Command Palette
Search for a command to run...
DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
Yibo Wang Lei Wang Yue Deng Keming Wu Yao Xiao Huanjin Yao Liwei Kang Hai Ye Yongcheng Jing Lidong Bing
Abstract
Deep research systems are widely used for multi-step web research, analysis, and cross-source synthesis, yet their evaluation remains challenging. Existing benchmarks often require annotation-intensive task construction, rely on static evaluation dimensions, or fail to reliably verify facts when citations are missing. To bridge these gaps, we introduce DeepResearchEval, an automated framework for deep research task construction and agentic evaluation. For task construction, we propose a persona-driven pipeline generating realistic, complex research tasks anchored in diverse user profiles, applying a two-stage filter Task Qualification and Search Necessity to retain only tasks requiring multi-source evidence integration and external retrieval. For evaluation, we propose an agentic pipeline with two components: an Adaptive Point-wise Quality Evaluation that dynamically derives task-specific evaluation dimensions, criteria, and weights conditioned on each generated task, and an Active Fact-Checking that autonomously extracts and verifies report statements via web search, even when citations are missing.
One-sentence Summary
The authors from Infinity Lab, Shanda Group, and Nanyang Technological University propose DeepResearchEval, an automated framework for constructing realistic deep research tasks via persona-driven generation and evaluating LLM-based agents with adaptive, task-specific quality assessment and active fact-checking that verifies claims without citations, enabling reliable evaluation of multi-step web research systems.
Key Contributions
-
We introduce DeepResearchEval, an automated framework that generates realistic, complex deep research tasks through a persona-driven pipeline, overcoming the annotation burden and static nature of existing benchmarks by leveraging diverse user profiles and a two-stage filtering process to ensure tasks require multi-source evidence integration and external retrieval.
-
The framework features an agentic evaluation system with Adaptive Point-wise Quality Evaluation, which dynamically tailors assessment dimensions, criteria, and weights to each task’s specific context, enabling more nuanced and relevant evaluation than fixed, task-agnostic benchmarks.
-
It includes Active Fact-Checking that autonomously extracts and verifies both cited and uncited claims via web search, significantly improving factual reliability in report evaluation, even when original sources are not provided.
Introduction
Deep research systems are increasingly used for complex, multi-step web-based investigations requiring planning, cross-source synthesis, and citation-aware reporting. However, evaluating these systems remains challenging due to reliance on labor-intensive manual task annotation, static evaluation criteria, and limited fact-checking coverage—especially for uncited claims. Prior benchmarks often fail to capture real-world complexity or adapt to domain-specific nuances, leading to inconsistent and incomplete assessments. The authors introduce DeepResearchEval, an automated framework that generates realistic research tasks through a persona-driven pipeline, ensuring tasks require multi-source evidence and external retrieval via a two-stage filtering process. For evaluation, they propose an agentic system with adaptive, task-specific quality dimensions derived dynamically from the query, and an active fact-checking module that autonomously verifies both cited and uncited claims using web search, enabling comprehensive, reference-free assessment of report quality and factual accuracy.
Dataset

- The dataset comprises deep research system outputs collected from 10 distinct sources, including Gemini-2.5-Pro, Doubao, OpenAI Deep Research, and eight other systems, all accessed via automated tools from their official websites.
- All reports were gathered during 2025, with each system contributing responses across a range of evaluation tasks.
- Average output length varies significantly: most systems generate responses exceeding 10,000 characters, while Gemini-2.5-Pro, Doubao, and OpenAI Deep Research produce notably longer outputs—reaching several tens of thousands of characters on average.
- The data is used in training with a mixture ratio that balances contributions from each system, ensuring diverse and representative coverage of reasoning styles and output structures.
- No explicit cropping strategy is applied; instead, raw outputs are retained with minimal filtering, preserving full context and depth.
- Metadata is constructed based on source system, task type, and output length, enabling downstream analysis and model evaluation.
- The dataset supports training of DeepSeek V3, which was developed using approximately $5.6 million in compute costs and 2,788 million H800 GPU hours.
Method
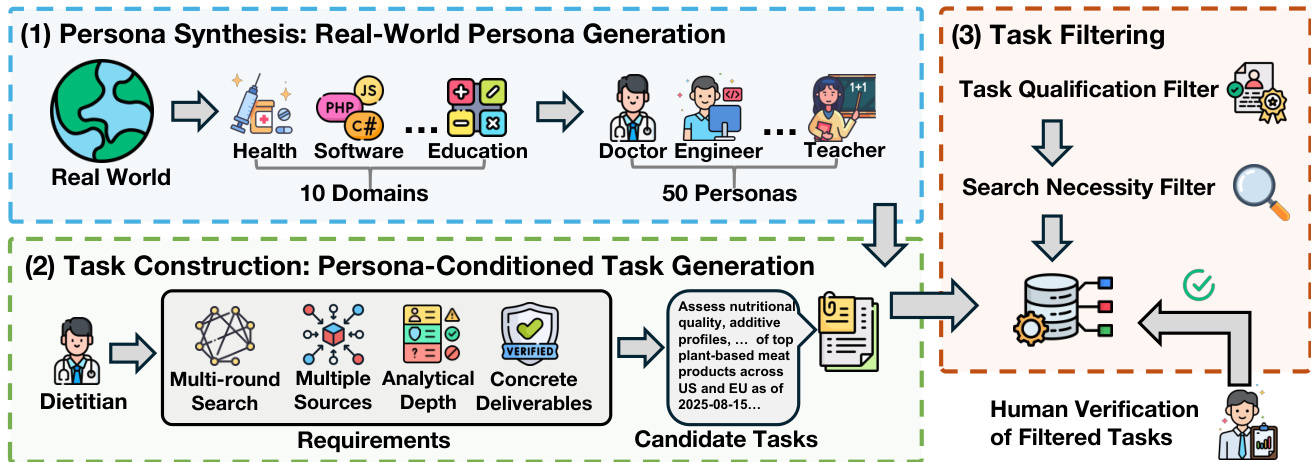
The authors present a comprehensive pipeline for constructing and evaluating deep research tasks and reports, structured around two primary phases: task construction and agentic evaluation. The overall framework, illustrated in the first figure, begins with persona synthesis, where ten real-world domains are selected to generate 50 distinct personas, each characterized by specific attributes such as role, affiliation, and background. These personas serve as the foundation for generating candidate deep research tasks, which are designed to require multi-round web searches, integration of evidence from diverse sources, analytical depth, and concrete deliverables with explicit constraints. The resulting candidate tasks undergo a two-stage filtering process: a Task Qualification Filter that ensures tasks meet criteria for depth and relevance, and a Search Necessity Filter that excludes tasks solvable using only internal knowledge, thereby ensuring the benchmark focuses on tasks requiring external information retrieval. The filtered tasks are then subject to human verification by domain experts to validate their quality.
The second figure details the agentic evaluation pipeline, which assesses the quality of generated deep research reports through two complementary components: adaptive point-wise quality evaluation and active fact-checking. The adaptive point-wise quality evaluation framework dynamically generates task-specific evaluation dimensions in addition to a fixed set of general dimensions—Coverage, Insight, Instruction-following, and Clarity—tailored to the specific requirements of each research task. For each dimension, a set of criteria is generated with corresponding weights, enabling fine-grained scoring. The final quality score is computed as a weighted sum of criterion scores across all dimensions, with weights determined by the evaluator to reflect the relative importance of each dimension for the given task. This approach allows for a more nuanced and context-aware assessment compared to fixed rubrics.
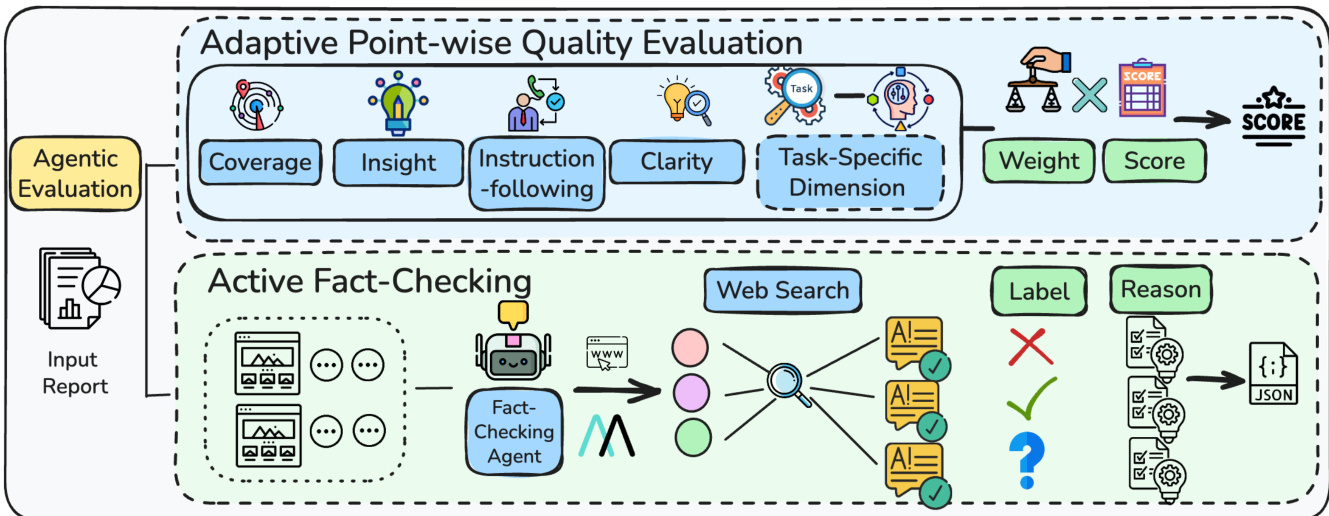
The active fact-checking component addresses the critical need for factual consistency in long-form reports. It operates by first segmenting the report into smaller parts and extracting verifiable statements from each segment. A fact-checking agent then iteratively invokes retrieval tools to gather external evidence, verifying each statement against the retrieved information. The agent assigns one of three labels—Right, Wrong, or Unknown—based on the consistency between the statement and the evidence, with the Unknown label explicitly indicating insufficient evidence rather than an error. This process ensures comprehensive statement-level verification, even for uncited claims, and produces structured JSON outputs containing labels, evidence, and reasoning. The combination of adaptive quality evaluation and active fact-checking provides a robust, multi-faceted assessment of report quality, capturing both holistic dimensions of quality and fine-grained factual accuracy.
Experiment
- Evaluated 9 deep research systems (e.g., Gemini-2.5-Pro, Manus, OpenAI, Claude-Sonnet-4.5) on 100 persona-driven, high-quality tasks using the DeepResearchEval framework, which enables automated task construction and agentic evaluation.
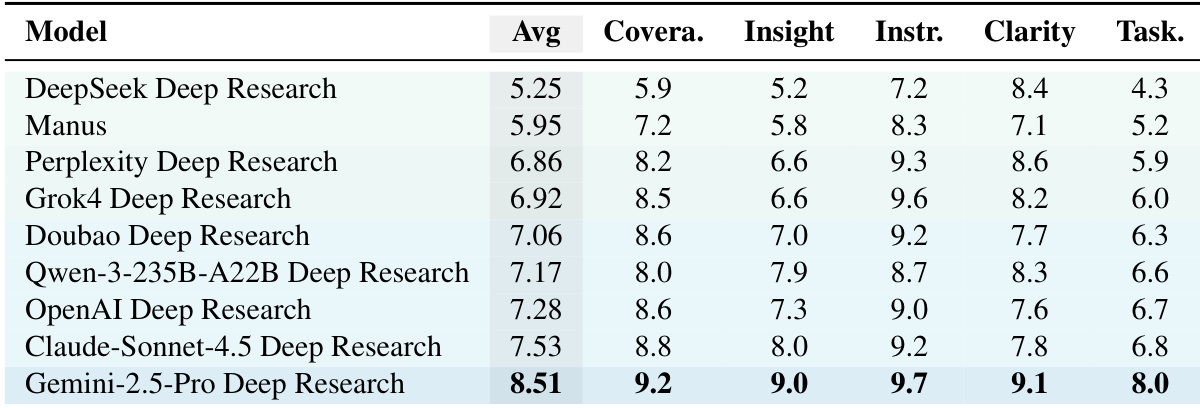
- Gemini-2.5-Pro achieved the highest overall quality score (8.51/10), excelling in coverage, insight, and instruction-following, while Manus and Gemini-2.5-Pro led in factual correctness with 82.3% and 76.3% correct statements, respectively.
- Task-specific scores were consistently lower than general scores across all systems, indicating a gap in meeting task-specific criteria and highlighting the need for adaptive evaluation.
- Active fact-checking revealed that Wrong claims were rare but Unknown claims were prevalent, suggesting factual risks stem more from weakly grounded than outright false statements.
- Cross-judge consistency, stochastic stability, and human-model alignment analyses confirmed the reliability of the evaluation framework, with 73% agreement between automated and human annotations and high robustness in rankings.
The authors use an adaptive point-wise quality evaluation framework to assess nine deep research systems across multiple dimensions, with Gemini-2.5-Pro Deep Research achieving the highest overall score of 8.51, driven by strong performance in coverage, insight, and instruction-following. Results show that while systems perform well on general quality dimensions, their task-specific scores are consistently lower, indicating a gap in meeting tailored task requirements.
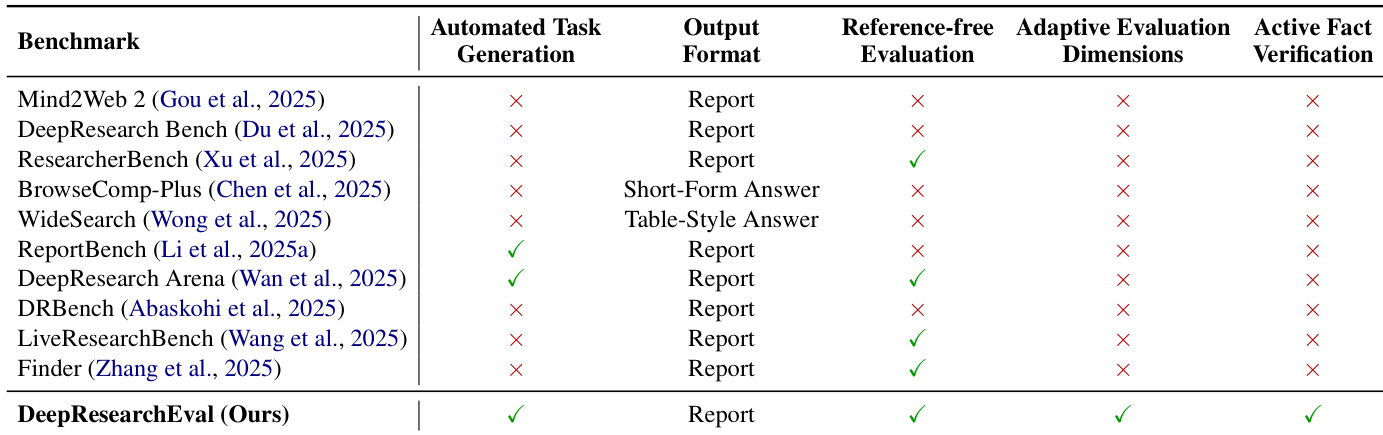
The authors use DeepResearchEval to evaluate deep research systems, highlighting its advantages over existing benchmarks by enabling automated task generation, adaptive evaluation dimensions, and active fact-checking. Results show that DeepResearchEval supports a more comprehensive and dynamic evaluation framework compared to prior work, which lacks one or more of these capabilities.
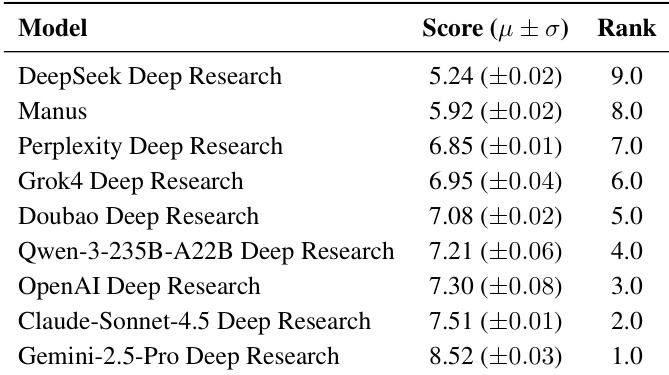
The authors use an adaptive point-wise quality evaluation framework to assess deep research systems, with results showing Gemini-2.5-Pro Deep Research achieving the highest average score of 5.29, outperforming other systems. The evaluation reveals consistent ranking stability across independent runs, indicating robustness in the scoring methodology.
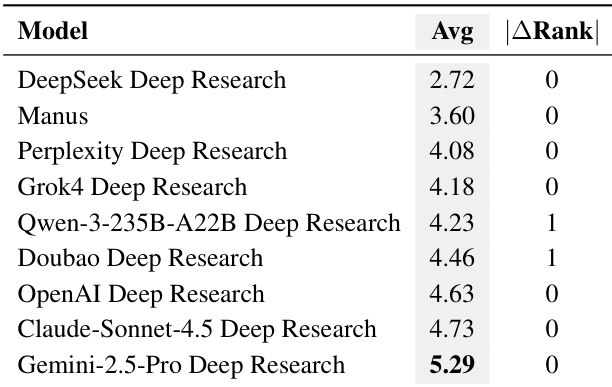
Results show that Gemini-2.5-Pro Deep Research achieves the highest quality evaluation score of 8.52, outperforming all other systems and ranking first. Manus and Perplexity Deep Research follow with scores of 5.92 and 6.85, respectively, while DeepSeek Deep Research ranks last with a score of 5.24.
The authors use a quality evaluation framework to assess deep research systems, with results showing that Gemini-2.5-Pro achieves the highest average score of 8.51 across all dimensions, indicating superior performance in coverage, insight, and instruction-following. The evaluation reveals a consistent gap between general and task-specific scores, highlighting that current systems often fail to meet task-specific criteria despite excelling in broad synthesis.
