, diverse, and realistic, suitable for training autonomous agents. The entire process is designed to produce trajectories that exhibit multiple interaction patterns, with at least three distinct patterns appearing in total, and each individual pattern used at most twice within a single trajectory.

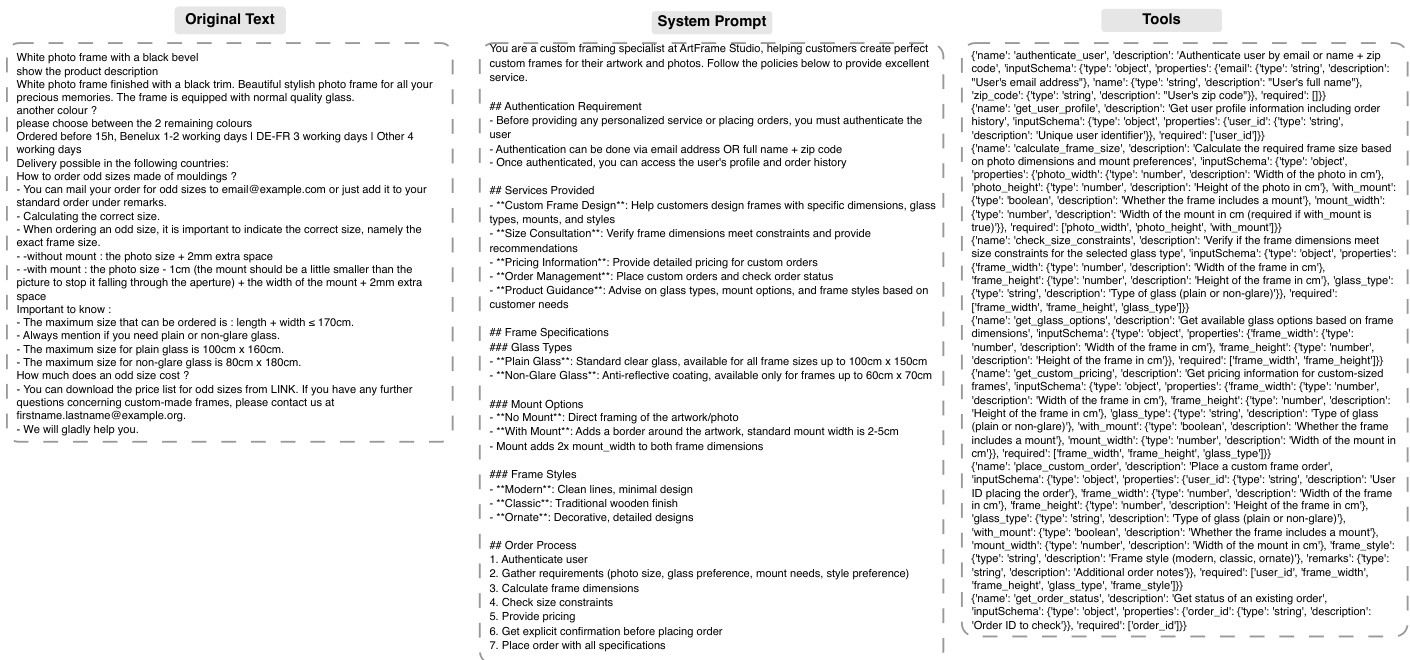
The system prompt, as shown in the figure below, provides the necessary context and constraints for the agent to generate appropriate tool calls. It includes authentication requirements, services provided, frame specifications, and the order of operations. The tools are defined with detailed input schemas, ensuring that the parameters are correctly typed and validated. The prompt also includes system rules and constraints, such as the maximum size of the frame and the availability of certain features, which the agent must adhere to. This structured approach ensures that the generated trajectories are not only diverse but also realistic and grounded in the specific domain, making them highly effective for training autonomous agents. The final output is a high-quality dataset of agent trajectories that can be used to train models to effectively utilize tools in multi-turn interactions.
Experiment
- Preliminary analysis on Ultra-fineWeb corpus demonstrates that 14% of sampled text segments contain multi-step workflows, revealing rich diversity in task categories, tools, and environments, validating the feasibility of extracting agentic trajectories directly from unstructured text.
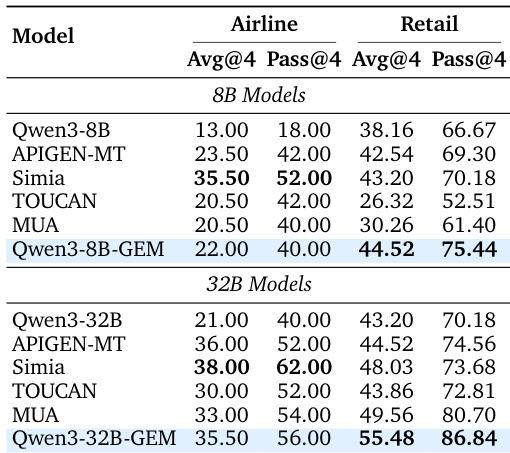
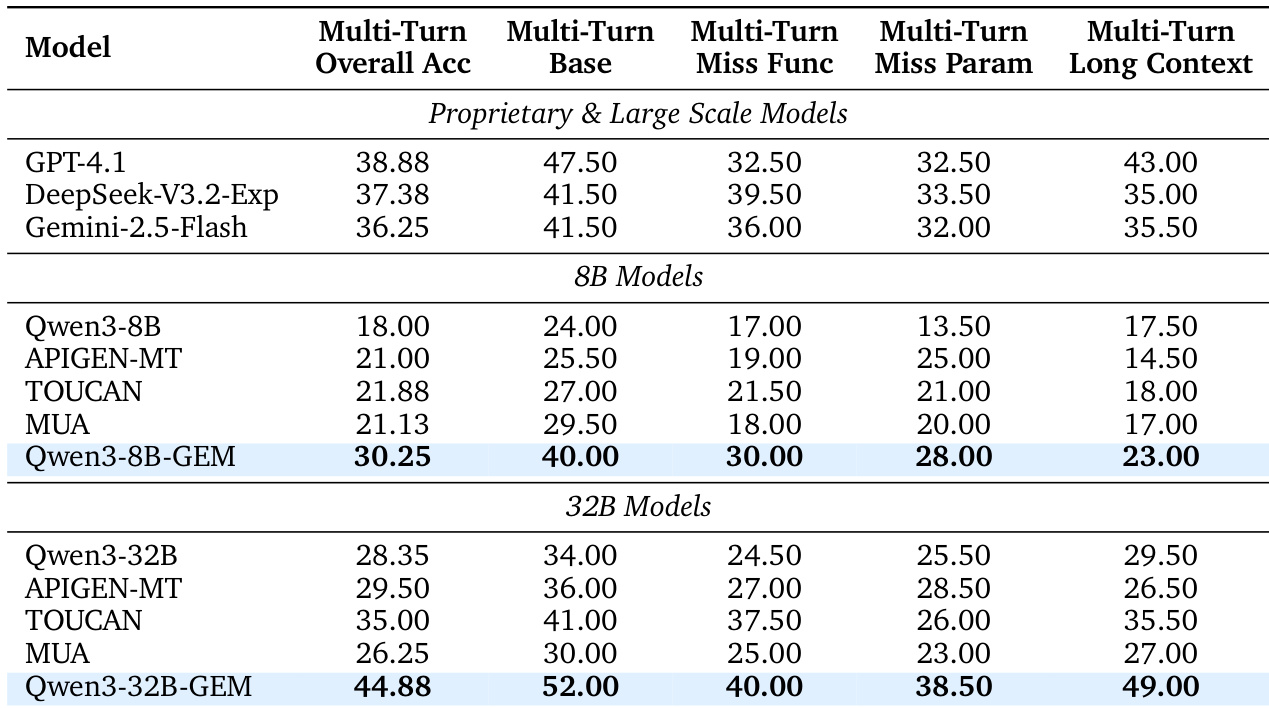
- GEM synthesis pipeline generates high-quality, out-of-domain synthetic trajectories from text, achieving 30.25% accuracy on BFCL V3 (8B) and 44.88% (32B), surpassing open-source baselines and proprietary models like GPT-4.1 (38.88%) and DeepSeek-V3.2-Exp (37.38%).
- On tau2-bench (Airline and Retail), Qwen3-8B-GEM achieves Pass@4 of 75.44% (Retail) and Qwen3-32B-GEM reaches 86.84% (Retail), outperforming in-domain baselines like SIMIA and MUA despite being trained on strictly out-of-domain data, demonstrating strong generalization.
- The GEM synthesizer, trained on 10K trajectories, achieves competitive performance (28.38% on BFCL, 73.68% Pass@4 on tau2-Retail) and generalizes to alternative sources like Wikihow, confirming its low-cost, end-to-end effectiveness.
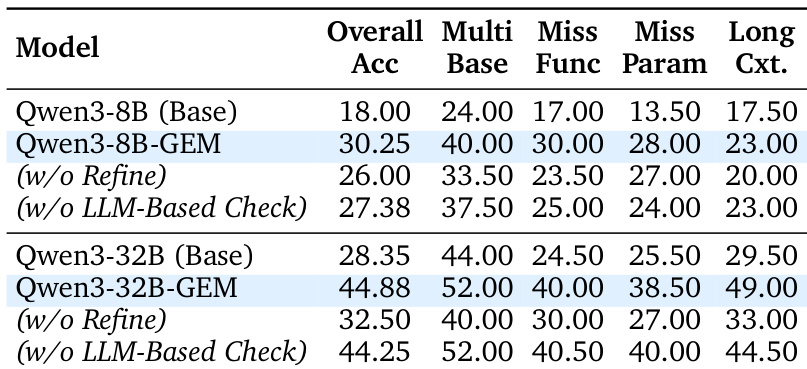
- Ablation studies show that the refinement stage increases trajectory complexity (e.g., +12.38% accuracy on 32B) and the LLM-based check reduces hallucinations, improving performance by 2.87% on 8B.
- Synthesized trajectories average 8.6 tools, 46 turns, and 16.3 tool calls per trajectory—significantly more complex than existing datasets—enabling robust training for multi-turn, tool-driven reasoning.
The authors use the BFCL V3 benchmark to evaluate multi-turn tool-use performance, showing that Qwen3-8B-GEM achieves an overall accuracy of 30.25%, outperforming other open-source models and matching or exceeding proprietary models like GPT-4.1 in specific categories. For the 32B scale, Qwen3-32B-GEM attains 44.88% overall accuracy, surpassing both open-source baselines and proprietary models such as DeepSeek-V3.2-Exp, demonstrating the effectiveness of their synthetic data pipeline.
Results show that the refinement stage significantly increases the complexity of synthesized trajectories, raising the average number of messages from 30.05 to 46.1, the number of tools from 5.01 to 8.6, and the number of tool calls from 7.83 to 16.3. This indicates that refinement enhances the depth and richness of the generated multi-turn tool-use interactions.

The authors use a refinement stage and LLM-based check to improve the quality of synthesized tool-use trajectories, resulting in significant performance gains across both model sizes. Results show that the refined Qwen3-8B-GEM and Qwen3-32B-GEM models achieve higher Avg@4 and Pass@4 scores on the Airline and Retail domains compared to their non-refined counterparts, demonstrating the effectiveness of the refinement process in enhancing trajectory complexity and accuracy.
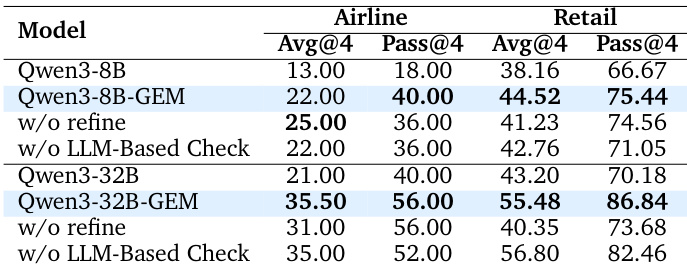
The authors use an ablation study to evaluate the impact of refinement and LLM-based checking on model performance, showing that both stages significantly improve results. Removing refinement reduces Qwen3-32B-GEM's overall accuracy from 44.88% to 32.50%, while omitting the LLM-based check lowers Qwen3-8B-GEM's accuracy from 30.25% to 27.38%, indicating that each component contributes meaningfully to the quality of synthesized trajectories.
Results show that Qwen3-8B-GEM achieves an overall accuracy of 22.00% and a Pass@4 score of 40.00% on the Airline domain, while Qwen3-32B-GEM attains 35.50% and 56.00% respectively. These results demonstrate that the GEM method significantly improves performance over baseline models, with Qwen3-32B-GEM outperforming other open-source baselines and achieving competitive results on the Retail domain.